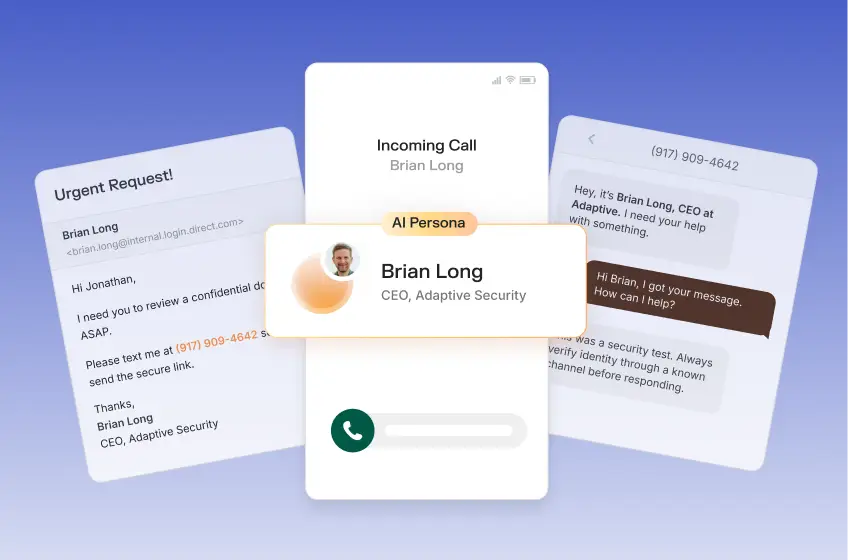
How to detect AI deepfakes is now a core security competency for every employee, one that has moved well beyond niche forensic analysis into frontline business risk management. When an Arup employee authorized a $25 million wire transfer after a convincing deepfake video call in 2024, the cyberattack succeeded because no one on the call recognized the signals that would have identified the participants as synthetic.
Deepfake fraud incidents grew fourfold year over year, according to the Sumsub Identity Fraud Report 2024, continuing a tenfold surge the prior year, bringing cumulative growth to 40 times over two years.
The detection methods that worked against earlier generative adversarial network (GAN)-based fakes are losing ground as diffusion models produce increasingly photorealistic output.
Understanding where current AI models still fail to render hands, eye movements, and audio-lip synchronization gives security teams the diagnostic edge that detection tools alone cannot provide.
According to the Verizon Data Breach Investigations Report 2026, 62% of confirmed breaches involve a human element, which makes closing the deepfake recognition gap a direct business risk priority for any organization with executives who appear in public media
This reality drives the case for embedding deepfake detection skills inside structured cybersecurity awareness training programs, where employees encounter realistic scenarios.
This guide provides security teams with a structured, step-by-step framework for detecting AI deepfakes across video, audio, and image formats, covering visual inconsistencies, audio artifacts, live-call verification techniques, and the organizational controls that turn individual awareness into a scalable defense.
Explore Adaptive Security's cybersecurity awareness training resources to stay ahead of the latest synthetic media cyber threats.
What Is a Deepfake and Why Detection Is Getting Harder
A deepfake is AI-generated synthetic media, whether video, audio, or images, produced using generative adversarial networks (GANs) or diffusion models to fabricate realistic portrayals of people.
Unlike a "cheapfake," which relies on basic editing tools such as speed manipulation or out-of-context clips, a deepfake uses trained neural networks to synthesize entirely new content that mimics a person's appearance, voice, or mannerisms with statistical plausibility.
That distinction matters for security teams: cheapfakes are detectable with critical thinking, while deepfakes are engineered to defeat it, and the two demand fundamentally different detection frameworks.

How GANs and Diffusion Models Generate Synthetic Media
The two dominant architectures behind today's deepfakes operate through fundamentally different mechanisms, and understanding both shapes how to detect AI deepfakes reliably.
GANs pit two neural networks against each other: a generator that fabricates synthetic content and a discriminator that attempts to distinguish real from fake. The generator improves by studying the discriminator's failures, producing fast, coherent media that leave statistical fingerprints in frequency spectra and facial landmark patterns, fingerprints that early detection tools exploited effectively.
Diffusion models take a different path. They begin with random noise and progressively denoise it, guided by training data, until a photorealistic output emerges. This process generates finer texture detail and fewer spatial artifacts than first-generation deepfakes.
A 2025 study titled 'Characterizing Photorealism and Artifacts in Diffusion Model-Generated Images' noted that detection classifiers trained on GAN artifacts fail to generalize to diffusion model outputs because the generative signatures differ structurally.
Why Detection Is Losing Ground Against Each New Model Generation
Detection is getting harder because the feedback loop is asymmetric: each failure exposes a new gap that model training absorbs, while detection methods can only catch up after the fact.
