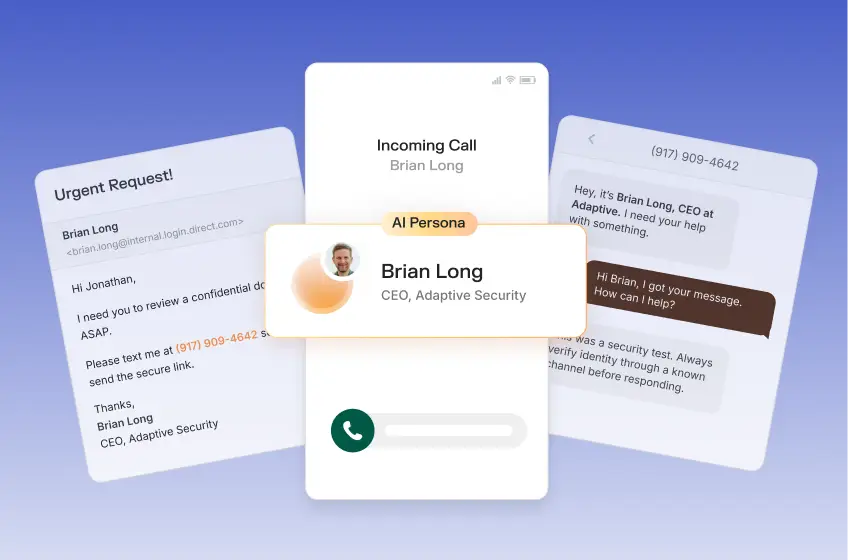
Challenges defending against AI deepfakes reveal a structural gap that technology alone cannot close. Detection tools lose nearly half their accuracy in real-world deployments while cyberattackers exploit publicly available data to build impersonations that cost organizations millions per incident.
This article examines the full scope of the deepfake defense problem, including how cyberattackers harvest open-source intelligence (OSINT) to turn an executive's social media presence into an attack surface, the financial and psychological toll synthetic media imposes, and the multi-layered defense framework that combines awareness training, verification protocols, and detection tools into a coherent strategy.
Organizations that build human vigilance alongside technical controls create an adaptive defense that detection algorithms, however advanced, cannot replicate on their own. Meeting the challenges of defending against AI deepfakes requires a combination of human judgment and a layered process.
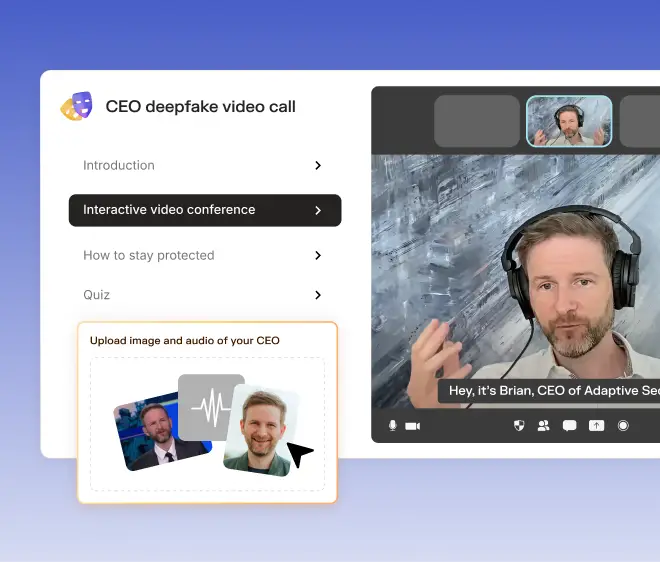
Adaptive Security delivers security awareness training built for the AI deepfake era, combining multi-channel phishing simulation, OSINT-personalized scenarios, and verification protocol coaching that legacy training programs were never designed to address. Take a self-guided tour of the Adaptive Security platform to see how realistic deepfake simulations turn employees into an adaptive layer of defense.
The Explosion of Deepfake Attacks: Scale, Velocity, and Driving Forces
Deepfake cyberattack volume has reached an inflection point no security team can afford to ignore. This is the weaponization of generative AI at industrial scale, and the velocity has outstripped every defensive capability organizations currently have deployed.
The fundamental driver is the collapse of the barrier to entry for cyberattackers, who now require zero coding skills, minimal audio samples, and a few dollars to launch a campaign capable of defrauding an enterprise out of millions. This shift is central to the challenges security leaders now face in defending against AI deepfakes.

Incident Growth by the Numbers
The raw figures describing the deepfake threat landscape have become difficult to internalize precisely because they are so extreme. Between 2022 and 2023, North America experienced a 1,740% increase in deepfake fraud attempts, while the Asia-Pacific region recorded a 1,530% surge during the same period, according to Sumsub's analysis of fraud data across its global verification network. Both figures indicate that deepfake-enabled crime moved from an edge-case curiosity to a mainstream attack vector in roughly 18 months.
The financial toll has kept pace. During the first half of 2025 alone, deepfake-related fraud losses exceeded $410 million globally, surpassing the $359 million lost during all of 2024, according to Surfshark's analysis of deepfake fraud financial data.
A Regula survey found that 49% of organizations globally reported encountering audio or video deepfake fraud in 2024, up from 37% for audio and 29% for video just two years earlier.
Behind those aggregate figures sits a velocity problem unprecedented in cybersecurity. In 2024, a deepfake cyberattack was attempted every five minutes, according to Entrust's 2025 Identity Fraud Report. The cyberattack tempo has not plateaued, and every indicator, from fraud attempt frequency to total file volume to cross-industry encounter rates, points to continued acceleration through 2026.
What's Driving the Surge
Three converging forces explain why deepfake cyberattacks have exploded rather than grown gradually. The first is the democratization of creation tools. Building a convincing deepfake in 2020 required technical expertise, expensive GPU infrastructure, and days of model training; in 2026, it costs a few dollars and takes minutes. Off-the-shelf platforms for voice cloning and face-swap tools available through open-source repositories have eliminated nearly every technical barrier.
The second force is the compression of the cyberattack development cycle. Threat actors no longer need weeks of open-source intelligence (OSINT) gathering and tool configuration. Voice cloning now requires as little as ten seconds of source audio to produce a clone convincing enough to fool colleagues and bypass voice-based authentication, according to the OWASP Guide for Preparing and Responding to Deepfake Events published in 2024.
That audio is trivially scraped from earnings calls, conference talks, podcast appearances, and social media videos, all publicly available, and a convincing synthetic video can now be produced in approximately 45 minutes using free software.
The third force is asymmetric economics. Deepfake fraud offers exceptionally high return on investment: a campaign costing under $100 to execute can yield hundreds of thousands of dollars when successful. This payoff structure attracts both organized crime groups and individual operators, creating a self-reinforcing cycle where more cyberattackers enter the market, more tools are developed to serve them, and the barrier to entry drops further with each iteration.
Attack Surface Expansion
Deepfake cyberattacks are no longer confined to a single channel. In 2022, the typical deepfake fraud scenario involved a voice call: a cloned CEO voice instructing a finance employee to authorize a transfer. By 2025, cyberattack campaigns will be operated across five channels simultaneously: email, voice, SMS, video conferencing, and social media.
This multi-channel expansion is a core challenge in defending against AI deepfakes in practice. A finance team member might receive a seemingly legitimate vendor invoice via email, followed minutes later by a vishing call from a synthetic clone of the CFO's voice confirming urgency, and then a WhatsApp message with a deepfaked video snippet reinforcing the request.
Each channel validates the others, overwhelming the target's skepticism. Cyberattackers have learned that a single-channel deepfake can be dismissed as odd, while a three-channel campaign feels authentic.
