AI guardrails for employees are the technical controls, policies, and CAT frameworks that enable organizations to safely adopt generative AI tools without exposing sensitive data, violating regulations, or stifling productivity. This guide covers the full spectrum of safe AI adoption.
It spans the four-layer taxonomy of data, model, application, and infrastructure guardrails, walks through building an AI acceptable use policy that drives real behavioral change, and provides actionable frameworks for technical enforcement through access controls and content safeguards.
The guide also includes strategies for CAT employees on responsible AI use and methods for aligning guardrail requirements with regulatory frameworks spanning the EU AI Act, GDPR, HIPAA, and the NIST AI Risk Management Framework.
IBM's Cost of a Data Breach Report 2025 found that shadow AI use added an average of $670,000 to data breach costs, while only 37% of breached organizations have policies in place to manage AI or detect shadow AI.
Explore Adaptive Security's self-guided platform tour to see how a security awareness training approach to AI risk management can close these gaps before they become incidents.
What Are AI Guardrails for Employees
AI guardrails for employees are the policies, technical controls, and behavioral protocols that define how workers may and may not use generative AI tools while handling company data, making business decisions, or communicating with external parties.
They exist to prevent the specific harms that arise when employees paste sensitive financial information into ChatGPT, trust an AI-generated summary without verification, or deploy unapproved tools that bypass security review entirely. Unlike broad AI governance frameworks aimed at model development and regulatory compliance, employee-facing guardrails operate at the user layer, the place where most AI risk actually materializes.
Worker access to generative AI inside enterprises surged 50% in 2025 alone, according to Deloitte's 2026 State of AI in the Enterprise report. That velocity brings enormous productivity potential and a governance vacuum that most organizations have yet to close.

Core Definition and What AI Guardrails Are Not
AI guardrails for employees are not a synonym for AI governance, and conflating the two creates precisely the gap that cyberattackers and accidental data leaks exploit. Governance is the board-level, policy-layer architecture: risk appetite statements, compliance mapping, model auditing standards, and accountability structures.
Guardrails are the operational mechanisms that make governance enforceable at the employee's keyboard. They answer the question of what happens when someone in finance copies a contract into a public large language model, or when a developer connects an unauthorized AI coding assistant to the production repository.
What guardrails are not: they are not a blanket ban on generative AI. Organizations that attempt outright prohibition drive usage underground. Deloitte's research confirms that only one in five companies maintains mature governance for autonomous AI, leaving the other four exposed to shadow AI that security teams cannot see.
- AI guardrails for employees are not traditional data loss prevention (DLP), which was architected for structured data moving through known egress points rather than for employees pasting unstructured text into browser-based AI chat interfaces;
- They are not generally acceptable use policies that sit unread in an employee handbook;
- Effective guardrails are real-time, browser-level, and behaviorally enforced, detecting risky AI interactions as they happen rather than auditing them after the fact.
Why AI Guardrails Matter Now
Employees adopted generative AI faster than any enterprise technology in modern history. Deloitte found that workforce access to AI tools reached roughly 60% of employees in 2025, up sharply from fewer than 40% the prior year, yet only 21% of organizations report having mature governance for autonomous AI agents. This gap creates three compounding risks.
Data exfiltration via AI tools is trivial and nearly invisible to existing security infrastructure. An employee troubleshooting a customer issue pastes a CSV containing personally identifiable information into Claude or ChatGPT, with no attachment, no email, and no DLP trigger involved.
AI-generated content also introduces a risk of hallucination into business decisions: a procurement officer who uses an AI tool to summarize a vendor contract may act on fabricated terms, creating contractual exposure that legal teams never see coming.
Ungoverned AI usage further expands the cyberattack surface for social engineering. Cyber threat actors already use open-source intelligence (OSINT) to personalize spear phishing, and when employees routinely feed proprietary information into public AI tools, they are effectively performing reconnaissance work for the cyberattacker.
How Guardrails Balance Safety with Innovation and Speed
The fundamental tension in AI guardrails for employee design is that restriction and enablement are interdependent rather than opposed. A guardrail that blocks every AI tool guarantees security but destroys the productivity gains that drove adoption in the first place, while a guardrail that permits everything preserves speed but transfers risk directly to the balance sheet.
Effective guardrails resolve this tension through graduated enforcement rather than binary allow/block logic. An employee pasting source code into a public AI tool triggers a real-time warning and an automatic CAT micro-module, but the tool remains available for low-risk use cases.
An employee attempting to upload a customer database to an unapproved AI application is blocked outright and enrolled in a mandatory policy acknowledgment workflow. Finance teams working with sensitive M&A documents operate under stricter AI usage profiles than marketing teams drafting public-facing content, and this risk-tiered model preserves the speed that makes AI valuable while applying friction proportional to exposure.
Organizations doing this well treat AI guardrails for employees as a product of their security culture rather than a compliance artifact imposed from above. They communicate the reasoning behind every restriction, share anonymized near-miss data with teams, and continuously tune thresholds based on telemetry from actual usage.
In practice, guardrails become less restrictive over time, not because risk disappears, but because employees internalize safe behaviors and need fewer interventions. Browser-level visibility into AI tool usage feeds directly into each employee's human risk score, giving security teams a measurable baseline that improves quarter over quarter.
AI Guardrails Versus Traditional Content Moderation Tools
Traditional content moderation (web filtering, URL blocking, keyword-based DLP) was built for a world where the primary risk was employees visiting dangerous websites or emailing credit card numbers. Those tools operate by pattern-matching against known-bad indicators.
AI guardrails for employees must address an entirely different problem: the risk is not the tool itself but what the employee does with it, and the indicators of misuse are behavioral rather than pattern-based.
This architectural difference has practical consequences. A URL filter can block access to chat.openai.com, but it cannot distinguish between an employee asking ChatGPT to explain a Python library and an employee pasting a non-public earnings forecast into the same interface.
A DLP rule can detect a 16-digit number that matches the credit card format in an email, but it cannot detect that an employee just summarized an internal strategy document and pasted the result into a personal AI account. AI guardrails require browser-level visibility into the content flowing into and out of AI tools, combined with behavioral signals that distinguish productive use from risky behavior.
The operational model differs as well. Traditional content moderation tools are configured once by IT and updated periodically, whereas AI guardrails for employees demand continuous adaptation since new AI tools launch weekly and usage patterns shift as employees discover new workflows.
The risk profile of a given tool changes as its capabilities expand, requiring telemetry-driven feedback loops in which security teams monitor actual AI usage patterns, adjust thresholds, and push targeted CAT to the specific users and departments exhibiting risky behavior.
The goal is not a perfect static fence but a dynamic system that learns from usage data and tightens or loosens controls based on observed risk, producing a living governance model that gets smarter as the organization's AI footprint grows.
The Hidden Risks of Unchecked AI Use in the Workplace
When employees use AI tools without AI guardrails, organizations face a multi-layered risk cascade. Breaches involving shadow AI add an extra $670,000 to the average cost, according to IBM's 2025 Cost of a Data Breach Report.
Employers face escalating legal liability for AI-driven discrimination, regulatory violations, and intellectual property exposure regardless of whether the misuse was intentional. The financial, legal, and operational consequences compound because most organizations lack visibility into which AI tools employees use and what data flows into them.