Each time a detection method identifies a failure pattern, such as misaligned eyes, irregular pupil shapes, or inconsistent corneal reflections, that signal gets absorbed into the next model training cycle, immunizing newer models against that specific detection indicator.
Cozzolino et al. (2024) demonstrated in 'Raising the Bar of AI-generated Image Detection with CLIP,' published at the CVPR 2024 Workshop on Media Forensics, that simple image modifications such as cropping and compression degrade detection accuracy.
This arms race compounds organizational cyber threat risk: the visual cues that worked two years ago no longer reliably work today. Employees trained to spot GAN artifacts are now facing deepfake phishing simulations built on diffusion models that produce entirely different error signatures.
That shift in cyberattack infrastructure is exactly why identifying which visual signals still betray modern deepfakes matters more than ever.
1. Examine the Face, Eyes, and Skin for Inconsistencies
Knowing how to detect AI deepfakes begins with the face, specifically the eyes, skin texture, and facial boundaries, where generative models fail most visibly. Scrutinizing blinking patterns, skin uniformity, and the edges where the face meets the hair, neck, and ear surfaces are the most reliable early signals available to any observer.
Extending that same attention to peripheral anatomy, including hands, fingers, teeth, and jewelry, exposes rendering gaps that the face region alone may hide. When something looks slightly wrong in these areas, treating it as a signal worth investigating before acting on any request is the correct response.

Observe Eye Behavior and Iris Rendering First
The eyes are the most revealing region in a deepfake. As MIT Media Lab's Detect Fakes research project documents, deepfake subjects frequently blink at irregular intervals, either too infrequently, too frequently, or in a mechanically uniform rhythm no real person replicates.
Beyond blink timing, examining the iris itself reveals AI-rendered eyes that often appear glassy, slightly unfocused, or asymmetric between the left and right eyes. Catchlights, the small reflections of light sources visible in real eyes, frequently appear inconsistent or mismatched between the eyes, a physics error that no real camera produces.
Read the Skin and Facial Boundaries
Face-swap models are trained predominantly on forward-facing, neutral-expression images, and that training bias has predictable consequences. Skin in a deepfake often appears over-smoothed, with unnaturally uniform pore distribution and a subtle plastic quality, or pixelation concentrated at the hairline.
The boundary between the synthetic face and the neck and ears is where blending artifacts tend to concentrate, particularly when the subject turns their head or shifts their expression sharply. Extreme expressions and steep profile-view angles expose the same rendering gap, because the model was never trained on that pose, and geometry distorts at the edges.
Check Hands, Fingers, Teeth, and Jewelry
Three anatomical zones remain persistent failure points across every current generation of face-swap and video synthesis models:
- Fingers merge together or multiply past five;
- Teeth render as a single fused surface rather than individual structures;
- Jewelry, including rings, earrings, and necklaces, warps or duplicates at the points where it meets skin.
These regions fall outside the face-centric training data most models use, so the errors are structural rather than incidental.
Use Frame-by-Frame Video Analysis
At normal playback speed, blending artifacts at the face boundary are nearly imperceptible. Pausing video at one-frame intervals inside any standard video editing application, or using a media player with frame-step functionality, surfaces seam lines, texture inconsistencies, and geometry distortions that disappear in motion.
A legitimate face maintains structural continuity across every single frame, while a deepfake face shows micro-inconsistencies at frame boundaries that accumulate into visible artifacts under frame-by-frame scrutiny.
Lighting and shadow behavior across the face, which vary independently of the background in AI-generated content, are the next signal to examine and reveal a different category of failure altogether.
2. Check Lighting, Shadows, and Background Coherence
Detecting AI deepfakes through environmental consistency requires examining the relationship between the subject's lighting and the surrounding scene: shadow direction, specular highlights, luminance gradients at facial boundaries, and background pixel behavior near moving features.
Starting at the edges of the face and working outward, comparing the light source implied by the subject with the light source visible in the background surfaces is the most reliable environmental cue. When those two sources are physically inconsistent, the image or video is a strong candidate for synthetic manipulation.
How Do Shadow Directions Reveal a Deepfake?
Lighting direction is the most reliable environmental signal in deepfake detection. In a real image or video, shadows on the face and shadows in the background all point away from the same light source.
In deepfakes, AI compositing stitches a synthetically generated face onto a real or separately generated background where the two environments were lit independently, and a shadow falling left on the subject's chin while background objects cast shadows to the right is a definitive physical impossibility in an authentic image.
Specular highlights are equally revealing. A matte skin surface should carry no mirror-like reflections, while a shiny one should carry them at a predictable angle relative to the light source.