Social media has emerged as both a goldmine for reconnaissance and a direct attack surface. LinkedIn profiles, Instagram stories, and TikTok videos provide high-quality source material for cloning voices and faces. Cyberattackers also use social platforms to deliver deepfake content directly, impersonating executives in video posts or sending synthetic voice messages through platform messaging tools.
The uncomfortable reality is that detection tools have not kept pace with this velocity. Academic research has shown that state-of-the-art deepfake detectors lose up to 50% of their accuracy when tested against real-world deepfakes not present in their training data, while deepfake creation tools continue to advance at the pace of the underlying generative models.
Organizations betting solely on detection technology are making a losing wager, and what makes the gap especially dangerous is the industrial efficiency with which these synthetic media assets are now produced.
How Deepfakes Are Created: GANs, Autoencoders, and the Taxonomy of Synthetic Media
Deepfakes are AI-generated synthetic media that use deep learning to convincingly replace a person's likeness or voice in video, audio, or images. The technology relies on neural networks trained on real footage of the target individual, drawn from conference talks, earnings calls, and social media posts, producing outputs increasingly indistinguishable from authentic recordings.
While the term entered public consciousness through nonconsensual pornography, the same architectures now power real-time executive impersonation during live video calls and biometric spoofing attacks that bypass facial recognition systems.
How Do GANs and Autoencoders Generate Convincing Deepfakes?
Every deepfake begins with a neural network trained to understand what a specific human face or voice looks and sounds like from multiple angles and emotional states. The two architectures that dominate deepfake generation are generative adversarial networks (GANs) and autoencoders, each solving the impersonation problem differently.
GANs work through adversarial competition between two neural networks locked in a zero-sum game. The generator produces synthetic images, while the discriminator attempts to distinguish them from real photographs of the same person. Every time the discriminator catches a fake, the generator adjusts its parameters and tries again.
Over thousands or millions of iterations, the generator learns to produce outputs the discriminator can no longer classify above random chance, resulting in a model that generates faces the human eye cannot distinguish from real photographs.
Modern GANs have been superseded by diffusion models, the technology behind DALL-E and Midjourney, which generate images by iteratively denoising random pixels into photorealistic outputs, achieving even higher fidelity with fewer artifacts than GANs could manage even three years ago.
Autoencoders take a different approach and remain the backbone of face-swapping. An autoencoder consists of an encoder that compresses an image into a compact latent representation and a decoder that reconstructs the image from that compressed form.
Face-swapping cyberattacks train a shared encoder on thousands of frames of two different people but train two separate decoders, one for each face. When the cyberattacker feeds their own face into the encoder but routes the latent representation through the target's decoder, the output is a video of the cyberattacker performing the target's exact facial movements and expressions.
This architecture powered the first wave of convincing deepfake pornography and remains widely used because it requires less training data than GANs.
The leap in output quality since 2020 is driven by three compounding factors: an exponential increase in available training data from public social media profiles and conference recordings, the commoditization of high-performance GPUs and cloud compute, and the emergence of open-source models that eliminated the expertise barrier.
In 2020, producing a convincing deepfake required a skilled machine learning engineer and weeks of training; a cyberattacker can now generate a photorealistic face swap in under an hour using consumer-grade tools.
What Are the Different Types of Deepfakes?
Not all synthetic media cyberattacks are created equal, and treating them as a monolith guarantees detection gaps. Security teams need a working taxonomy that distinguishes three tiers of synthetic media based on creation method, attack surface, and the detection approach each demands. Understanding this taxonomy is essential to addressing the broader challenges of defending against AI deepfakes across an organization.
- Cheapfakes are low-effort manipulations that require no machine learning, such as a video slowed to 75% speed to make a politician appear intoxicated, a genuine photo recaptioned with a fabricated quote, or audio clipped mid-sentence to reverse the meaning of a statement;
- Full deepfakes occupy the middle tier: GAN-generated or autoencoder-generated face swaps and diffusion-model voice clones produced offline, typically requiring hours or days of preparation;
- Puppet master attacks represent the most dangerous tier: real-time facial reenactment during live video calls, where the cyberattacker's facial movements drive a synthetic overlay of the target executive rendered frame-by-frame with minimal latency.
Cheapfakes exploit context collapse, the human tendency to trust media that appears on a familiar platform, rather than technical sophistication. Detection relies almost entirely on human judgment and media literacy: checking original sources, verifying timestamps, and recognizing that the most inflammatory clips are often the most manipulated. No AI detection tool catches a cheapfake because there is no AI-generated signal to detect.
Full deepfakes involve a cyberattacker who harvests open-source intelligence (OSINT) from earnings call recordings, LinkedIn videos, and podcast appearances, trains a model, and deploys the synthetic asset in a targeted spear phishing or business email compromise (BEC) campaign.
Deepfakes dominate celebrity investment scams, in which an AI-generated Elon Musk or Warren Buffett promotes fraudulent cryptocurrency schemes. Detection at this tier combines forensic analysis with behavioral verification protocols, since the synthetic asset exists as a file prior to the cyberattack, creating a window for detection before the payload reaches the target.
Puppet master attacks defeat both forensic detection tools, because there is no file to scan, and standard identity verification, because the face and voice match the expected individual. The only effective countermeasure is an out-of-band verification protocol that confirms high-risk requests through a second trusted channel.
Where Do Deepfakes Cause the Most Damage?
The dollar impact of deepfake-enabled fraud segments into four primary categories, each exploiting a different trust vector.
- Celebrity investment scams use AI-generated endorsements from public figures to promote fraudulent cryptocurrency, fake stock tips, and nonexistent products;
- Corporate impersonation targets finance and accounting teams with synthetic CFOs or CEOs requesting wire transfers, vendor payments, or credential resets;
- Biometric spoofing for KYC bypass weaponizes synthetic faces against identity verification systems;
- Romance scams use synthetic video calls to build fraudulent romantic relationships over weeks or months, eventually extracting money from victims who believe they have visually confirmed the other person's identity.
Two additional categories cause damage that is harder to quantify in dollar terms but account for the majority of deepfake volume. Nonconsensual pornography overwhelmingly targets women and causes psychological, professional, and reputational harm that no wire recall can undo. Election manipulation uses deepfakes to fabricate candidate statements, fake news broadcasts, and synthetic protest footage designed to shift public opinion during narrow electoral windows.
Understanding how deepfakes are created, the adversarial training loop, the encoder-decoder architecture, and the tiered taxonomy from cheapfakes to live puppet master attacks is not an academic exercise. It is the foundation for understanding why detection fails, because every detection approach assumes something about the creation process.
When cyberattackers shift architectures, moving from GANs to diffusion models or from offline rendering to real-time streaming, detection tools built on outdated assumptions break. The question is not whether detection will fail under these conditions, but how fast, and what a security team does in the moments between that failure and the next wire transfer.
The Deepfake Detection Gap: Why Tools Fail in Real-World Deployments
This detection gap is not a temporary engineering problem that another round of model training will solve. It is a structural asymmetry that makes technology-only defenses against AI deepfakes fundamentally unreliable, and it lies at the center of the challenges in defending against AI deepfakes that most security programs underestimate. Organizations betting their security posture on detection tools alone are betting against the physics of the problem.
Why Does Lab Accuracy Collapse in Real-World Deployments?
The numbers tell a stark story. The RiskInsight-Wavestone 2025 Anti-Deepfake Solutions Radar found image and video detection solutions averaging 92.5% accuracy against known deepfakes, with audio detection reaching 96%, both in controlled testing environments.