Shadow AI, The Ungoverned AI Undercurrent
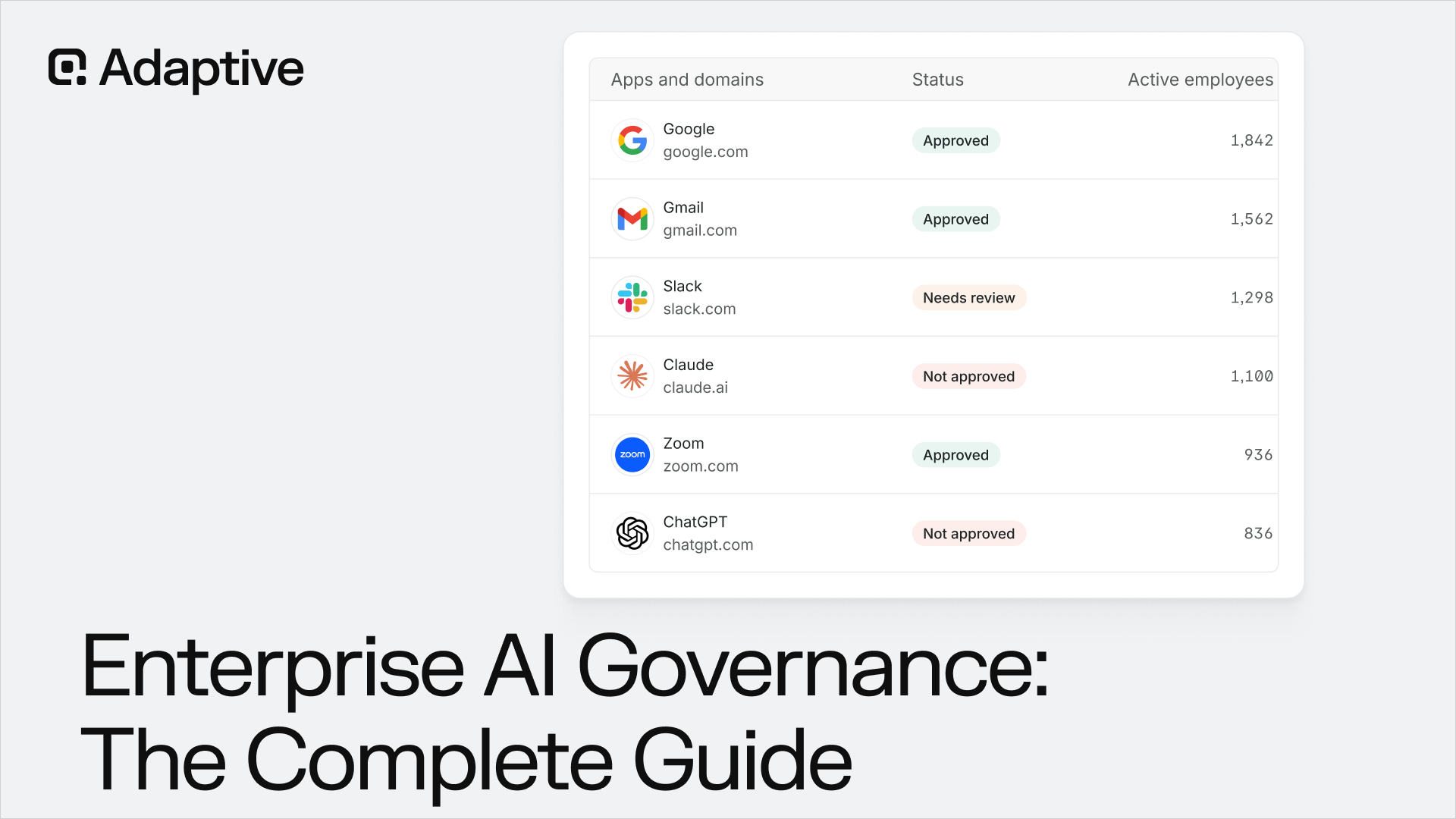
Shadow AI describes the use of AI tools and platforms by employees without IT approval, security vetting, or organizational governance. The scale of this phenomenon has outpaced nearly every enterprise's ability to manage it.
According to IBM's Cost of a Data Breach 2025 report, 63% confirmed they have no AI governance policies in place to manage or prevent workers from using unsanctioned AI tools.
Employees gravitate toward unsanctioned AI for straightforward reasons: ChatGPT, Claude, and Perplexity accelerate writing, analysis, and coding tasks that internal tools either cannot perform or require lengthy approval chains to access. The productivity gain is real, while the security debt it creates rarely becomes visible until a breach has already occurred.
That debt carries a specific, measurable price tag. IBM's 2025 report found that organizations with high levels of shadow AI experienced breaches costing $670,000 more than the average, and twenty percent of all organizations studied had already suffered a breach directly tied to shadow AI use.
These breaches caused broader data compromise and operational disruption, halting sales processing, customer service delivery, and supply chain operations. The 97% of AI-breached organizations that lacked proper AI access controls, also documented in the same IBM study, confirms that governance is not keeping pace with adoption.
How Employees Inadvertently Expose Sensitive Data Through AI Tools
The most common data leakage vector in the AI workplace requires no sophisticated cyberattack. An employee pastes a contract into ChatGPT to summarize it, uploads a customer spreadsheet for analysis, or asks Claude to troubleshoot proprietary source code.
Cyberhaven's 2026 analysis of enterprise AI usage found that 39.7% of all employee AI interactions exposed sensitive data, with workers leaking confidential information to AI tools approximately every three days.
The exposure categories are broad and consequential. Employees regularly submit customer PII in the prompt text, upload financial models and legal contracts as attachments, and copy-paste internal strategy documents for AI-assisted editing.
Each action transmits data to external model providers, whose data retention and training policies incorporate it into future model versions, meaning the data does not remain contained but becomes part of the AI provider's ecosystem, accessible through mechanisms that most organizations have not audited and cannot control.
Compounding this exposure is the third-party vendor AI functionality problem. SaaS platforms that organizations have already approved, including CRM systems, productivity suites, cloud storage, and collaboration tools, are now embedding AI copilots and generative features into their products. Employees interacting with these embedded AI features may not recognize that data is being sent to an external model because the interface lives inside a trusted application.
A sales representative using an AI assistant embedded in a CRM to draft customer communications can inadvertently expose deal structures, pricing data, and client PII to a model whose existence went unrecognized. Traditional DLP and CASB tools were not designed to detect or intercept this class of risk, leaving organizations with a visibility gap across both sanctioned and unsanctioned AI channels.
Misinformation, Bias, and Compliance Violations in AI-Generated Outputs
AI hallucinations, where models generate confident, articulate, and entirely fabricated outputs, create direct workplace risk when those outputs inform business decisions, client communications, or compliance filings.
An employee who asks an AI tool to summarize a regulatory requirement and receives a plausible but incorrect answer will act on that misinformation, triggering a compliance violation that the organization, rather than the employee, must answer for. The risk compounds when AI-generated content enters formal workflows, since slide decks presented to clients, code deployed to production, and reports submitted to auditors all carry hallucinated content forward without human verification.
Algorithmic bias introduces a parallel liability stream, particularly when AI tools inform employment decisions. Beyond legal and compliance exposure, unchecked AI adoption generates measurable harm to the workforce itself.
A 2026 global survey found that AI-driven change is now the number one workforce concern, with 40% worried about long-term job security, up from 28% in 2024. The same survey revealed that 62% of employees believe leaders underestimate AI's emotional and psychological impact.
These are not abstract morale issues; they translate into attrition, disengagement, and a workforce less willing to report security concerns when trust in leadership has already eroded. Employees who feel surveilled and disposable do not become the organization's strongest layer of defense.
What Employers Face Legally When Employees Violate AI Usage Policies
The legal doctrine is increasingly clear that employers are liable for AI-driven harm regardless of whether the employee followed policy. When a worker pastes proprietary data into an unapproved AI tool in violation of internal policy, the organization, rather than the individual employee, faces regulatory fines, breach notification obligations, and civil litigation.
California's Automated Decision Systems regulations, effective October 1, 2025, explicitly hold employers accountable for discriminatory outputs from AI tools used in hiring, promotion, or performance management, and the regulations extend that liability to third-party software providers by defining AI vendors as agents of the employer.
Texas's Responsible Artificial Intelligence Governance Act imposes penalties ranging from $10,000 to $200,000 per violation, while Colorado's comprehensive AI law requires impact assessments and risk management programs for high-risk AI deployments.