A 2025 study titled 'Deepfake Media Forensics: Status and Future Challenges,' published in the Journal of Imaging, found that forensic approaches specifically target unnatural lighting and shadow anomalies as core spatial inconsistencies introduced when generative algorithms fail to maintain coherent lighting across a manipulated face.
How Does Luminance Gradient Analysis Expose Compositing Errors?
Luminance gradient analysis measures how brightness transitions across an edge. In a real photograph or video frame, a face lit by a single environment produces a gradual, physically predictable shift in brightness at its boundary with the background.
When the gradient at that edge is physically inconsistent with a single light environment, the image reveals that the face and background were captured or generated under different lighting conditions.
Practitioners can approximate this analysis without specialized software. A visible halo or brightness mismatch along the subject's outline, particularly around the hairline and neck, is the visual equivalent of a luminance gradient anomaly.
Deepfake compositing frequently leaves this artifact because blending algorithms optimize for visual realism at the face rather than for physical accuracy at the boundary.
What Does Background Warping Indicate in Deepfake Video?
In authentic footage, the background remains geometrically stable relative to the camera, while in deepfakes, the computational load of tracking and re-rendering the face in each frame frequently introduces background warping near active facial regions, particularly around the jaw, temples, and mouth.
Straight lines in wallpapers, door frames, or bookshelves will appear to curve or stutter as the face moves.
Pixel drift, where background pixels appear to shift or ripple outward from the face, is especially common in lower-quality deepfakes and in real-time video calls where processing speed forces quality trade-offs.
Slowing the video to single-frame review and watching the 10 to 15 pixels surrounding the face boundary throughout a speaking sequence clearly reveals this artifact.
How Does Color Temperature Mismatch Signal a Deepfake?
Color temperature is the warmth or coolness of light, measured in Kelvin, with warm indoor lighting around 2700K and cool daylight around 6500K.
A subject and their environment, filmed under the same light, share the same color temperature: skin tones, wall colors, and object tints all carry the same warm or cool cast.
In composited deepfakes, the subject's face often has a different color temperature from the surrounding scene, producing a face rendered in warm tones set against a cool-lit background, or the reverse.
This mismatch is visible to the naked eye as a subtle color cast difference between the subject and their surroundings, as if the subject is standing in a different room. Identifying this inconsistency confirms compositing and completes the environmental analysis layer.
Visual artifacts in the environment represent one detection layer; the synthetic voice introduces a separate class of detectable flaws that a trained listener can learn to recognize.
3. Listen for Audio Artifacts and Lip-Sync Mismatches
How to detect AI deepfakes through audio requires recognizing the distinct distortions that voice synthesis and audio cloning introduce, then cross-referencing what is heard against what appears on screen.
Identifying flat or monotone cadence, unnatural breath patterns, and audio clipping, then assessing whether mouth movements match spoken words in real time, builds the multi-signal approach audio deepfakes demand.
Audio-only cyberattacks lack a visual channel, making them harder to detect without deliberate verification steps. Any request for urgent financial action delivered by phone or video should require independent second-channel confirmation, regardless of how convincing the voice sounds.
Identify Auditory Distortions in the Voice
AI-synthesized voices carry a recognizable fingerprint once an observer knows what to hear. Emotional cadence in cloned audio tends to be flat, then abruptly spikes: the voice sounds composed during a complex sentence and suddenly intense mid-phrase, with no natural buildup.
Swallowed consonants, compressed breath cycles, and a faint metallic resonance in the midrange are all consistent artifacts of current synthesis models.
Audio clipping is also an indicator. A deepfake voice track often mismatches the ambient environment: the voice sounds studio-clean while the visual setting shows a noisy office, or background hiss appears and disappears with no environmental explanation.
Check Lip-Sync Against Phoneme Rendering
Bilabial sounds, the "p," "b," and "m" phonemes that require full lip closure, are where synthesis models break most visibly, with the mouth shape either closing too slowly, not fully, or not at all relative to the spoken sound.
Looking beyond the lips is equally important. The corners of the mouth often lag behind the jaw during fast speech, tongue visibility during open-vowel sounds is frequently absent or anatomically implausible, and dental rendering, how teeth appear during hard consonants, is blurry or inconsistent frame-to-frame in most current models.
Recognize the Cyber Threat of Audio-Only Voice Cloning
Audio-only deepfakes eliminate the visual channel entirely, removing lip-sync as a detection layer. These cyberattacks drive vishing and financial fraud at scale.
The Arup incident demonstrated that a finance employee joining a video call in which every participant is a deepfake will, without proper verification protocols, approve a wire transfer based solely on audio and visual cues.
Caller ID, a familiar voice, and a plausible scenario are no longer sufficient grounds for authorizing a financial transaction. Any executive with a recorded earnings call, conference presentation, or published interview is a viable target for cloning.