However, a gap exists because laboratory testing strips away everything that makes real-world detection difficult. Research datasets use high-resolution, well-lit videos with consistent framing, while operational media arrive compressed through email servers, are degraded by video conferencing platforms, are shot in dim conference rooms, and are recorded from varying angles. Each variable does not subtract linearly from detection accuracy; the effects compound.
What Is the Generalization Problem and Why Does It Favor Cyberattackers?
Deepfake detectors learn to recognize artifacts left by specific generation architectures. Train a model on StyleGAN outputs, and it becomes adept at spotting StyleGAN's particular pixel-level fingerprints, but feed it a deepfake created by a diffusion model, an entirely different generation paradigm, and the detector fails catastrophically. When a detection system encounters a generation method not present in its training data, its results are no better than random guesses.
This is not a gap that closes over time. It is a structural feature of the detection-generation arms race. Every time a new synthesis architecture emerges, from StyleGAN to diffusion models to transformer-based generators and whatever comes next, detection models must be retrained on that specific architecture's outputs.
Cyberattackers innovate first while defenders scramble to catch up, and the asymmetry is permanent: generating a novel deepfake costs cyberattackers hours, while retraining a detector against that new method costs weeks or months.
The economics compound the problem. Cyberattackers can test their deepfakes against known detection tools before launching them. If a deepfake passes through commercial detectors undetected, it ships; if not, the cyberattacker tweaks the generation pipeline and tests again. This adversarial feedback loop means detection tools are always facing content optimized specifically to bypass them.
How Do Environmental and Demographic Factors Degrade Detection?
Video compression is the silent killer of detection accuracy. Every platform that handles video, including email servers, Slack, Teams, Zoom, and LinkedIn, applies its own compression algorithm, each stripping away pixel-level information.
Deepfake detectors look for subtle inconsistencies in how pixels connect across frames, but compression creates those exact same inconsistencies in authentic video. A legitimate CEO message compressed three times through different platforms triggers the same artifact patterns that detectors were trained to flag.
Lighting, resolution, and background complexity each introduce their own failure modes. Poor lighting hides facial edge artifacts that many detectors use as primary signals, low-resolution processing strips the fine-grained detail detectors depend on, and busy backgrounds interfere with face isolation, causing the detector to fail before it even begins analyzing facial features. Most lab datasets feature clean, front-facing portraits against simple backgrounds, conditions that never occur in operational video calls.
Demographic bias introduces a more troubling dimension. Detection systems consistently perform better on lighter skin tones than on darker ones, on older subjects than on younger ones, and produce higher false-positive rates for certain demographic groups.
Research from the University at Buffalo documented clear bias patterns where detection error rates varied significantly by skin tone, age, and gender, a direct consequence of training datasets overrepresenting certain populations.
Audio deepfake detection exhibits parallel bias: models trained predominantly on American English speakers struggle with other accents and languages. An organization deploying detection globally must confront the reality that its tools will protect some employees better than others.
What Is the Real Cost of False Negatives and False Positives?
False negatives, or missed deepfakes, are the failure mode security teams fear most. The system flags a synthetic video as authentic; an employee trusts what they see; and every missed deepfake is a breach that detection was purchased to prevent.
False positives inflict damage differently, but perhaps more insidiously. The RiskInsight-Wavestone 2025 radar found that nearly 40% of image and video detection solutions still struggle to correctly manage false positives, with between 50% and 70% of real images flagged as deepfakes by some tools. Audio detection performs better: only 7% of solutions exhibit significant false-positive rates, but the visual false-positive problem remains severe.
This creates the "liar's dividend": the phenomenon where authentic media is dismissed as fake because deepfakes are known to exist. When detection systems routinely flag legitimate executive communications as synthetic, organizations learn to ignore the alerts.
Public figures caught in compromising authentic recordings can plausibly claim "that's a deepfake," and detection tools that cry wolf too often make that defense credible. The operational cost of false positives is the slow, complete erosion of trust in the verification system itself, rendering it useless precisely when it is needed most.
The detection gap across all four dimensions leads to one unavoidable conclusion: technology alone cannot solve deepfake defense. The gap is structural, not temporary, and detection tools provide a useful layer, catching known generation methods under favorable conditions, but they cannot be the primary defense.
Verification protocols, out-of-band confirmation for high-risk requests, and employees trained through realistic phishing simulations that include deepfake scenarios create a defense-in-depth that functions even when automated detection fails.
The Financial, Operational, and Psychological Toll of Deepfake Attacks
Deepfake cyberattacks impose a multidimensional cost on organizations that extends far beyond the immediate wire transfer. A 2024 Regula survey found that 92% of organizations have suffered financial losses from deepfake fraud, with the average incident costing $450,000 and the financial services sector absorbing an even steeper $603,000 per cyberattack.
Deloitte's Center for Financial Services projects generative AI-enabled fraud losses in the United States will reach $40 billion by 2027, up from $12.3 billion in 2023, a compound annual growth rate of 32%.
Direct Financial Losses: What Deepfake Attacks Cost in Dollars
The numbers are no longer speculative. Deepfake-enabled fraud caused more than $200 million in global losses during the first quarter of 2025 alone, according to Resemble AI's Q1 2025 Deepfake Incident Report.
These direct losses compound when mapped against the broader breach economics that security leaders already track. IBM's 2025 Cost of a Data Breach Report placed the average cost of a data breach at $4.44 million, and social engineering, the mechanism that deepfakes weaponize, is a dominant initial access vector. An organization that focuses exclusively on technical controls while neglecting the human layer is effectively leaving its largest attack surface unguarded, a gap at the heart of the challenges of defending against AI deepfakes.
Reputational and Operational Damage: The Costs Beyond the Transfer
Financial loss is only the first layer. When news breaks that a CEO was successfully impersonated via deepfake video, the brand damage reverberates for quarters. Customers, investors, and regulators question whether the organization's leadership has adequate control over its financial and information security environment.
Executive impersonation fraud creates a specific reputational crisis: the public learns that the organization's own decision-making infrastructure was circumvented by synthetic media, undermining confidence in governance at every level.
Operational disruption compounds the reputational hit. After a deepfake incident, security teams divert from strategic priorities to run organization-wide investigations, coordinate with law enforcement, engage forensic analysts, and implement emergency verification protocols.
Normal business processes, including fund transfers, vendor payments, and executive communications, all grind to a halt while new authentication layers are deployed. The operational downtime alone often exceeds the direct fraud loss in terms of lost productivity and delayed business.
There is a quieter but equally corrosive consequence unfolding in courtrooms and legal departments. Deepfakes create a chain-of-custody crisis for digital evidence: when any audio recording, video file, or screenshot can plausibly be synthetic, prosecutors and corporate counsel face a new threshold problem of proving the evidence itself is real before they can even argue its significance.
Defense attorneys have already begun deploying the "deepfake defense," asserting that authentic audiovisual evidence is AI-generated, as the Brennan Center for Justice documented in its analysis of the liar's dividend. This weaponization of uncertainty adds legal cost, delays resolution, and erodes the evidentiary foundation that digital commerce depends on.
Psychological Safety and Workplace Culture: Trust on the Line
Even organizations that never suffer a direct financial loss pay a cultural price for the deepfake era. When employees know that any voice on the phone could be synthetic and any face on a video call could be fabricated, the baseline trust that enables efficient collaboration erodes. Finance teams begin questioning legitimate executive requests, IT staff hesitate to process password resets, and procurement officers second-guess vendor payment instructions that were routine a year ago.
This ambient anxiety is not hypothetical; it is the predictable consequence of a working environment where sensory evidence is no longer reliable. The psychological toll manifests in a difficult paradox for security awareness teams: as training programs improve employees' ability to detect deepfake indicators, they simultaneously increase generalized anxiety about digital communication.