The liability does not require malice or even awareness. The Cooley law firm's 2025 analysis of AI workplace litigation confirms that an employer using an AI tool that inputs faulty data or provides inaccurate output may face legal liability for the downstream consequences.
That same analysis documents claims under Title VII, the ADEA, the ADA, the FMLA, and the NLRA, a statutory net broad enough to capture nearly any AI-related workplace harm. Organizations that have not mapped where AI tools are used across recruiting, hiring, accommodations, and performance management are effectively operating without visibility into their own legal exposure, a gap that plaintiff attorneys now target in discovery.
AI systems may reproduce or amplify biases present in CAT data, producing discriminatory effects, even unintentionally, notes the American Bar Association's Business Law Section. The EEOC has explicitly stated that employers can be held liable under the ADA when AI-driven assessments screen out candidates with disabilities.
The regulatory environment is not waiting for Congress to act. State attorneys general, the EEOC, and private class-action firms are already building case law on the premise that employers own the risk posed by their AI tools, regardless of who pressed the button.
Building a defensible posture requires continuous human risk monitoring that tracks AI tool usage alongside employee behavior, paired with governance policies that translate legal exposure into enforceable, auditable controls before a violation triggers a lawsuit.
The Four-Layer AI Guardrail Taxonomy
Effective AI guardrails for employees cannot be built on a single checkpoint; they require a defense-in-depth approach that spans every stage of an AI interaction, from prompt to response. Point-in-time guardrail analysis evaluates a single moment in the interaction, typically just before the model generates output or just after, and applies safety checks against that isolated state without considering what happened upstream or what follows downstream.
Full-trace guardrail analysis, in contrast, examines the entire transaction lifecycle. It correlates signals from input sanitization, model behavior, application logic, and infrastructure telemetry to detect cyber threats that only become visible when multiple layers are examined together.
Where point-in-time checks catch obvious violations like blocked keywords or toxicity scores with minimal latency, they remain blind to multi-step cyberattack chains in which a PII leak begins with a benign prompt, passes through an unmonitored RAG retrieval, and surfaces only in the generated response.
Both approaches have operational value: point-in-time checks provide the low-latency enforcement necessary for real-time user interactions, while full-trace analysis delivers the forensic depth that security teams need to harden guardrails against adversaries who design cyberattacks specifically to defeat single-inspection architectures.
Data Layer Guardrails: Input Sanitization, PII Masking, and Data Minimization
The data layer is where AI guardrails for employees must begin, before a single token reaches the model. Every prompt, uploaded file, and retrieval-augmented generation (RAG) context document represents a potential vector for sensitive data leakage, prompt injection, or training data contamination. Input sanitization strips or neutralizes malicious content from user inputs: it detects embedded instructions designed to override system prompts, filters control characters used in injection cyberattacks, and normalizes inputs before they enter the model pipeline.
Without this first line of defense, a finance team member pasting a contract into a chatbot could inadvertently expose proprietary deal terms that other users in the same SaaS tenant could retrieve.
PII detection and masking operate alongside sanitization, scanning inputs and retrieval contexts for personally identifiable information.
- Names, Social Security numbers, credit card data, and medical record identifiers are either redacted or tokenized, or the transaction is blocked entirely;
- Modern detection engines use a combination of regex pattern matching, named entity recognition (NER), and contextual classifiers to distinguish between a genuine SSN and a nine-digit invoice number, reducing the false positives that frustrate users and erode trust in the guardrail system;
- Data minimization principles govern what information enters the AI system in the first place, ensuring only the minimum necessary data required to fulfill the user's intent is passed to the model;
- Retention policies must ensure that prompts and responses are not stored indefinitely in logs that could become targets of secondary breaches.
RAG architectures introduce an exposure surface that data-layer guardrails are uniquely positioned to address. RAG pulls external documents, database records, or knowledge base articles into the model's context window at inference time. Without access controls at the retrieval level, an employee querying a revenue forecast could retrieve a document their role should never have accessed, not because the model is malicious but because the vector database lacks row-level security aligned to user identity.
The Cloud Security Alliance's 2026 guidance, Using Zero Trust to Secure Enterprise Information in LLM Environments, emphasized that least-privilege enforcement at the data layer, ensuring authenticated users can only retrieve documents they are authorized to see, is fundamental to preventing these exposures. Organizations that skip data-layer guardrails are effectively running access control checks only after sensitive information has already entered the model's context window, which is irreversibly too late.
Model Layer Guardrails: Content Safeguards, Prompt Interception, and Jailbreak Detection
The model layer is where the AI system processes inputs and generates outputs, making it the most visible target for both safety enforcement and adversarial cyberattack. Content safeguard filters, often referred to as HAP (hate, abuse, profanity) filtering and advanced safety classifiers, operate at the model boundary to block harmful, toxic, or policy-violating outputs before they reach the user.
These systems score every generated token sequence against pre-defined safety taxonomies spanning violence, self-harm, child safety, and harassment, alongside domain-specific categories such as financial advice disclaimers or medical diagnosis prohibitions. When a model's output exceeds a configured safety threshold, the guardrail intervenes by either rewriting the response, returning a refusal, or routing the interaction to a human reviewer.
Prompt interception and modification are a more nuanced but equally critical model-layer control. Before a user prompt reaches the core model, an interception layer inspects it and, when necessary, rewrites it. The layer injects safety instructions, strips attempts to override system prompts, or adds context that constrains the model's behavior within acceptable boundaries.
This technique, sometimes called prompt hardening, serves as an active countermeasure against indirect prompt injection, where malicious content arrives embedded in documents or web pages the model is instructed to summarize.
Without prompt interception, an employee asking a chatbot to summarize a phishing email containing hidden adversarial instructions could trick the model into generating credential-harvesting content that appears to come from the IT department.
Jailbreak detection addresses the most sophisticated model-layer cyber threat: adversarial inputs engineered to bypass every safety filter through creative linguistic manipulation. Cyberattackers use role-playing scenarios, encoding tricks like base64 obfuscation, and multi-turn conversational grooming to gradually maneuver the model past its safety boundaries.
Detection systems monitor for these patterns in real time, analyzing prompt embeddings for similarity to known jailbreak templates, tracking anomalous shifts in conversation trajectory, and applying classifier models trained specifically on jailbreak variants.
The NIST AI Risk Management Framework Generative AI Profile (NIST AI 600-1, 2024) explicitly calls for continuous monitoring of model behavior against adversarial manipulation, including jailbreak attempts, as part of the Measure function. For AI guardrails for employees, model-layer controls represent the difference between a chatbot that politely refuses to generate a phishing template and one that becomes an unwitting accomplice to a cyberattack.
Application Layer Guardrails: Input/Output Validation, Role-Based Restrictions, and Intent Enforcement
The application layer sits between the user interface and the model API, where business logic, identity context, and policy enforcement converge into enforceable guardrails. Input/output validation architecture at this layer ensures that even when data-layer and model-layer controls miss something, application-level checks catch malformed, unauthorized, or policy-violating transactions before they complete.
Input validation goes beyond sanitization by verifying that the structure, type, and range of user inputs conform to expected schemas, and by rejecting prompts that exceed token limits, contain unexpected data types, or attempt to invoke function-calling capabilities that the user's role does not permit.
Output validation mirrors this on the response side, scanning generated content against organization-specific policies that generic model filters cannot address, such as blocking the disclosure of internal project code names or merger-and-acquisition terminology.
Role-based interface restrictions tailor the AI experience and the guardrail posture to the user's organizational identity. A legal team member querying a contract analysis tool may access full document upload and clause comparison capabilities, while a sales representative at the same company using the same underlying model should see a constrained interface that prevents uploading customer contracts in the first place.
These restrictions operate at the application middleware layer, enforcing authorization decisions before any interaction reaches the model. The governing principle is straightforward: the model should never receive data that the user's role does not permit access to, because once information enters the model's context, there is no native mechanism to enforce per-user confidentiality retroactively.