A study published in Scientific Reports (2025) titled 'People Are Poorly Equipped to Detect AI-Powered Voice Clones' found that human participants correctly identified a voice as AI-generated only about 60% of the time and perceived an AI-generated voice as matching its real counterpart roughly 80% of the time, confirming that the human ear is an unreliable gatekeeper against current voice cloning technology.
When audio cues alone cannot confirm identity, the next detection layer is metadata- and tool-based verification, examining file- and platform-level signals that the human ear cannot access.
4. Use Detection Tools, Metadata Analysis, and Reverse Search
How to detect AI deepfakes at a technical level requires layering multiple verification methods: reverse search, metadata inspection, automated detection tools, and image forensics, because no single approach catches everything.
Each method targets a different failure point in the production or distribution of synthetic media. Starting with the fastest, lowest-friction techniques and escalating to more sophisticated forensic tools when a file warrants deeper scrutiny is the correct sequence. Any single clean result is a data point rather than a verdict.
How Does Reverse Image or Video Search Help Detect Deepfakes?
Reverse search locates the original source of a clip and flags whether footage has been re-used, decontextualized, or lifted from an unrelated event.
For images, uploading directly to Google Images or TinEye is the starting point. For video, the InVID/WeVerify browser plugin, available free for Chrome and Firefox, breaks footage into keyframes and runs each frame through multiple reverse-image engines simultaneously. A mismatch between the claimed source and the search results is a direct indicator of manipulation.
What Does File Metadata Reveal About Deepfake Tampering?
File metadata contains creation date, device model, GPS coordinates, and editing software, all recorded automatically at the time of capture. Metadata that has been scrubbed entirely, or that lists a professional camera model while the file was actually modified in video-editing software, signals tampering.
Emerging authentication standards reinforce this layer: the C2PA standard, backed by Adobe, Microsoft, Google, and over 200 member organizations, attaches a cryptographically signed content credential to media at the time of creation, enabling downstream verification of the complete edit history.
When C2PA credentials are absent on content claiming to be from a credentialed source, that absence is itself a red flag.
Which Automated Deepfake Detection Tools Are Most Effective?
Automated platforms apply trained AI models to detect artifacts in audio, video, and imagery. Available options include Microsoft Video Authenticator, Deepware Scanner, Sensity AI, and Intel's FakeCatcher, which analyzes blood flow patterns in video frames rather than relying on GAN artifact signatures.
Accuracy varies significantly: Intel claims FakeCatcher achieves 96% accuracy in controlled settings, but real-world performance for commercial detectors drops to the 78-87% range across video and image when content compression, re-encoding, and novel generation methods are in the mix.
Current AI detectors perform materially better against GAN-generated content than against diffusion-model outputs, which tend to produce fewer pixel-level artifacts these tools were trained to flag.
How Does Error Level Analysis Detect Image Manipulation?
Error level analysis (ELA) is a forensic technique that re-saves a JPEG at a known compression level and measures where the resulting error distribution is uneven.
Authentic, unmodified images compress uniformly, while edited or composited regions, where a face has been grafted or a background replaced, compress at different rates and appear as brighter zones in the ELA output.
FotoForensics offers free ELA processing directly in the browser without requiring software installation. ELA does not work on PNG or video files and is less reliable on images that have been heavily compressed multiple times, so it functions best as a supporting signal alongside metadata and reverse search rather than a standalone verdict.
No combination of tools can eliminate uncertainty entirely, and synthetic media used in professional fraud operations can defeat each method in isolation. The reliable approach pairs technical verification with careful visual inspection: together, these layers produce results that no single technique can achieve on its own, and the same discipline that applies to recorded media becomes even more demanding in real-time video calls.
5. How to Detect AI Deepfakes During Live Video Calls
How to detect AI deepfakes in real time is harder than analyzing a recorded video frame by frame: live calls offer no replay, and cyberattackers count on the pressure of the moment to override instincts.
The core approach combines physical stress tests that overwhelm face-swap rendering engines with protocol-based verification that removes trust from the visual channel entirely.
Routing any sensitive request through an independent, pre-verified communication channel immediately is not optional. No single check is definitive; the protocol works because it layers friction that AI rendering pipelines cannot absorb simultaneously.

How Do Extreme Head Angles Expose a Live Deepfake?
Asking the person on the call to turn their head sharply to the side or tilt to a near-profile angle stresses the most common failure point in live face-swap systems.
Most face-swap and face-reenactment models are trained predominantly on frontal and near-frontal views, so extreme angles cause visible texture warping, edge tearing, or the face losing coherence against the neck and background.
Following up by asking for a specific, unexpected number of fingers held up adds a second layer of stress. Real-time hand rendering remains computationally expensive for AI systems, and fingers frequently appear blurred, fused, or incorrect in count under live processing load.