"Deepfake will become a growing threat to individuals and employees, and to society at large," said Viggo Tellefsen Wivestad, research scientist at SINTEF Digital, in a 2025 analysis of how synthetic media threatens societal trust. "The technology is still in its infancy."
That observation points to a critical tension: improved detection accuracy in simulation exercises often correlates with decreased confidence in genuine communications. Employees who learn to spot deepfakes also learn that they cannot trust what they see or hear, a cognitive load that human beings were not designed to carry indefinitely.
The Liar's Dividend: When Authentic Evidence Becomes Indefensible
The most destabilizing long-term cost of deepfake technology may be what law professors Bobby Chesney and Danielle Citron termed the "liar's dividend." As public awareness of deepfake capabilities grows, bad actors gain a perverse advantage: they can dismiss authentic, damning evidence as AI-generated.
The mere existence of convincing deepfake technology enables genuine wrongdoers to claim that real recordings, real documents, and real testimony are fabricated, transforming the deepfake threat from a problem of detecting fakes into a deeper crisis of believing in truth.
The liar's dividend has already migrated from political rhetoric into corporate environments. Internal whistleblower recordings, investigative journalism footage, and regulatory documentation are all vulnerable to dismissal with a simple claim of fabrication.
For security leaders, this creates a dual-front defense problem: organizations must not only train employees to identify synthetic media but also build the authentication infrastructure to prove that their own communications, transactions, and records are genuine. Without verifiable provenance, every digital interaction becomes contestable.
These converging financial, operational, cultural, and evidentiary costs make one thing clear: deepfake defense is no longer a security operations issue. It is a board-level concern that touches liquidity risk, brand equity, workforce stability, and legal defensibility in equal measure.
Organizations that treat deepfake preparedness as a niche simulation exercise rather than a strategic business continuity priority are calculating costs based on outdated assumptions. Building resilience starts with confronting employees with the same tactics cyberattackers use, through multi-channel simulations that replicate the voices, faces, and pressure tactics of real deepfake fraud before a live cyberattack ever reaches the organization.
Building a Multi-Layered Deepfake Defense: People, Process, and Technology
Defending against AI deepfakes demands a synchronized combination of trained employees, enforced verification workflows, and detection technology. No single layer can close the gap between what cyberattackers can fabricate and what organizations can catch.
Technology provides a signal but fails against novel cyberattack patterns; process creates verification gates that stop fraud even when detection misses, and people contribute the adaptive, context-aware judgment that neither tools nor static rules can replicate.
Organizations that invest in all three layers simultaneously reduce exposure far more than those betting on any one pillar alone, which is precisely why the challenges of defending against AI deepfakes demand an integrated rather than piecemeal response.
The People-Process-Technology Triad: Why No Single Layer Suffices
The detection gap makes the case for layering. An iProov study found that only 0.1% of participants could accurately distinguish real from deepfake content across images and video, even though participants were primed to look for fakes. In real-world conditions, where employees are not expecting deception, vulnerability is almost certainly higher.
Detection tools perform better in controlled settings but struggle against novel, in-the-wild deepfakes that generative models produce faster than detection models can adapt to. This is not an argument against technology; it is an argument against over-reliance on it. Process fills the gap technology leaves: if every wire transfer above a defined threshold requires out-of-band confirmation through a separate channel, the cyberattacker must compromise two independent trust paths simultaneously.
People fill the gap that process cannot codify, such as an executive who notices an unfamiliar micro-pause or a slightly off vocal cadence and decides to ask a question only the real person could answer.
Process-Based Verification: Extending Zero Trust to Human Communications
Process is the most underinvested layer of deepfake defense and the one that stopped the most famous near-miss on record. In July 2024, an executive at Ferrari received WhatsApp messages that appeared to come from CEO Benedetto Vigna, complete with a profile photo of Vigna in front of the Ferrari logo and voice messages mimicking his distinctive Southern Italian accent. The messages urged immediate action on a confidential acquisition, claiming that regulators had already been notified.
The executive grew suspicious because the tone had slight inconsistencies, and asked a question only the real CEO could answer: the title of a book Vigna had recommended days earlier. The scammer hung up immediately.
That single verification question, pre-established, personal, and impossible to source from open-source intelligence (OSINT), stopped what could have been a multi-million-dollar loss. It is also a replicable process: organizations that adopt structured verification protocols for high-risk requests transform isolated intuition into institutional defense.
Effective process-based verification rests on three principles:
- Out-of-band confirmation: any request involving wire transfers, credential changes, or sensitive data access must be confirmed through a second, independent channel, meaning a phone callback to a known number rather than the one the requester provided;
- Pre-established challenge questions or code words shared only with specific executives and updated periodically;
- The zero trust principle extends to human-to-human communications, where no voice, no face, and no message are trusted by default, regardless of how authentic they appear.
Every high-stakes request is treated as potentially synthetic until independently verified.

[alt text: Process-based verification is a cost-effective, efficient way of disrupting deepfake attacks, such as by including a question for identity confirmation.]Deepfake Awareness Training
Technology Controls: Where Detection Tools Fit in the Stack
Technology controls form the outermost detection layer, and they work best when deployed as a portfolio rather than a silver bullet. Email security gateways remain relevant for filtering AI-generated spear phishing that often precedes a deepfake call, establishing the pretext and urgency the voice or video will exploit. Modern email defenses analyze linguistic patterns, sender reputation, and structural anomalies that distinguish generative AI text from legitimate executive correspondence.
Multi-factor authentication (MFA) must be hardened specifically against deepfake spoofing. Voice biometrics used for step-up authentication can be defeated by cloned audio samples, so organizations should favor phishing-resistant MFA, such as FIDO2 hardware tokens or device-bound passkeys, over biometric modalities that deepfakes can mimic. For video-based identity verification, liveness detection that analyzes micro-movements, skin texture, and environmental reflectance adds a layer of resistance that static face matching lacks.
Browser-based controls address a parallel risk: shadow AI tools that employees use to generate synthetic media. Employees pasting proprietary data into consumer AI platforms, downloading voice-cloning apps, or experimenting with face-swap tools within the corporate environment create exposure vectors that traditional data loss prevention (DLP) misses.
Browser extensions that detect and log AI tool usage and that can block paste actions into unapproved generative AI interfaces close a governance gap that has widened rapidly since 2023.
Board Governance and ROI: Quantifying the Deepfake Defense Investment
Security leaders who frame deepfake defense as a technical problem will struggle to secure funding. Those who frame it as a business risk, with quantifiable exposure and measurable reduction, earn board attention. The cost of a multi-layered defense program, covering training, simulation, detection tools, and verification protocols, is a fraction of the cost of a single successful cyberattack.
The board and C-suite must govern deepfake strategy rather than merely delegate it. Executive teams are the highest-value targets for impersonation; their communication patterns, travel schedules, and speaking engagements are the OSINT feedstock cyberattackers mine.
Governance means mandating verification protocols for the CEO with the same rigor as for accounts payable. It also means mapping deepfake defense to frameworks the board already recognizes:
- NIST CSF 2.0's Govern function explicitly calls for organizational context-setting and risk appetite definition that encompasses AI-enabled cyber threats;
- ISO 27001 Annex A controls covering communications security and supplier relationships directly apply to deepfake fraud vectors;
- MITRE ATT&CK techniques for spear phishing (T1566) and voice phishing map to the deepfake kill chain.