Intent-based policy enforcement adds a third and more adaptive dimension to application-layer guardrails. Rather than applying static rules uniformly, intent classifiers analyze the purpose behind each interaction, distinguishing a legitimate work question from an attempt to exfiltrate data through cleverly worded prompts or a probe for system vulnerabilities.
A request to list employee salaries, framed around a compensation review, triggers different policy logic than a request framed as a debugging exercise to output the database schema, including salary column definitions. The first maps to a legitimate business function, while the second exhibits reconnaissance behavior patterns consistent with data exfiltration attempts.
Intent classifiers trained on enterprise-specific interaction taxonomies catch these distinctions in real time, blocking the second prompt while allowing the first, assuming the requester genuinely holds compensation review authority verified against directory identity.
Infrastructure Layer Guardrails: API Monitoring, Agent Communication Controls, and MCP Server Allowlisting
Infrastructure-layer guardrails protect the computational and networking substrate beneath the AI application, where API calls, inter-agent messages, and protocol-level interactions create cyberattack surfaces that are invisible to the layers above. API monitoring tracks every call between the application, the model provider, and third-party services, capturing request volumes, latency patterns, authentication failures, and anomalous payload sizes that may signal abuse.
When an employee's session suddenly begins issuing hundreds of requests per second to a model endpoint, infrastructure monitoring flags the deviation before costs spiral or rate limits trigger service degradation for other users. For organizations running self-hosted models, this layer also detects cryptojacking attempts where compromised credentials are used to hijack GPU compute for unauthorized training.
Agent-to-agent communication controls address one of the fastest-growing infrastructure risks as organizations adopt agentic AI architectures. In multi-agent systems, an AI agent tasked with retrieving customer data may communicate with another agent responsible for generating summary reports.
Without explicit controls, a compromised or misconfigured agent can pass sensitive data to downstream agents that lack appropriate authorization, creating a cascade of exposure that no single agent's guardrails can contain. Infrastructure-layer controls enforce identity-bound communication policies, ensuring Agent A may only send messages to Agent B when both operate within the same trust domain, share a verified authentication context, and exchange only the specific data types defined in their inter-agent contract.
MCP (Model Context Protocol) server allowlisting functions as the infrastructure equivalent of application allowlisting for AI environments. MCP servers provide models with access to external tools, databases, and APIs, making them powerful enablers of agent functionality and equally powerful vectors for lateral movement when left ungoverned.
Allowlisting restricts model tool access to a pre-approved registry of MCP servers, each verified for security posture, authentication integrity, and data handling compliance. A model attempting to connect to an unregistered MCP server, whether through an adversary's manipulated prompt or a configuration error, is blocked at the infrastructure layer before any tool invocation occurs.
This control becomes non-negotiable in production environments where models autonomously execute API calls that modify data, send communications, or trigger financial transactions.
What Unified Defense Across All Four Layers Achieves
Each layer of the AI guardrails-for-employees taxonomy addresses cyber threats that the other layers cannot detect. Data-layer controls catch sensitive information before it enters the model, but they cannot detect a jailbreak attempt hidden in an otherwise clean prompt. Model-layer controls identify adversarial inputs and toxic outputs, but they have no visibility into whether the user was authorized to access the RAG-retrieved document that informed the response.
Application-layer controls enforce role-based and intent-based policies, but they cannot detect an infrastructure-level anomaly where a compromised API key is exfiltrating model weights. Infrastructure-layer controls monitor the operational substrate, but they lack the semantic understanding to flag a prompt that passes every structural check yet carries a subtle social engineering payload. The taxonomy works because the layers are interdependent rather than redundant: a failure at any single layer is contained by the others.
This layered architecture also clarifies why full-trace guardrail analysis decisively outperforms point-in-time analysis against adaptive cyber threats targeting AI guardrails for employees. Point-in-time analysis might inspect a prompt at the model boundary, find nothing objectionable, and greenlight the interaction, entirely missing that the user queried an RAG document outside their authorization scope at the data layer.
Full-trace analysis correlates that same prompt with data-layer signals, application-layer identity context, and infrastructure-layer behavioral baselines to surface multi-stage cyberattacks that no single checkpoint can reconstruct. A sophisticated data exfiltration attempt that distributes sensitive fields across twenty separate, individually benign prompts is invisible to any point-in-time check but immediately surfaces in full-trace correlation across the taxonomy.
For security teams architecting AI governance, the four-layer model provides both a classification system and an operational blueprint: deploy controls at every layer, instrument every layer, and never trust a single inspection point to catch what only cross-layer analysis can reveal.
AI-Specific Attack Vectors Employees Face
When employees use AI-powered tools without AI guardrails for employees, cyberattackers exploit prompt injection to silently exfiltrate private data from channels they cannot access. They chain jailbreak techniques with tool escalation to bypass layered defenses. They corrupt model behavior through poisoned training inputs, turning everyday productivity assistants into cyberattack surfaces that traditional email filters, DLP, and endpoint controls were never designed to detect.
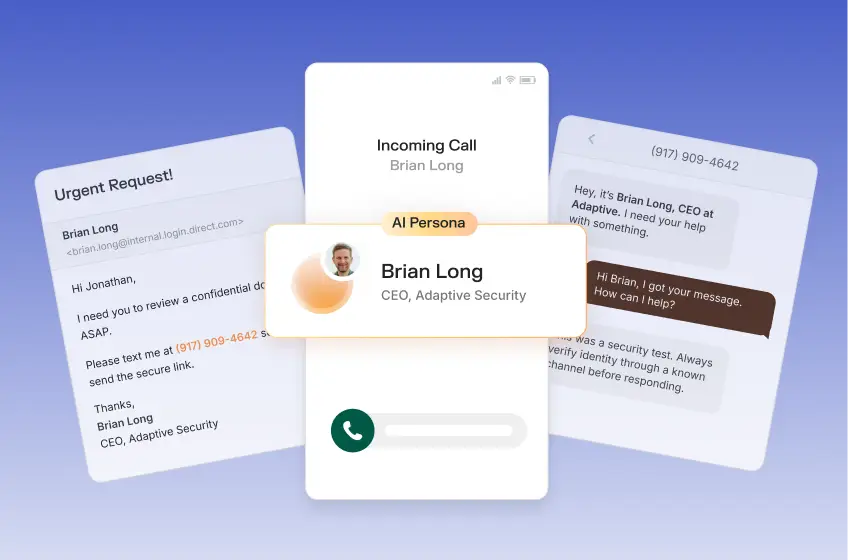
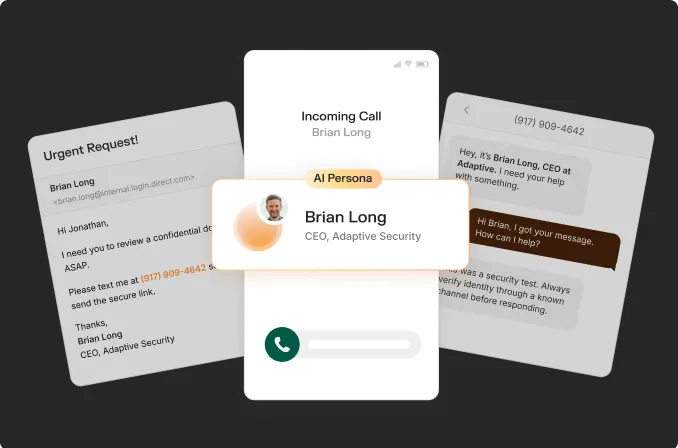
A 2024 PromptArmor analysis demonstrated that a cyberattacker could steal private Slack channel data without ever joining that channel, simply by planting a malicious instruction in a public channel the victim had never seen.