What Rendering Artifacts Distinguish a Live AI Deepfake from a Real Video Call?
Live face-swap filters introduce a predictable set of visual artifacts that static deepfakes do not.
Three artifact classes signal a live compositing layer under stress. Frame stuttering or brief freeze-and-catch moments correlate with processing spikes. A facial float effect causes features to appear to sit slightly in front of the head rather than on it. Background elements near the face boundary smear or bleed color during fast head movement.
Eye gaze that locks forward and does not track naturally to objects on the side of the screen confirms a compositing layer is present, since maintaining consistent forward gaze is computationally easier for current systems than dynamic tracking.
How Does a Safe Word or Pre-Agreed Verification Sequence Stop Voice-Cloning Scams?
For personal and family use, a pre-agreed code word or private question that only the genuine person could answer creates a low-tech but effective barrier against voice-cloning scams.
The verification question should be something that cannot be derived from social media or public records: a shared memory, a private nickname, or a specific detail from a past conversation. This protocol works precisely because AI impersonation models are trained on public data and cannot reconstruct genuinely private knowledge.
Why Must Call-Back Verification Happen Before Any Sensitive Action Is Taken?
Organizations should treat any financial or operationally sensitive request made over video or phone as unverified until confirmed through an independent channel. Ending the call and dialing back a number from the organization's verified directory, rather than the number provided during the suspicious call, is the minimum required response before any action is taken.
The verification step must happen before action, not after suspicion is raised. Phishing simulations that include live deepfake video scenarios train employees to apply this discipline under realistic pressure.
Once employees can apply these live-call checks, the next layer of defense moves from individual skill to institutional policy, building the organizational controls that make detection systematic rather than reactive.
How to Detect AI Deepfakes at the Organizational Level
Defending against deepfake fraud requires security and IT leaders to move beyond individual detection skills and build institutional controls: multi-channel verification protocols, Zero Trust Media policies, biometric authentication hardening, and proactive exposure reduction.
No digital communication should be treated as trusted by default without independent verification; the organizational posture must assume synthetic content is possible on any channel.
Enforce Multi-Channel Verification for High-Risk Actions
No wire transfer, credential change, or sensitive operational decision should be authorized based on a single communication channel. A voice call requesting an urgent payment, even from a number matching a CFO's direct line, must be confirmed through a second independent channel before execution.

Adopt a Zero Trust Media Posture
Zero Trust Media is an emerging operational posture, adapted from the Zero Trust security framework, that extends the principle of 'never trust, always verify' to all digital communications, treating them as unverified by default until provenance is confirmed.
Practically, this means policies requiring that high-value requests initiated via audio or video be authenticated through an out-of-band channel that a cyberattacker cannot intercept or replicate.
Policy design should define which request types trigger mandatory verification and establish pre-shared code words or callback procedures for transactions above defined thresholds.
Harden Biometric Authentication Against Synthetic Injection
Face-liveness checks and voice-print authentication, widely used by banks and identity verification providers, are increasingly vulnerable to synthetic media injection attacks, in which AI-generated faces and cloned voices are fed directly into the verification stream.
Organizations relying on biometrics as a sole authentication factor should layer in behavioral signals, device attestation, or hardware-bound credentials to reduce that single point of failure.
Account for Deepfake-as-a-Service in the Cyber Threat Model
Cybercrime-as-a-service (CaaS) platforms now package deepfake generation, open-source intelligence (OSINT) profiling, and delivery infrastructure into subscription offerings accessible to non-technical cyberattackers.
The barrier to launching a sophisticated executive impersonation campaign has dropped from months of technical work to a matter of days and a low-cost service subscription. The IBM Cost of a Data Breach Report 2025 places the average breach cost at $4.44 million per incident, and a single successful deepfake fraud event can exceed that figure entirely on its own.
Reduce the Organization's Biometric Attack Surface
Publicly accessible audio and video give cyberattackers the raw material for replicating voices and faces. Open-source intelligence (OSINT), meaning data gathered from earnings calls, conference recordings, LinkedIn, YouTube, and media appearances, is what makes executive impersonation possible at scale.
Security teams should audit which executive content is publicly accessible and apply privacy settings across professional and social channels to reduce the available footprint for cloning.
Technical controls address the infrastructure layer, but cyberattackers specifically target the human layer because it is faster to manipulate than systems. Deepfake phishing simulations and vishing scenarios give employees direct exposure to what these cyberattacks look and sound like; genuine recognition is built through experience, and policy documents alone cannot create it.
Can Training Actually Make People Better at Detecting Deepfakes?
The answer, supported by multiple peer-reviewed studies, is yes, but only when training involves active exposure rather than passive familiarity. Detection accuracy improves measurably with structured priming, and the cognitive biases that make untrained observers vulnerable are specific and addressable.