Small and midsize businesses (SMBs) face a different challenge than enterprises: they lack dedicated SOC analysts, formal incident response retainers, and the budget for multi-vendor detection stacks. The process layer, including out-of-band verification, pre-established code words, and mandatory callback protocols, costs almost nothing to implement and stops the same attack vector that nearly took down Ferrari. For SMBs, a process-first defense with periodic employee simulation drills delivers disproportionate protection for the dollars spent.
Across every organization size, the people layer remains the most adaptable component of deepfake defense. Detection tools age within months, and processed documents sit unread until a crisis hits, but an employee who has experienced a convincing deepfake simulation, heard a cloned executive voice, and felt the visceral pull to comply carries that calibration into every subsequent interaction.
That calibration, built through repeated exposure to realistic attack scenarios, transforms a workforce from a collection of potential targets into a detection layer that no technology can replicate alone.
Deepfake Awareness Training: Building Employee Resistance to AI-Powered Deception
Deepfake awareness training succeeds only when it replaces legacy annual training with multi-channel phishing simulation, embeds verification protocols into daily workflows, designs role-specific scenarios for the highest-risk teams, and confronts the psychological paradox that detection training improves accuracy while simultaneously eroding confidence.
Each of these four components addresses a specific failure point that generic security awareness training was never architected to handle. Phishing simulation without verification protocols produces awareness without action, and training without psychological calibration creates employees who are vigilant but paralyzed, a tension that defines the people-layer challenges of defending against AI deepfakes.
Why Generic Security Awareness Training Fails Against Deepfakes
Legacy security awareness platforms were built for a threat landscape defined by suspicious links and misspelled sender addresses. Deepfake video, AI voice cloning, and generative AI spear phishing render those detection cues obsolete. When an employee sees a familiar face on a video call and hears a voice they recognize giving a plausible instruction, the brain defaults to trust rather than suspicion.
A 2025 meta-analysis confirmed that security training improves knowledge and cyber threat awareness with a medium-to-large effect size, yet translating awareness into consistent behavioral resistance requires experiential conditioning rather than passive learning. Knowing about deepfakes does not reliably translate into resisting one.
The velocity gap makes generic security awareness training even more dangerous. Cyberattackers using AI can spin up a convincing executive voice clone from a 30-second earnings call clip and launch a vishing campaign before the weekly security newsletter reaches inboxes. Annual training cycles with 70% completion rates, the industry benchmark for checkbox compliance, cannot keep pace with cyber threats that evolve in hours.
Employees need experiential learning rather than awareness slides. A 2026 study comparing human and AI deepfake detection found that machine classifiers reached 97% accuracy on the same media, whereas human participants hovered near chance, roughly 50%. The lesson is not that humans should try harder; it is that detection-focused training is architecturally mismatched with the threat.
Designing Effective Deepfake Awareness Programs
Effective programs replace abstract awareness with experiential conditioning across every channel cyberattackers use. Multi-channel phishing simulation is the foundation: employees should encounter controlled deepfake video calls, AI-cloned voice messages, SMS impersonation attempts, and open-source intelligence (OSINT)-personalized spear phishing emails in a safe environment before facing them in the wild.
Exposure builds pattern recognition that no slide deck can replicate, particularly when each phishing simulation feels authentic by deploying deepfake video of the employee's actual CEO, using details pulled from a real LinkedIn profile, and timing the request to mimic normal business rhythms.
Training must be triggered by behavior rather than a calendar. When an employee clicks a simulated phishing link or fails to verify a suspicious voice request, the platform should automatically deliver a microlearning module within minutes rather than days later, when the lesson has already faded from memory. This just-in-time reinforcement creates the neurological pairing that durable learning requires.
Role-specific content is non-negotiable. Finance teams face invoice fraud and wire transfer requests, IT staff encounter credential-reset impersonations, and executives navigate the highest-stakes impersonation attempts because their authority is what cyberattackers are exploiting.
A one-size-fits-all module assigned to every employee ignores the reality that a CFO and a junior developer face entirely different threat profiles. Multi-channel phishing simulation platforms that personalize scenarios by role, risk score, and OSINT exposure produce substantially higher behavioral transfer than generic campaigns.
Verification Protocols Employees Must Internalize
No amount of training enables an employee to visually distinguish a high-quality deepfake from a genuine video call in real time. The defense must shift from detection to verification, a procedural habit that bypasses the brain's tendency to trust familiar faces and voices.
Out-of-band confirmation is the single most important protocol to embed: any high-risk request received via voice or video must be confirmed through a separate, independent channel before any action is taken. A CFO requesting a wire transfer on a video call must be verified using a known phone number, an internal messaging platform, or in-person confirmation.
Callback procedures must be pre-established and non-negotiable. Employees should never use contact information provided in the suspicious communication itself; if a "CEO" texts a new phone number and asks to be called there, the callback must go to the number stored in the corporate directory, never the one provided.
Code words shared within finance and executive teams add a second authentication layer that even perfect deepfakes cannot spoof, provided the word is never stored digitally or communicated through channels a cyberattacker could intercept.
The policy that matters most is simple and absolute: never act on voice or video alone for financial transactions, credential changes, or data transfers. This rule removes the cognitive burden of deciding whether the media "looks real," anchoring the decision in procedure rather than perception.
The Training Psychology Paradox
The most troubling finding in deepfake awareness research is that training can backfire psychologically. A 2024 study led by Dr. Alexander Diel found that deepfake detection training improved participants' accuracy but simultaneously increased their emotional distress and reduced their self-efficacy, the belief in their own ability to handle the threat. Employees finished the training better at identifying fakes, but were more anxious and less confident in their judgment.
This paradox creates a dangerous dynamic in high-pressure situations: an employee who doubts their own assessment may freeze at the moment they most need to act.
The solution is not to abandon realistic training but to pair it with psychological scaffolding. Programs must normalize the experience of being deceived, framing simulation failures as data points rather than personal shortcomings, and provide clear, simple action paths that reduce the cognitive load of decision-making under uncertainty.
When an employee knows that the only correct response to a suspicious request is "hang up and call back on a known number," confidence in detection ability becomes unnecessary; what matters is confidence in the procedure. Building resilience without building paranoia requires measuring both behavior change and psychological well-being across the training lifecycle, adjusting intensity when anxiety metrics rise faster than performance metrics.
Trained employees who can apply verification protocols under pressure are the strongest defense against AI-powered impersonation. Human vigilance alone cannot detect a synthetic face in real time, and it should not have to. Detection tools operating alongside a behaviorally conditioned workforce create a defense greater than either layer alone.
Evaluating Deepfake Detection Tools: What Organizations Must Ask Before Buying
Evaluating deepfake detection tools begins with demanding real-world accuracy data rather than vendor white papers. From there, security teams must assess how the tool deploys in their environment, whether open-source or commercial better fits their operational maturity, and how cross-platform intelligence sharing will shape the tool's longevity. Every evaluation criterion must be weighted against the reality that the deepfake generation landscape shifts faster than any static detection model can keep pace, which is one of the more underappreciated challenges in defending against AI deepfakes at the procurement stage.
The Vendor Evaluation Framework: Questions That Separate Marketing From Capability
Most detection vendors publish accuracy figures derived from curated benchmark datasets that bear little resemblance to the deepfakes an organization will actually face. The first question every security team must ask is what the real-world accuracy is, measured against diverse, uncurated content rather than the lab number on the product sheet.
The second question is equally critical: how diverse was the training data across demographic groups, lighting conditions, compression artifacts, and generation methods? A model trained predominantly on faces from one demographic will produce catastrophic false-positive rates when processing faces outside that distribution, so security teams should demand the vendor's false-positive and false-negative rates across different confidence thresholds rather than the single aggregate number volunteered.