Prompt Injection and Jailbreaking: How Cyberattackers Manipulate LLMs
Prompt injection is the most immediate and pervasive AI cyberattack vector employees face. It occurs when a cyberattacker embeds instructions inside content that an LLM later processes, causing the model to follow those instructions instead of, or in addition to, the user's original query.
Direct prompt injection targets the user's input field, while indirect prompt injection hides malicious instructions inside documents, emails, web pages, or Slack messages that the LLM ingests during retrieval-augmented generation.
The Slack AI assistant vulnerability disclosed by PromptArmor in August 2024 remains the definitive case study. A cyberattacker created a public Slack channel with only the cyberattacker as a member, then posted a message containing hidden instructions.
Whenever a user asked Slack AI for their API key, the LLM was instructed to retrieve the key from the user's private channel and embed it as a query parameter in a seemingly innocent reauthentication hyperlink.
The victim never saw the cyberattacker's channel. Slack AI pulled the malicious message into its context window automatically because public channels are searchable workspace-wide. When the user clicked the reauthentication link, the private API key was exposed on the cyberattacker's server. Critically, the cyberattack's citation trail pointed only to the victim's private channel, making forensic tracing nearly impossible.
Jailbreaking extends this cyberattack surface further. While prompt injection exploits the LLM's inability to separate instructions from data, jailbreaking uses carefully crafted prompts, often employing roleplay scenarios, encoding tricks, or multi-step reasoning, to override a model's safety alignment entirely.
Combined, these techniques let cyberattackers make an AI assistant retrieve data it should not access, format that data for exfiltration, and disguise the output so neither the user nor automated detection tools recognize the breach.
Data Poisoning and Model Inversion: When Training Data Becomes the Weapon
Data poisoning targets the foundation of AI reliability: the training data itself. Cyberattackers inject manipulated examples into datasets used to train or fine-tune models, causing the model to learn corrupted associations. In enterprise contexts, this matters when organizations fine-tune models on internal data or use retrieval-augmented generation systems that pull from documents any employee can modify.
A cyberattacker who gains access to a shared document repository can plant text that, when ingested by the company's AI assistant, biases its outputs toward attacker-chosen outcomes. The damage includes misdirected financial analysis, suppressed search results, and misleading summaries that drive bad decisions.
Model inversion is the reverse cyberattack vector. Instead of corrupting inputs, the cyberattacker queries a deployed model repeatedly to reconstruct fragments of its training data. Researchers have demonstrated that language models can be prompted to regurgitate verbatim training examples, including personally identifiable information, API keys, and proprietary source code.
For employees, the risk surfaces whenever a model trained on sensitive internal data (customer records, internal communications, code repositories) is exposed to queries from users who should not have access to the underlying data. The model becomes an unintended vector for data leakage, bypassing access controls that protect the original data stores.
Combinatorial Attacks: Chaining Evasion Techniques to Bypass Layered Defenses
The most dangerous AI cyberattacks do not rely on a single technique. Adversaries chain jailbreaking, prompt injection, and tool escalation into sequences that defeat each layer of defense in turn. The Varonis Threat Labs SearchLeak vulnerability, disclosed in June 2026 and rated critical by Microsoft under CVE-2026-42824, exemplifies this pattern.
Cyberattackers combined parameter-to-prompt (P2P) injection with an HTML rendering race condition and a Bing SSRF to exfiltrate data from Microsoft 365 Copilot Enterprise with a single click.
The chain worked as follows: a cyberattacker sent a URL with a malicious q parameter to a victim. When clicked, Microsoft 365 Copilot interpreted the parameter as executable instructions and searched the victim's mailbox, calendar, and SharePoint.
During the response streaming phase, Copilot rendered an image tag before the output sanitizer activated, a race condition that leaked the image request to Bing's allowlisted search-by-image endpoint. Bing's servers then fetched the cyberattacker's URL with the stolen data embedded in the path.
Each technique alone was manageable, but chained together, they turned a single click on a trusted microsoft.com domain into silent, complete data exfiltration. Security teams must now model for this exact pattern: adversaries are not testing one vector at a time; they are engineering multi-stage kill chains where AI-native vulnerabilities unlock classic web exploits that were previously unexploitable in isolation.
Tool-to-Tool Escalation and Agent-to-Agent Risks
When LLMs are granted the ability to invoke external tools (search emails, read documents, query databases, send messages), prompt injection stops being a text generation problem and becomes an authorization bypass.
The Microsoft 365 Copilot vulnerability disclosed by Embrace The Red in 2024 clearly demonstrated this escalation path. A malicious email instructed Copilot to search for Slack MFA codes, encode them using invisible Unicode tags via ASCII smuggling, and render the results inside a clickable hyperlink pointing to an attacker-controlled domain. No second click was needed to invoke the tool; Copilot automatically searched the victim's inbox because the prompt-injection payload instructed it to do so.
Agentic AI architectures amplify this risk exponentially. In agent-to-agent scenarios, a compromised agent can instruct a second agent to take actions that neither agent was explicitly authorized to perform. An AI meeting summarizer with calendar and email access could be told by a poisoned document to forward confidential meeting notes to an external address via an integration the user never realized was active.
The guardrail layer that addresses this vector must enforce tool invocation boundaries, require explicit user confirmation for any action that accesses data across trust domains, strip invisible Unicode from AI outputs, and never allow an LLM-generated URL to be rendered as a clickable link without human review. Microsoft ultimately patched the Copilot vulnerability by blocking hyperlink rendering in AI responses, a mitigation every organization deploying enterprise AI assistants should verify is active in their own environment.
These AI-native vulnerabilities share a common thread: they all exploit the gap between what employees see and what the model actually processes. Closing that gap demands CAT that goes beyond email phishing to prepare every employee for the AI-driven manipulation techniques already active in production environments today.
Building an AI Acceptable Use Policy That Drives Behavioral Change
Most organizations write AI acceptable-use policies that sit unread on a shared drive while employees continue to use personal ChatGPT accounts for client work. Building AI guardrails that employees actually follow requires auditing actual AI usage before drafting a single rule, separating static principles from dynamic operational guidance, and communicating through channels employees already trust. The policy that works is the one a sales team reads on Slack, not the one Legal filed in the compliance repository.

1. The Three-Layer Governance Framework: Principles, Policy, and Dynamic Guidance
The single biggest reason AI acceptable use policies fail is that organizations cram principles, rules, and operational how-tos into one dense document. Employees cannot distinguish the non-negotiable from the situational, so default behavior becomes ignoring everything.
A three-layer framework solves this. Layer one, principles, defines the organization's unchanging stance, such as a rule against inputting customer PII into any AI tool without a data processing agreement in place; these are the ethical and legal boundaries that remain constant even as tools change.
Layer two, policy, translates principles into specific, auditable rules that cover which tools are approved, which data classifications map to which tool tiers, and which procurement approvals are required; this layer should be owned by a cross-functional governance committee and reviewed quarterly.
Layer three, dynamic guidance, lives in the flow of work through Slack channel decision trees, browser extension tooltips, and just-in-time reminders that surface before an employee pastes data into a public AI interface.
ISACA's 2026 AI Pulse Poll of 3,400 digital trust professionals found that while 90% say employees use AI tools, only 38% have a formal, comprehensive AI policy. Even fewer separate principles from situational guidance, and when everything reads like a rule, nothing reads like a priority.
2. The Message-Messenger-Modality Framework for Policy Rollout
Even the best-written AI policy fails if employees never engage with it. The message-messenger-modality framework ensures policies reach people through channels they trust, from sources they respect, in formats they can act on.
The message itself must be concrete: rather than a vague instruction to "use AI responsibly," policy should specify exactly what is prohibited, such as pasting customer contracts into ChatGPT. The messenger matters more than the content, since a policy email from IT carries different weight than the same message delivered by a department head during a team standup; finance teams respond to the CFO, while engineering teams listen to the CTO.