A 2024 study published in Complexity from the University of Vermont found that individuals actively primed to look for deepfakes detected them at significantly higher rates than unprimed participants, who scored just 51% accuracy, essentially a coin flip.
Why Cognitive Bias Makes Untrained People Especially Vulnerable
Human bias is the primary reason why detecting AI deepfakes fails without training. People are measurably more likely to trust deepfakes featuring someone who resembles them, shares their political affiliation, or appears in content circulating through their social peer group.
The 2024 University of Vermont study directly confirmed this. Participants showed significant homophily bias, defined as a tendency to more readily identify deepfakes of individuals who matched their own demographic profile. Detection accuracy was significantly higher for deepfakes of people who resembled the participant.
Political deepfakes exploit a different but related mechanism. They are engineered for viral sharing rather than precision targeting, and succeed by triggering partisan credibility assumptions rather than exploiting organizational authority.
A finance team member trained to question a wire transfer request still needs a different mental framework to evaluate an AI-generated political video, because the cyber threat model, motivation, and psychological lever are distinct.
What the Liar's Dividend Means for Security Training
Deepfake proliferation creates a paradox that training programs must address directly. As synthetic media becomes ubiquitous, cybercriminals can dismiss any genuine evidence as fabricated, a phenomenon legal scholars call the "Liar's Dividend" (Chesney and Citron, 2019).
The risk runs both ways: employees fall for convincing fakes while simultaneously becoming skeptical of legitimate communications, eroding the institutional trust that makes organizations function.
Training content that builds deliberate skepticism as a habit, rather than blanket distrust, teaches employees to apply structured verification protocols to any high-stakes request regardless of format.
Why Passive Awareness Fails and Deepfake Phishing Simulation Succeeds
Insights from Facebook's Deepfake Detection Challenge, where no submitted model exceeded 70% accuracy on the holdout dataset and the top performer reached 65.18%, confirm that detection is genuinely hard and that passive familiarity with deepfake concepts cannot substitute for active, structured training.
Security awareness training is an iterative cycle of exposure, feedback, and calibration that must evolve as generation tools improve. That iterative loop is most valuable at the exact moment an employee decides whether the face on screen is real.
Why Deepfake Awareness Belongs Inside Every Security Training Program
Knowing how to detect AI deepfakes is no longer a niche technical skill; it belongs inside every organization's cybersecurity awareness training program because deepfakes now serve as the delivery mechanism for phishing, vishing, smishing, and business email compromise (BEC).
The human element is one of the most persistently exploited factors in breaches, and deepfakes represent a high-fidelity social-engineering vector that cyber threat actors can exploit.
Cybersecurity awareness training programs that ignore this gap do not close it. Organizations that embed deepfake recognition into every layer of the cybersecurity awareness training platform are now better positioned than those that wait for a confirmed fraud event to force the issue.

Why Email-Only Training Leaves Employees Exposed
Cybersecurity awareness training programs built exclusively around how to spot a phishing email no longer reflect the cyberattack surface employees face.
Cyber threat actors run coordinated, multi-channel campaigns: a spoofed email is followed by a vishing call using a cloned executive voice, confirmed by a deepfake video in a Slack or Teams message.
Each channel reinforces the others, and an employee who recognizes a suspicious email may still comply when the same request arrives in the form of a convincing video of their CEO. Detection skills must be trained across every channel where synthetic media appears, not just the inbox.
How Deepfake Phishing Simulation Converts Awareness Into Instinct
Exposing employees to synthetic voice calls, AI-generated video requests, and OSINT-personalized spear phishing scenarios in a controlled environment trains pattern recognition in ways that abstract security awareness training content cannot.
Deepfake phishing simulation performance, tied to human risk scoring, then identifies which employees and teams remain most susceptible, allowing security leaders to direct targeted remediation through the cybersecurity awareness training platform before a real cyberattack exploits those gaps.
What Compliance Frameworks Now Expect
SOC 2, HIPAA, and PCI DSS auditors increasingly require documented evidence that organizations train employees to defend against emerging social engineering cyber threats.
Security awareness training content tied to measurable outcomes from deepfake phishing simulations and completion records satisfies that evidentiary standard and demonstrates the proactive security posture auditors look for.
Organizations that treat deepfake literacy as a standalone topic rather than an integrated requirement will find both their people and their audit trails unprepared, a gap that becomes visible exactly when the pressure is highest.
See Whether Employees Can Spot a Deepfake Before Cyberattackers Do
Knowing how to detect AI deepfakes in theory and recognizing one under time pressure in an interaction are two different skills, and the gap between them is exactly where fraud succeeds.
Adaptive Security positions organizations to close that gap through outcome-focused cybersecurity awareness training that treats deepfake recognition as a practiced reflex rather than an abstract concept.