Third, establish exactly how frequently the model is updated against new generation techniques, since deepfake generation models evolve on a weekly cadence and a detector last retrained six months ago is already blind to an entire generation of attack tools.
Finally, require the vendor to produce results from pilot testing with representative datasets that match operational conditions, such as conference room lighting, compressed video streams, and typical audio quality. Accept nothing less than performance demonstrated against the actual threat surface rather than pristine lab samples; a vendor that cannot or will not provide this data is selling a capability that has not been validated for that environment.
Deployment Models and Computational Demands: The Infrastructure Reality Check
Detection tool deployment is not a trivial configuration toggle. Organizations must map the available deployment models (API-based, SaaS, or on-premises Docker containers) against latency requirements, data residency obligations, and existing infrastructure.
GPU acceleration is the default requirement for real-time video analysis; without dedicated GPU capacity, detection latency can range from sub-second to minutes, rendering the tool useless for live videoconferencing scenarios where an impersonated executive requests an urgent wire transfer during the call.
The scalability math is unforgiving. Storage costs for archived call recordings, bandwidth overhead for streaming analysis, and the compute burden of running inference on every video frame compound rapidly as deployment scales beyond a pilot group to cover the entire organization.
The starkest number security leaders need to internalize comes from the 2025 RiskInsight-Wavestone radar: only 19% of detection solutions offer live videoconferencing integration, and those that do operate at a 73% accuracy ceiling, meaning even the best live-detection tool on the market will miss more than one in four deepfake calls.
Detection cannot be the only control. It must be paired with out-of-band verification protocols that exist independently of the tool's verdict. Employees trained through regular phishing simulations learn to verify high-risk requests through a second trusted channel, even when the voice on the other end sounds exactly like the CFO.
Open-Source vs. Commercial Solutions: Transparency Against Polish
Open-source detection tools offer a genuine structural advantage: full auditability. Security teams can inspect the model architecture, examine the training data composition, and verify that the system is not embedding undisclosed biases or backdoors. That transparency comes with a maintenance burden that most enterprise security teams underestimate.
Open-source detectors require dedicated machine learning engineering resources to retrain against new generation methods, tune thresholds for the organization's specific content profile, and integrate outputs into security operations workflows. Commercial vendors absorb that ongoing maintenance, provide technical support, and ship regular model updates.
The gap is widening, since as deepfake generation accelerates, the delta between what an under-resourced open-source deployment can detect and what a continuously updated commercial model catches grows with each new generation technique release.
The right evaluation approach applies the same criteria to both categories: real-world accuracy, demographic fairness, false positive rates, and update cadence. The operational reality of a team's capacity should determine which path it can sustain.
Cross-Platform Intelligence and the Future: Why No Detection Purchase Is Evergreen
Detection improves most when cyber threat intelligence flows between organizations, vendors, and platforms rather than sitting siloed inside a single deployment. Cross-vendor intelligence sharing allows detection models to learn from attack patterns observed across thousands of environments, narrowing the window during which a novel deepfake generation technique can operate undetected.
The vendors investing in shared intelligence pipelines today will have structurally superior detection accuracy two years from now because their training data will reflect a far broader slice of real-world attack behavior.
Content provenance standards represent the longer-term play. The Coalition for Content Provenance and Authenticity (C2PA) specification embeds cryptographically verifiable metadata about media origin and edit history directly into content.
This standard gained operational momentum across 2025 and early 2026: Google shipped C2PA support on Pixel 10 devices with hardware-backed signing via the Tensor G5 and Titan M2 security chip, and Sony launched the PXW-Z300, the first camcorder to embed C2PA Content Credentials at capture.
The EU AI Act's Article 50, which mandates AI-generated content labeling, took effect on August 2, 2026. Provenance-based authentication is now operational rather than theoretical.
Blockchain-based frameworks remain further out. They add immutability to the provenance chain but introduce throughput, cost, and governance challenges that have not been solved at enterprise scale. Realistic adoption timelines put C2PA-verified content as an enterprise expectation within 18 to 24 months, with blockchain-anchored provenance arriving meaningfully in the three-to-five-year window.
Every evaluation framework must account for the uncomfortable truth that no detection purchase is evergreen, since the generation models that will defeat today's best detectors are being trained right now. Organizations should treat detection tool procurement as an 18-month commitment with a built-in reassessment gate rather than a five-year platform decision.
This reality is precisely why the regulatory environment, which increasingly mandates deepfake defenses as a compliance obligation rather than a discretionary security investment, is becoming the forcing function that drives sustained detection investment.
Global Regulatory Frameworks and Emerging Legal Liabilities for Deepfakes
The regulatory response to deepfakes has moved from discussion to enforcement faster than any previous technology policy cycle. In 2024, 32 U.S. states had laws addressing sexually explicit deepfakes; by mid-2026, that number reached 46, according to a legislative tracker from STACK Cybersecurity.
The EU AI Act's transparency provisions take legal effect in August 2026, China's deep synthesis regulations mandate watermarking and consent, and the UK's Online Safety Act imposes platform accountability for synthetic media.
Yet the penalties, definitions, and enforcement mechanisms vary so dramatically across borders that a single deepfake cyberattack targeting a multinational organization can trigger conflicting regulatory obligations in five jurisdictions simultaneously, compounding the challenges of defending against AI deepfakes at the compliance level.
Jurisdiction-by-Jurisdiction: How Deepfake Laws Compare Globally
No two jurisdictions have taken the same approach to regulating deepfakes. The result is a compliance environment that demands location-specific legal analysis for any organization operating across borders.
In the United States, regulation remains a state-level patchwork with an emerging federal overlay. The TAKE IT DOWN Act, signed in May 2025 after near-unanimous congressional support, criminalized the non-consensual publication of intimate imagery, whether authentic or AI-generated, with penalties of up to two years' imprisonment for adult victims and three years for minors. The Federal Trade Commission now enforces platform compliance, with civil penalties of up to $53,088 per violation.
On the state side, New Jersey's 2025 law imposes up to five years in prison or $30,000 in fines for deepfake harassment, and Washington State criminalized the intentional use of "forged digital likenesses" effective July 2025.
For election-related deepfakes, 30 states have enacted disclosure requirements ahead of the 2026 midterms, though California's AB 2839 saw key provisions struck down by a federal court in August 2025 on First Amendment grounds. The federal government has not yet passed comprehensive legislation addressing deepfake-enabled fraud or corporate impersonation, leaving a gap that state laws fill unevenly.
The European Union's AI Act took a structurally different approach by regulating the technology itself rather than specific harms. Article 50 mandates that AI systems producing synthetic content must mark their outputs as artificially generated, and that deployers of deepfakes must disclose that the content has been manipulated. These transparency obligations apply regardless of whether the deepfake causes harm, making labeling alone the baseline for compliance.
The Act also prohibits AI systems that scrape facial images from the internet or CCTV footage, directly targeting the data supply chain that enables unauthorized deepfake creation. Enforcement is layered: the AI Office at the European Commission oversees general-purpose AI, while member-state authorities enforce rules for high-risk systems.
Complementing this, the GDPR's Article 9 framework means that deepfakes using biometric data for identification purposes trigger special-category data protections, creating dual liability under both AI and privacy law.
Outside the U.S. and EU, regulatory models diverge sharply:
- China's deep synthesis regulations, effective January 2023 and strengthened since, mandate explicit consent from individuals whose likenesses are used, require visible watermarking on all synthetic media, and impose criminal liability for fraudulent deepfakes;
- The UK's Online Safety Act empowers Ofcom to require platforms to remove illegal synthetic content, with fines of up to £18 million or 10% of global annual revenue;
- Australia criminalized non-consensual deepfake pornography at the federal level in 2024, and South Korea criminalized deepfake pornography with sentences up to five years after a 2024 scandal involving synthetic images of thousands of women;
- Japan relies primarily on existing defamation and privacy torts, while India's IT Act and proposed Digital India Act address deepfakes through intermediary liability;
- Singapore's Protection from Online Falsehoods and Manipulation Act (POFMA) enables takedown orders for synthetic media that threaten public interest.