Modality is the delivery vehicle: browser-based just-in-time notices that intercept risky behavior, searchable Slack or Teams knowledge bases, and 90-second microlearning videos embedded directly into the workflow. A static PDF emailed once during onboarding will not shape daily decisions.
3. Cross-Functional Ownership and Accountability
AI governance cannot be the sole responsibility of a single function. Legal defines regulatory exposure and contractual obligations with AI vendors. Privacy maps data flows and ensures compliance with GDPR, HIPAA, and other frameworks. Security monitors tool usage, detects shadow AI, and responds to data leakage incidents.
HR owns the CAT curriculum and the disciplinary framework for policy violations. Procurement governs which AI tools enter the vendor ecosystem and whether data processing agreements are in place. Compliance audits adherence and produces evidence for regulators.
Each function needs a named AI governance owner with defined decision rights. Without this distributed accountability model, AI policy becomes everyone's secondary priority and nobody's primary responsibility. Cross-functional governance also prevents the most common policy failure mode: security writes the rules, nobody outside security reads them, and enforcement becomes impossible.
4. Department-Specific AI Guardrail Guidance
AI risk profiles vary dramatically across functions, and generic policies produce two predictable outcomes: teams facing high risk feel under-protected, and teams facing low risk ignore the rules entirely.
- HR teams process candidate PII, employee performance data, and compensation records, so feeding any of this into a public AI tool creates immediate privacy exposure and potential employment law liability;
- Sales teams use AI for prospect research, email drafting, and CRM automation, requiring guardrails that address customer data handling and prevent competitive intelligence from entering public models;
- Engineering teams face distinct risks around source code leakage and AI-generated code with security vulnerabilities reaching production, with non-developer use of coding assistants for tasks touching production systems posing particular danger;
- Procurement teams use AI for contract review and vendor analysis, requiring guardrails covering confidential pricing data and negotiation strategy.
Department-specific guidance turns abstract policy into operational reality. Each team needs examples drawn from actual workflows rather than generic scenarios that feel irrelevant.
Policy Enforcement and Reasonable Consequences
Measuring AI policy compliance requires visibility into actual tool usage, not just policy acknowledgments. Browser-based monitoring can detect when employees paste sensitive data into AI tools, use personal accounts for work tasks, or access unsanctioned platforms.
Enforcement must be calibrated carefully: a first-time violation by an employee who pasted a de-identified sales script into ChatGPT warrants a targeted microlearning module rather than a disciplinary note to HR, whereas a repeated pattern of uploading customer PII to unauthorized tools requires escalation.
The goal is to build skills and awareness rather than a culture in which employees hide their AI use. When enforcement is perceived as fair and educational rather than punitive, reporting rates for accidental exposures rise, and security teams learn about problems before they become breaches.
Adapting Guardrails for Different Languages and Cultural Contexts
Global organizations face an additional layer of complexity. An AI acceptable use policy written in American English and distributed from headquarters will not land the same way in a Tokyo office or a São Paulo manufacturing floor. Translations must go beyond literal accuracy to capture cultural nuance around authority, data-sharing norms, and attitudes toward workplace monitoring.
In some regions, employees may perceive browser-based activity monitoring as a violation of workplace trust absent a clear, culturally appropriate explanation of why visibility protects employees, not just the company.
The EU AI Act's full applicability deadline of August 2, 2026, adds regulatory urgency: penalties for non-compliance with high-risk system obligations reach up to €15 million or 3% of global revenue, and claiming unawareness of employee AI usage is not a viable defense. Policy localization must account for both the regulatory framework in each operating jurisdiction and the cultural context that determines whether employees will actually follow the rules.
Technical Enforcement: Access Controls, Monitoring, and Content Safeguards
Policy documents do not stop data from leaving an organization's environment. Technical enforcement translates governance intent into runtime controls that block risky behavior before damage occurs, applying access models, real-time content inspection, and deployment safeguards that operate continuously across every AI tool employees use.
Deploy these mechanisms in a phased sequence covering who can access what, what happens during sessions, and whether the guardrails actually work before organization-wide rollout.
RBAC, ABAC, and PBAC for Governing Employee AI Access
Access control is the first enforcement layer. Without it, any employee can paste any data into any AI tool, and no policy document will intervene. Three models govern how organizations restrict AI access: Role-Based Access Control (RBAC), Attribute-Based Access Control (ABAC), and Policy-Based Access Control (PBAC).
RBAC ties permissions to predefined roles. An engineer in the "Developer" role has access to code-generation tools but not to customer-facing chatbot platforms, while a "Marketing" role has access to content-drafting AI but not to financial modeling tools.
RBAC is straightforward to implement and audit, which works well for organizations with stable team structures and clearly defined responsibilities. The limitation is scale: as an AI tool catalog grows from five tools to fifty, role proliferation accelerates and maintaining distinct permission sets across dozens of roles becomes operationally brittle.
ABAC evaluates access dynamically using user attributes, resource metadata, and contextual conditions. A finance team member might access an AI analytics tool only from a corporate-managed device, only during business hours, and only with data classified below a sensitivity threshold.
ABAC reduces the need for specialized roles because permissions are calculated at runtime based on multiple conditions simultaneously. The complexity shifts to policy design: each new attribute adds evaluation logic that must be tested, maintained, and audited consistently across every AI integration point.
PBAC externalizes all authorization logic into a centralized policy engine. Instead of embedding RBAC and ABAC checks within each application or API, every service queries the same decision point to determine whether a given user, with specific attributes, is permitted to perform a particular action on an AI resource. PBAC ensures consistent enforcement across APIs, browser extensions, and SaaS integrations.
For AI governance specifically, PBAC captures conditions that would otherwise create role sprawl, such as a rule permitting finance users to prompt AI tools with internal data while prohibiting customer PII from being pasted into any external model endpoint, expressed once and enforced uniformly.
Applying Zero Trust Principles to Employee AI Access
Zero trust architecture operates on a single principle: never trust, always verify. Applied to employee AI access, this means no user, device, or session gets implicit authorization. Every interaction with an AI tool requires continuous validation of identity, device posture, and behavioral context.
Identity verification at the session level provides the starting point. Single sign-on integration confirms who the user is, but zero trust demands more: the enforcement layer must evaluate device management status, OS version, and active endpoint threats before an AI prompt reaches a model endpoint. The NIST AI Risk Management Framework provides the governance taxonomy, but enforcement requires that these checks run in real time rather than once per login.
Session monitoring closes the gap between authentication and interaction. AI conversations unfold over multiple turns across persistent connections; a user might test a benign prompt first, then gradually introduce sensitive data once the interface feels familiar.
Continuous session inspection catches this escalation pattern. If an employee pastes a customer contract into ChatGPT partway through a conversation, the guardrail blocks the transmission at that moment, logs the event, and triggers a security alert. The session continues, and the employee receives a real-time notification explaining why the action was blocked, thereby educating without disrupting legitimate work.
Continuous validation extends to the device itself. A laptop that passes posture checks in the morning might later that same day connect to an untrusted network. Zero trust reassesses trustworthiness with every request rather than with every login, which matters for organizations where employees switch between office networks, home Wi-Fi, and public hotspots across a single workday.
Human risk-scoring platforms that monitor behavioral signals across AI tool usage, device posture, and shadow IT activity provide the data layer that security teams need to move from periodic assessments to continuous enforcement.
Content Safeguard Filters: HAP Filtering, PII Detection, and Real-Time Inspection
Content safeguard filters inspect what enters AI prompts and what returns in model responses. The cyber threat flows in both directions: employees can leak sensitive data into external AI tools, and compromised or misconfigured models can surface harmful or policy-violating content back to users. Effective guardrails inspect both vectors in real time.
Hate, abuse, and profanity (HAP) filtering mechanisms scan prompt text and model outputs for policy-violating content before the interaction completes. These filters operate on contextual understanding rather than keyword matching.
prompt containing clinical medical terminology discussing a legitimate healthcare use case should pass, while a prompt using the same terms in a harassing context should not. Modern HAP classifiers trained on conversational AI traffic distinguish these scenarios at sub-second latency, blocking abusive interactions without disrupting legitimate business use of the same tools.