The cybersecurity awareness training platform delivers realistic deepfake phishing simulations across voice, video, and multi-channel scenarios, giving security leaders measurable data on which employees and teams remain most exposed.
The platform integrates deepfake phishing simulation directly into the training workflow, meaning security teams can assign targeted content, track completion, and monitor risk scores without toggling between separate systems.
Every deepfake scenario is updated as generation models evolve, so the phishing simulations employees encounter reflect current cyberattack techniques rather than last year's signatures.
Organizations that invest in deliberate, simulation-based cybersecurity awareness training against deepfake cyber threats today avoid the far costlier experience of building that capability in response to a confirmed fraud event.
Discover how Adaptive Security turns deepfake recognition into a measurable organizational capability by requesting a platform walkthrough today.
Key Takeaways
- How to detect AI deepfakes starts with the eyes: irregular blinking cadence, glassy iris rendering, and mismatched catchlights are the most consistent visual signals across both GAN and diffusion-model fakes;
- Lighting and shadow inconsistencies, including mismatched shadow directions, luminance gradient anomalies, and color temperature differences between subject and background, are definitive environmental signals of compositing;
- Cybersecurity awareness training that includes audio analysis closes the vishing gap: flat emotional cadence, swallowed consonants, and studio-clean audio in a noisy visual setting all indicate a synthetic voice;
- Frame-by-frame video review and live stress-tests, such as requesting extreme head angles or unexpected hand gestures, are the most reliable methods for detecting AI deepfakes in recorded and live-call contexts, respectively;
- Metadata inspection, reverse image search, and error level analysis layer technical verification on top of visual assessment, producing results that no individual tool or technique can replicate on its own;
- Organizational controls, including multi-channel verification, Zero Trust Media policies, and biometric authentication hardening, address the cyber threat at the institutional level rather than relying solely on individual employee judgment;
- Cybersecurity awareness training that incorporates deepfake phishing simulations builds the pattern recognition that passive media literacy cannot, because detection skill is built through exposure and feedback rather than reading alone;
- Deepfake-as-a-Service platforms have lowered the barrier to sophisticated executive impersonation campaigns from months of technical work to days and a low-cost subscription, making employee security awareness training an urgent risk-reduction priority rather than a future consideration;
- How to detect AI deepfakes across image, video, and audio modalities requires distinct techniques for each format; a unified multi-layer approach combining human inspection with automated tools and behavioral challenges delivers the most defensible outcome;
- Compliance frameworks, including SOC 2, HIPAA, and PCI DSS, now expect documented evidence of cybersecurity awareness training against emerging social engineering cyber threats, making deepfake literacy a regulatory requirement as well as a security one.
Frequently Asked Questions About AI Deepfake Detection
How Accurate Are AI-Powered Deepfake Detection Tools, and What Is Their False Positive Rate?
AI-powered deepfake detection tools achieve high accuracy on controlled benchmarks but perform inconsistently in real-world conditions, with false-positive rates that vary significantly by tool, media type, and generation method.
Tools trained on GAN-produced content often struggle with diffusion-model outputs, with reported benchmark accuracy dropping by 20 percentage points or more when applied to out-of-distribution samples.
False positives carry real consequences: research from the University at Buffalo (2024) found that existing deepfake detection algorithms misclassified real faces as fake 39.1% of the time for Black men, compared to 15.6% for white women, exposing embedded bias that undermines reliability.
A multi-layer approach that combines automated detection, metadata analysis, and human verification yields the most defensible outcome.
How Quickly Can a Convincing Deepfake Voice Clone Be Made From Publicly Available Audio?
McAfee research published in 2023 (titled 'Artificial Imposters: Cybercriminals Turn to AI Voice Cloning for a New Breed of Scam') found that three seconds of clear audio are sufficient for modern generative models to capture vocal timbre, cadence, and emotional tone well enough to deceive listeners in real-time calls.
Subscription-based voice cloning services handle the synthesis automatically, putting this capability within reach of non-technical cyberattackers.
What Legal Recourse Is Available to Victims of a Malicious Deepfake?
Legal recourse for deepfake victims exists but remains fragmented, jurisdiction-dependent, and difficult to enforce.
In the U.S., more than 40 states have enacted laws addressing specific categories of harmful deepfakes, according to tracking maintained by the National Conference of State Legislatures. The federal TAKE IT DOWN Act targets non-consensual intimate imagery, requiring platform removal within 48 hours of notice.
For financial fraud involving deepfakes, existing wire fraud statutes and identity theft laws apply, and victims should file complaints with the FBI's Internet Crime Complaint Center (IC3) and the FTC.
Civil claims including defamation, misappropriation of likeness, and intentional infliction of emotional distress are available in many jurisdictions, though proving damages and identifying anonymous perpetrators remain practical barriers.