The penalty range is vast, from civil fines to multi-year imprisonment, and what constitutes a criminal deepfake in Seoul may be a civil matter in Tokyo.
Organizational Legal Liabilities: When Deepfakes Become an Operational Problem
Organizations now face a growing web of liability exposure that extends far beyond the direct financial loss of a successful deepfake cyberattack. Three liability domains are converging rapidly.
First, AI regulation is creating affirmative obligations to defend against deepfakes. The EU AI Act's transparency mandates do not exempt organizations from liability merely because they were deceived; if a company deploys AI systems that interact with employees or customers, it must implement reasonable safeguards against the abuse of synthetic media.
Failure to do so could constitute negligence under both the AI Act and existing tort frameworks. In the U.S., the FTC has signaled that inadequate security against AI-enabled fraud may constitute an unfair trade practice under Section 5 of the FTC Act, particularly where organizations collect and store the executive voice and video data that cyberattackers exploit.
Second, GDPR and biometric data protection create liability when employee likenesses are harvested for deepfakes. Cyberattackers routinely scrape audio from earnings calls, LinkedIn videos, and podcast appearances to clone executive voices. Under GDPR Article 9, biometric data, including voice and facial data processed for identification, receives heightened protection.
Organizations that fail to monitor and limit the public availability of executive biometric data may face regulatory scrutiny not only for breach notification failures but for antecedent data protection obligations, and legal analysts have noted that deepfake creation constitutes personal data processing under GDPR, triggering transparency, data minimization, and erasure requirements.
Third, deepfakes create unprecedented chain-of-custody problems for digital evidence in regulatory and legal proceedings. When an employee authorizes a $500,000 wire transfer after a deepfake video call, the organization must prove to regulators, insurers, and law enforcement that the call was synthetic. Deepfake detection tools produce probabilistic outputs rather than certainties, and the forensic artifacts that prove manipulation may degrade before they can be preserved.
Courts are only beginning to grapple with this: the Advisory Committee on Evidence Rules has proposed an amendment to Rule 901 of the Federal Rules of Evidence that would require that, when digital evidence is challenged as potentially synthetic, the proponent prove authenticity under a heightened "more likely than not" standard. This shift from the traditional presumption of authenticity signals how deeply deepfakes have disrupted evidentiary norms.
Cyber Insurance and Risk Transfer: Coverage in the Deepfake Era
Cyber insurance markets are adapting to deepfake risk in real time, but unevenly. Most cyber policies include social engineering fraud coverage, but typically with sublimits that cap at $250,000, which is inadequate for deepfake-enabled losses that routinely exceed six figures.
When a deepfake-assisted fraud involves no network intrusion, and the only compromised element is human judgment, carriers may classify the loss as a crime rather than a cyber event, pushing it outside many policy definitions.
According to a 2026 analysis by SeedPod Cyber, some carriers began adding explicit AI-specific exclusions in late 2024 and 2025, while others moved toward affirmative coverage, explicitly stating that deepfake-assisted fraud is covered regardless of the technology used.
The market divide is now clear. Some carriers take an affirmative approach, explicitly defining how existing coverage responds to AI-driven cyber threats and offering endorsements that cover forensic analysis, legal takedown support, and crisis communications, not just financial loss.
Others maintain "silent" policies that say nothing about AI, leaving coverage disputes to be resolved after the fact. Underwriters are increasingly mandating specific controls as coverage conditions, including dual authorization for wire transfers above defined thresholds, out-of-band verification through channels separate from the one where the request arrived, and security awareness training that specifically addresses AI-generated impersonation. Organizations that cannot demonstrate these controls face higher premiums, lower sublimits, or outright coverage denial.
The risk transfer landscape remains incomplete while detection tools remain probabilistic rather than deterministic. No carrier will write unlimited deepfake coverage, and no detection tool guarantees identification of every synthetic interaction.
The practical strategy is layered: social engineering coverage reviewed for AI-specific language, crime insurance that bridges the cyber-crime gap, and internal controls that satisfy coverage conditions while actually preventing losses. Regulatory mandates are accelerating: the TAKE IT DOWN Act's platform compliance deadline arrived in May 2026, and EU AI Act enforcement is ramping.
Regulation alone will not close the defense gap; only continuous, multi-layered programs that combine detection technology, verification protocols, and realistic deepfake-simulation training prepare organizations for synthetic-media cyberattacks that outpace any single regulation's ability to prevent them.
How Security Awareness Programs Close the Deepfake Defense Gap
Security awareness training transforms deepfake defense from a detection problem into a human risk management discipline. While automated detection tools chase pixel-level artifacts that cyberattackers continuously learn to mask, trained employees recognize the contextual anomalies, including unusual requests, urgency manipulation, and channel switching, that no algorithm can flag.
The organizations that close the deepfake defense gap are those that treat their workforce not as the primary attack vector but as an adaptive detection layer that technology alone cannot replicate.
Why Does Security Awareness Training Outperform Detection Tools at Catching Contextual Deepfake Attacks?
Automated deepfake detection tools operate on a generalization problem they cannot solve. They train on known datasets, looking for GAN fingerprint inconsistencies, irregular blinking patterns, unnatural head movement, or audio-visual synchronization errors, and then attempt to apply those pattern-matching rules to entirely novel synthetic media.
The cyberattacker's advantage is structural: every generation of deepfake generators, from Stable Diffusion-based face-swap models to neural voice-cloning engines like ElevenLabs, is explicitly trained to eliminate the artifacts that previous detectors relied on. A detector trained on January 2026 artifact signatures will not reliably catch a March 2026 generation model trained specifically to defeat it.
Humans detect differently. When a finance team member receives a video call from the CFO at 4:52 PM on a Friday requesting an urgent wire transfer to an unfamiliar account, and the CFO has never once made a direct transfer request in three years of working together, the anomaly lives in context rather than in pixels.
When a message arrives via email, gets confirmed over WhatsApp, and is followed by a voice call, the channel-switching pattern itself raises suspicion. These behavioral and situational signals exist entirely outside the media file that a detection algorithm would scan.
Security awareness programs systematically build this detection capability. They do not teach employees to spot synthetic artifacts, since that is a losing race against improving generator models. Instead, they condition people to recognize the social engineering patterns that accompany deepfake cyberattacks regardless of media quality. The question "Does this request make sense?" replaces "Does this video look real?"
That shift in detection logic closes the gap left by automated tools. A workforce conditioned to verify unusual requests through a second trusted channel, to question the urgency of requests that bypass standard processes, and to report anomalies immediately becomes a distributed detection network that no single-point tool can match.
Why Annual Compliance Training Cannot Defend Against Threats That Evolve in Hours?
Annual security awareness training was designed for a threat landscape that no longer exists. When phishing meant poorly spelled emails with suspicious attachments, a yearly refresher on red flags could reasonably cover the attack surface. Deepfake campaigns, AI-generated spear phishing, and multi-channel social engineering cyberattacks now evolve in hours, a pace that makes annual training cycles functionally obsolete before the course material is even drafted. A deepfake generation technique that emerges in February will not appear in a compliance module until the following year's curriculum review.
The alternative is continuous microlearning triggered by real behavioral signals. When an employee fails a phishing simulation, the system delivers a five-minute module on the specific technique missed, not a generic "be careful with email" reminder but targeted instruction on that exact attack pattern.