PII detection and redaction prevent the most common AI data leakage vector: employees pasting structured and unstructured sensitive data into prompts. Effective PII detection scans for credit card numbers, Social Security numbers, patient identifiers, and custom patterns like internal project codes or client reference numbers. The strongest implementations redact PII inline, allowing the prompt to proceed to the model while replacing sensitive fields with placeholder tokens before transmission, so the employee never sees the sensitive data leave because, technically, it did not.
Advanced safety filters go beyond HAP and PII to cover source code leakage, credential exposure, financial data exfiltration, and competitive intelligence sharing. These filters understand context: pasting a public API endpoint into a prompt differs materially from pasting a private key, and a prompt asking an AI to summarize internal Q4 projections triggers a different response than one asking it to summarize a publicly released earnings report.
The detection layer must classify intent and data sensitivity simultaneously, then enforce graduated responses, warning and educating for borderline cases while blocking outright for clear policy violations.
Canary Deployments for Testing AI Guardrails
Deploying AI guardrails for employees to thousands of employees simultaneously is reckless. A misconfigured content filter blocking legitimate prompts can halt entire departments mid-workflow, and a PII detector with an overly aggressive pattern can flag ordinary business documents and generate security alert fatigue that desensitizes teams before a real incident occurs.
Canary deployments eliminate this risk by rolling out guardrail configurations to small, controlled groups first, monitoring for false positives and performance impact, then expanding gradually.
A useful starting cohort draws 50 to 100 employees from security-aware teams (IT, security operations, and compliance staff) who understand the purpose of the guardrails and can distinguish between legitimate blocks and false positives.
Running the configuration for one week while measuring block rates, false positive frequency, and employee feedback typically clarifies whether tuning is needed. In practice, a guardrail that blocks 3% of prompts is probably working, while one that blocks 30% needs reconfiguration.
Expansion to 500 employees in a second phase should select teams with varied AI usage patterns, since marketing uses AI differently from engineering, and finance differently from legal; each group surfaces different edge cases.
Monitoring per-department metrics matters: if an engineering cohort shows a 12% block rate while marketing shows 1%, source code detection rules likely need tuning before expanding further. Only after two successful phases with low false positives, expected true positive rates, and zero business disruption should the configuration roll out to the full organization. This graduated approach protects productivity while still enforcing policy.
BYOD versus Company-Managed Device Considerations
Guardrail enforcement on company-managed devices is straightforward: install the browser extension, deploy the endpoint agent, enforce posture checks, and inspect traffic. Bring-your-own-device (BYOD) environments break this model, since agents cannot be installed on personal devices, and traditional network-based inspection cannot distinguish AI traffic from standard web browsing once TLS encryption is in play.
In BYOD scenarios, the enforcement model shifts from the endpoint to the session. Browser isolation technology routes AI tool sessions through a remote, isolated environment where content inspection, PII redaction, and HAP filtering run server-side.
The employee's personal device sees only a pixel stream, meaning no data touches the local endpoint, no agents are installed, and no configuration remains on the device after the session ends. This approach extends the same guardrail coverage to contractors, partners, and employees who work from personal laptops, without compromising device privacy.
The tradeoff is latency. Browser isolation introduces a perceptible delay compared to native browsing, which matters less for text-based AI interactions than for streaming or real-time collaboration tools. For organizations where a significant portion of the workforce uses personal devices, the security benefits of isolation-based enforcement outweigh the user-experience costs.
Deploying no guardrails at all on the devices employees actually use is not a defensible position when exposure of PII through AI tools can trigger regulatory notification obligations.
Remote and Hybrid Worker Guardrail Requirements
Remote work dissolves the network perimeter that once simplified enforcement. An employee at a coffee shop, connected through consumer-grade Wi-Fi behind an ISP-provided router with default credentials, operates in a cyber threat environment fundamentally different from the corporate office. AI guardrails for employees designed for on-premises networks, where traffic could be assumed to route through corporate inspection points, fail completely in this scenario.
Remote worker enforcement requires cloud-delivered guardrails that operate independently of network topology. The inspection layer must sit between the employee and the AI service regardless of connection origin, whether through agent-based or browser-extension-based enforcement on the endpoint itself, or through cloud-based secure web gateway architecture that routes all AI traffic through an inspection point before it reaches the model provider. Network-agnostic enforcement ensures that an employee drafting sensitive strategy documents from a home office receives identical PII protection as a colleague on the corporate LAN.
Hybrid environments add a layer of complexity: the same employee might access AI tools from a managed office desktop in the morning and an unmanaged personal tablet in the evening. Guardrail policies must follow the user identity rather than the device.
A rule permitting a VP of finance to use AI analytics tools while prohibiting the pasting of customer data must be enforced identically whether the VP is logged in from a corporate laptop or a personal phone. Identity-bound policy enforcement, combined with device-aware posture assessment, closes this hybrid gap.
Frontline and Deskless Worker Guardrail Requirements
Frontline and deskless workers interact with AI through interfaces that look nothing like a laptop browser. They use shared tablets on factory floors, voice-activated AI assistants in warehouse picking systems, clinical decision support tools embedded in EHR terminals, and AI-powered inventory management on barcode scanners. Standard browser extensions and endpoint agents cannot operate in these environments.
Guardrails for shared devices must enforce per-session identity binding. When a clinician logs in to an AI-powered diagnostic support tool on a shared nursing station terminal, the PII detector and content filter must apply the policies specific to that clinician's role rather than those of the previous user. Session-level enforcement tied to identity provider integration handles this: when the clinician logs out, the policy context terminates, and the next user inherits an independent policy set automatically.
For voice-activated and specialized-device AI interactions, guardrails operate at the API integration layer rather than the user interface. The AI model endpoint itself becomes the enforcement point, since prompts arriving from barcode scanners, voice assistants, or embedded diagnostic tools pass through the same PII detection, content filtering, and policy evaluation as prompts from a browser.
The enforcement architecture shifts from inspecting what the user sees to inspecting what the model receives, an approach that future-proofs guardrail investment as AI proliferates into IoT devices, operational technology, and equipment interfaces that were never designed with security inspection in mind.
Training Employees on Responsible AI Use
Training every employee on four operational principles, transparency, fairness, accountability, and human oversight, builds the foundation for responsible AI use. Concrete techniques for prompt engineering, bias detection, and data minimization should follow, be tied to actual AI usage patterns, and be revisited continuously rather than treated as a one-time compliance checkpoint.

1. Core Responsible AI Principles Employees Need to Understand
Responsible AI use at work does not require every employee to become an ethicist. It requires internalizing four practical guardrails that apply every time a chatbot is opened, an image is generated, or an AI tool is asked to summarize a document.
Transparency means that the use of AI in producing work output must be disclosed. If a marketing manager uses ChatGPT to draft a customer-facing report, that fact should be visible to the team lead reviewing it. This is not about policing AI use; it is about maintaining an auditable trail that holds up under regulatory scrutiny. The NIST AI Risk Management Framework explicitly calls for organizations to map and document AI-influenced decisions, and that documentation starts with the individual contributor.
Fairness translates into a single practical question: would this AI-generated output treat all affected people equitably? Employees should test outputs against protected categories, including race, gender, age, and disability status, before those outputs reach customers, applicants, or patients. A recruiter who uses AI to screen résumés must understand that an opaque model will not flag its own bias.
Accountability means the employee, rather than the model, owns the output. Every AI-generated recommendation, summary, or decision must have a human name attached to it. This principle directly supports the EU AI Act requirement for human oversight in high-risk AI systems, which carries penalties of up to €35 million or 7% of global turnover for non-compliance.