How Do Social Media Platforms Currently Identify and Label AI-Generated Deepfake Content?
Social media platforms use a combination of automated signal detection, user disclosure requirements, and manual review to identify and label AI-generated content, though coverage remains inconsistent.
Meta announced in April 2024 that it would label video, audio, and images as "Made with AI" when its systems detect standard AI provenance signals or when users self-disclose.
YouTube requires creators to disclose realistic AI-generated content in certain categories, including news and election topics, and TikTok applies AI labels to content it detects as synthetic.
The core limitation is detection dependency: content that lacks embedded provenance signals and is uploaded without disclosure often escapes labeling entirely. Researchers at The Dais (2025) concluded that current platform labeling approaches are not working at the scale or reliability needed to meaningfully reduce public deception.
What Is the Difference Between Detecting a Deepfake Image, a Deepfake Video, and Deepfake Audio, and Does the Approach Change for Each?
Detecting a deepfake image, video, or audio requires distinct techniques because each modality introduces different artifact signatures and offers different verification channels.
Deepfake images exhibit spatial artifacts: over-smoothed skin texture, asymmetric iris rendering, distorted hands and fingers, and lighting inconsistencies between the subject and background. Error level analysis (ELA) using tools like FotoForensics can expose regions with inconsistent compression, a reliable sign of compositing.
Deepfake videos extend image-level artifacts over time and introduce temporal inconsistencies: unnatural blinking cadence, flickering facial boundaries during head movement, and background warping near the face.
Frame-by-frame analysis at 1-frame intervals in video editing software reveals blending artifacts invisible at normal playback speed.
Deepfake audio has no visual channel to cross-reference. Detection relies on spectral analysis for unnatural tonal uniformity, irregular breath cadence and unnatural pauses, and absence of environmental acoustics consistent with the claimed setting.
Voice clones frequently exhibit a flat emotional arc with abrupt shifts in energy that trained listeners can identify. For all three modalities, multi-layer verification that combines technical tools, metadata inspection, and behavioral challenges yields more reliable outcomes than any single method.
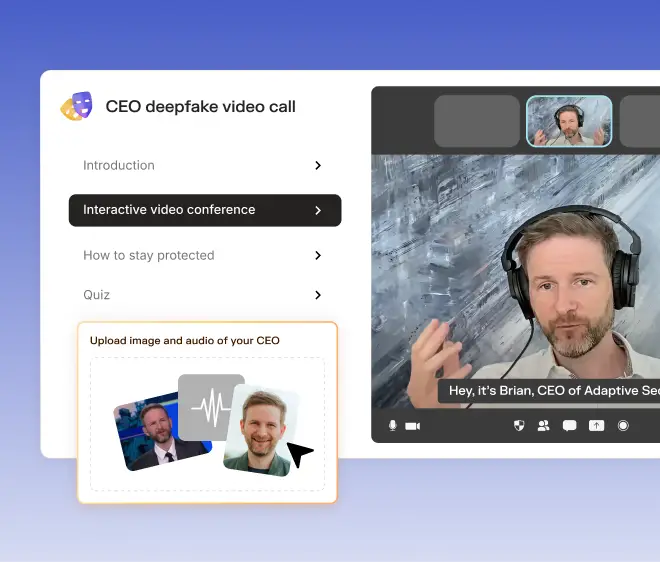

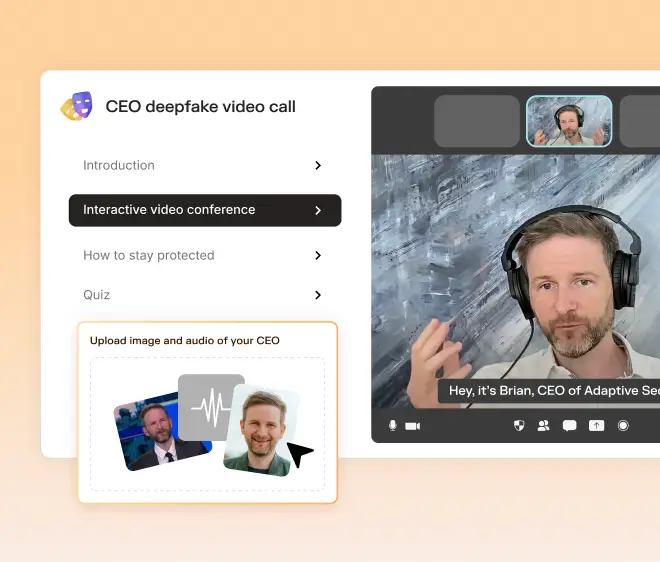
As experts in cybersecurity insights and AI threat analysis, the Adaptive Security Team is sharing its expertise with organizations.
Contents