When open-source intelligence (OSINT) monitoring surfaces new personal data about an employee that cyberattackers could weaponize, that employee receives role-specific training on the impersonation risks they now face. When real-world cyber threat intelligence identifies a new deepfake social engineering campaign targeting the organization's industry, relevant teams receive immediate scenario training before the cyberattack reaches their inboxes.
Individual risk scoring makes this model scalable. An accounts payable clerk with an extensive LinkedIn presence, frequent contact with external vendors, and wire transfer authority has a fundamentally different risk profile from a developer with minimal public exposure and no access to financial systems.
Continuous programs assign training volume and phishing simulation frequency based on these risk signals: high-exposure employees receive more frequent, more sophisticated simulations, while low-risk roles maintain baseline readiness without training fatigue.
How Do Security Leaders Quantify Human Risk Beyond Training Completion Rates?
Completion percentages tell security leaders exactly one thing: which employees clicked through a module. They reveal nothing about whether anyone is actually safer. A 95% completion rate on an annual phishing course is meaningless if the same population clicks 28% of simulation emails three months later. Human risk quantification replaces activity metrics with behavioral outcomes.
Four metrics form the foundation of meaningful measurement:
- Phishing simulation susceptibility trends track click rates, credential submissions, and attachment opens across phishing, vishing, smishing, and deepfake simulations over time, revealing whether resistance is improving, plateauing, or degrading;
- Phish alert button reporting rates measure how quickly and consistently employees flag real and simulated cyber threats, providing a direct read on the organization's detection reflex;
- Verification protocol adherence tracks whether high-risk requests, including wire transfers, credential changes, and sensitive data disclosures, are confirmed through a second channel before execution;
- Aggregate human risk scoring combines simulation behavior, training engagement, OSINT exposure, credential breach history, and role sensitivity into a single, quantifiable metric for each employee, department, and organization.
Adherence to verification protocols is the highest-leverage behavior for stopping deepfake-enabled fraud, and these metrics translate directly into board-ready language. A CISO who reports "87% training completion" communicates compliance theater.
The same CISO who reports that phishing susceptibility dropped from 24% to 6% over nine months, that phish alert button reporting rose from 12% to 41%, and that verification protocol adherence reached 94% across finance and executive teams communicates risk reduction in terms the board can evaluate against breach cost projections.
The central thesis of deepfake defense is unambiguous: this is not a detection problem to be solved by technology alone. Detection algorithms provide a necessary layer, but they operate on a media-level playing field where cyberattackers hold the structural advantage.
Security awareness training closes the gap by building human detection capabilities that operate on context, behavior, and verification, signals that exist outside any media file. Verification protocols provide the safety net that catches what both humans and algorithms miss.
The organizations that defend effectively against deepfake cyber threats deploy all three layers: detection tools, trained employees, and enforced verification processes, as a single integrated defense rather than disconnected tools competing for budget and attention. Building that integrated defense starts with phishing simulations that make abstract cyber threats visceral, so employees recognize a cyberattack before it can be acted on.
Key Takeaways
- The challenges defending against AI deepfakes are structural rather than temporary: detection tools lose 45 to 50 percentage points of accuracy in real-world deployments compared to lab testing;
- Deepfake cyberattacks now span five channels simultaneously, including email, voice, SMS, video conferencing, and social media, making single-layer defenses insufficient;
- Puppet master attacks, like the $25 million Arup incident, defeat both forensic detection and standard identity verification because the synthetic media is generated and streamed live;
- Out-of-band verification through a separate, pre-established channel remains the single most reliable control against deepfake-enabled fraud, as demonstrated by the Ferrari near-miss;
- Multi-channel phishing simulation that includes deepfake video, cloned voice, and OSINT-personalized scenarios builds behavioral resistance that generic annual training cannot replicate;
- Deepfake detection training carries a documented psychological cost, improving accuracy while increasing anxiety, which is why programs must pair realistic simulation with procedural confidence rather than detection confidence alone;
- Regulatory frameworks, including the EU AI Act, the TAKE IT DOWN Act, and a fragmented patchwork of state and international laws, are converging on deepfake defense as a compliance obligation rather than a discretionary investment;
- A people-process-technology triad, anchored in trained employees, enforced verification protocols, and properly evaluated detection tools, is the only defense model that addresses the full scope of the challenges of defending against AI deepfakes.
Frequently Asked Questions About Defending Against AI Deepfakes
Can AI deepfake detection tools reliably identify deepfakes in real-time video calls?
AI deepfake detection tools cannot reliably identify deepfakes in real-time video calls today. Commercial detection tools that achieve 92 to 98% accuracy in controlled lab environments drop 45 to 50 percentage points when deployed in operational settings with variable lighting, compression, and network conditions.
While real-time multimodal systems analyzing voice, video, and behavioral signals have reached 94 to 96% accuracy in research settings, according to the World Economic Forum, models trained on one generation method consistently fail against novel architectures. This structural generalization gap makes real-time call protection an unsolved challenge requiring complementary human verification protocols.
How do deepfakes bypass biometric verification and KYC systems in financial services?
Deepfakes bypass biometric verification and KYC systems by defeating liveness detection, the mechanism designed to confirm a real person is present during identity verification. Cyberattackers use real-time face-swapping tools that inject synthetic video feeds directly into the camera stream during KYC onboarding, replicating micro-expressions, head movements, and responses to randomized challenge prompts that liveness checks depend on.
Trend Micro researchers documented in 2024 that fraudsters deploy generative adversarial networks to produce synthetic selfies and video recordings capable of passing automated document verification and facial comparison.
What percentage of businesses have encountered deepfake attacks in the past year?
Nearly half of businesses (49%) have encountered deepfake cyberattacks in the past year. This figure comes from Regula's 2024 survey, which found that audio and video deepfake fraud had struck 49% of organizations in the preceding 12 months.
The survey documented a 20% year-over-year increase in companies reporting video deepfake incidents specifically. By early 2025, separate research indicated the figure had climbed further, with some sources reporting that up to 50% of businesses globally experienced audio or video deepfake fraud.
North American organizations saw a 1,700% increase in deepfake incidents during this period, while APAC regions recorded a 1,500% surge, reflecting the global velocity of the cyber threat.
What is the difference between a cheapfake and a deepfake, and which poses a greater risk to organizations?
A cheapfake is falsified media created without artificial intelligence, through slowing, speeding, recontextualizing, or making basic edits to authentic content. A deepfake is AI-generated synthetic media produced via generative adversarial networks or autoencoders that convincingly replaces a person's likeness or voice.
Cheapfakes require no technical skill and can be created in minutes using free tools, as documented by Data & Society researchers, while deepfakes demand more computational resources but produce far more convincing results.
For organizations, deepfakes pose a greater direct financial risk. Both weapons are converging as accessible AI tools make sophisticated manipulation available to anyone with a browser, making layered human and technical defenses essential.
Multi-channel deepfake simulation paired with OSINT-personalized training transforms a workforce from the primary target into an adaptive detection layer that technology alone cannot match. Take a self-guided tour of the Adaptive Security platform to see how personalized simulations build measurable resilience across an organization.
See How Multi-Channel Deepfake Simulation Builds Employee Resilience
Multi-channel deepfake simulation paired with OSINT-personalized training transforms your workforce from the primary target into an adaptive detection layer that technology alone cannot match. Take a self-guided tour of the Adaptive Security platform to see how personalized simulations build measurable resilience across your organization.

As experts in cybersecurity insights and AI threat analysis, the Adaptive Security Team is sharing its expertise with organizations.
Contents