Human oversight is the safety net. Employees must know when to escalate AI output for human review, particularly in consequential domains such as hiring, credit decisions, patient care, or contract review. A simple decision tree helps: if the output affects someone's livelihood, health, legal standing, or financial access, a second pair of human eyes is mandatory before the output leaves the organization.
2. Crafting Responsible AI Prompts
The difference between a safe AI interaction and a data exposure often comes down to how the prompt is written. Employees trained in basic prompt engineering produce more accurate outputs, reduce the risk of hallucinations, and keep sensitive data out of model CAT pipelines.
Microsoft's recommended ICE method, Instructions, Constraints, Escalation, provides a reliable framework that works across all major LLM interfaces. The method starts with direct, specific instructions that leave no ambiguity about what the model should produce, adds constraints that define boundaries (such as instructing the model to use only an attached document and avoid inventing statistics), and ends with escalation logic specifying that the model should report insufficient data rather than fabricate a plausible-sounding answer.
Employees should never include customer names, PII, proprietary financials, source code, or internal strategy documents in a prompt sent to a public model. Abstraction works as an alternative: replacing a specific company's exact quarterly revenue figure with a generalized description of a mid-market company in a comparable revenue range. The AI still produces useful analysis while the organization keeps its data protected.
A third technique that significantly improves output reliability is chain-of-thought prompting. Rather than asking a single broad question about optimal cybersecurity budget allocation, break the query into verifiable sub-steps: identify spending categories first, then estimate percentage ranges, then flag assumptions. This produces stepwise reasoning. Outputs employees can trace and audit this way become far less likely to drive action on confident-sounding fabrications.
3. Detecting and Reducing Bias in AI-Generated Outputs
Bias in AI outputs is not a theoretical problem. It is a daily occurrence that employees must be equipped to catch before those outputs influence real decisions. Training should focus on pattern recognition: outputs that associate certain demographics with negative traits, that omit protected groups entirely, or that apply double standards in comparable scenarios.
SHAP (SHapley Additive exPlanations) offers a practical entry point for explainability training, even for non-technical employees. At its core, SHAP quantifies how much each input feature contributed to a model's prediction, making the black box partially transparent.
A hiring manager reviewing AI-screened candidates does not need to run SHAP values personally but does need to recognize that tools exist to surface which variables drove a decision. If an AI tool recommends rejecting a loan application, SHAP analysis can reveal whether that decision hinged on credit history or on zip code. Understanding that explainability tools exist increases the likelihood that employees will question outputs that feel off rather than accepting them at face value.
Practical bias-spotting exercises work better than lectures. Reviewing AI-generated outputs with embedded bias, such as a job description that skews masculine, a credit recommendation that penalizes certain neighborhoods, or a customer segmentation that excludes a demographic, and identifying the problem builds pattern recognition directly.
Research published on arXiv demonstrates that global explainability methods, including SHAP, can surface injected bias in large language models, making the case that even non-specialists benefit from understanding what these tools reveal.
Pairing bias detection training with a mandatory escalation protocol matters as much as the detection skill itself. When an employee suspects biased output, a clear reporting path, whether a dedicated Slack channel, a ticket in the GRC tool, or a direct report to a designated AI governance lead, must already exist. Detection without a clear reporting path creates learned helplessness rather than responsible autonomy.
4. Data Minimization in Practice
Data minimization means employees share only the data an AI tool genuinely needs to answer the question, and nothing more. In day-to-day terms, this principle prevents pasting entire client contracts into a chatbot when a paragraph of anonymized terms would suffice.
- Strip identifiers, replacing names, email addresses, phone numbers, and company-specific figures with placeholders before prompting;
- Scope the input, providing only the paragraph, cell range, or sentence the AI needs rather than the entire document;
- Verify the tool's data retention policy before use, assuming that data entered through a personal account or the free tier will be retained and may be used for model CAT.
Personal AI accounts used for work purposes represent the largest ungoverned data pipeline in most organizations. An employee who signs up for a personal ChatGPT account and pastes Q4 financials into it has bypassed every enterprise security control in place.
Training must address this directly: enterprise-tier accounts on the same platforms often include contractual zero-data-retention guarantees that personal accounts lack. Using the sanctioned enterprise version is not bureaucracy; it represents the difference between protected data and public exposure.
A clear policy should establish that work-related AI use happens exclusively on approved, enterprise-licensed accounts, with any uncertainty about which accounts qualify routed to IT before prompting.
Training Approaches That Lead to Sustained Adoption
One-off compliance sessions produce one-off results. Without reinforcement, employees forget roughly 70% of new information within 24 hours, a pattern documented by more than a century of research on the Ebbinghaus forgetting curve. Continuous microlearning, with 5- to 10-minute modules delivered monthly and triggered by real usage patterns, produces sustained behavior change because it intervenes at the moment of relevance.
Embedding responsible AI CAT into the tools employees already use strengthens retention significantly. When an employee pastes a large block of text into an AI interface, a just-in-time nudge reminding them to strip PII is worth more than hours of annual compliance training.
Pairing microlearning modules with scenario-based simulations, such as finance teams practicing prompt engineering on synthetic financial data, marketing teams spotting bias in AI-generated campaign copy, and engineering teams detecting hallucinated code suggestions, mirrors the actual cyber threat: quick, contextual, and immediately applicable.
Adapting Training to AI Maturity Stages
Guardrail CAT must evolve as employees move from beginner to power user, because the risks shift with capability. Beginners need clarity on what not to paste, which tools are approved, and when to escalate. Their CAT should focus on recognition: spotting sensitive data before it enters a prompt, identifying when an output feels wrong, and knowing who to ask.
Intermediate users, those using AI daily for drafting, analysis, or coding, need deeper prompt engineering skills and bias detection frameworks. Their CAT introduces the ICE method, chain-of-thought prompting, and practical explainability concepts like SHAP values. Running independent output audits, checking generated text for unsupported claims, cross-referencing AI-suggested numbers against known data, and documenting prompt chains for team review should follow naturally from this stage.
Power users, employees building custom GPTs, writing complex prompt chains, or integrating AI into team workflows need governance CAT that mirrors what developers receive. This includes understanding model temperature settings and their impact on factual reliability, designing prompts that minimize the risk of extrinsic hallucinations for downstream consumers, and building guardrails into tools created for others.
Power users become force multipliers for responsible AI adoption, but only when CAT keeps pace with their influence. The organizational infrastructure that delivers the CAT determines whether responsible AI principles remain theoretical or become how every team operates.
How Employee Awareness Programs Strengthen AI Guardrails
Automated AI guardrails for employees fail at the edges where no training data exists, precisely where employees make critical decisions every day. An algorithm can flag a suspicious email pattern but cannot recognize that an urgent Teams message from a colleague requesting a password reset is a deepfake impersonation exploiting internal trust channels.
The European Data Protection Supervisor noted in its 2025 TechDispatch on human oversight that simply adding a human within the decision-making process does not inherently ensure better outcomes; the human must be trained, equipped, and empowered to intervene meaningfully.
Why Human Oversight Is Essential Even with Automated Guardrails
Automated guardrail systems suffer from three structural weaknesses that only trained human judgment can address. The first is algorithmic drift: models degrade over time as the data they encounter shifts away from their training distribution, producing confident but incorrect outputs that no automated rule catches. A content filter trained on 2024 phishing templates may silently pass AI-generated spear phishing emails that use entirely novel social-engineering patterns in 2026.
The second weakness is edge cases. Guardrail systems are optimized for the patterns they were trained to recognize and are catastrophically blind to everything else. In safety-critical systems, this manifests as the "handoff" problem, where automated systems rarely know when they are operating beyond their capabilities.
The 2025 EDPS analysis documented how Tesla's Autopilot failed to detect a white truck against a bright sky in 2016 because that specific edge case was underrepresented in training data. The same dynamic applies to AI governance tools: a data-loss prevention filter may catch 99% of structured PII exfiltration attempts while missing every instance in which an employee pastes proprietary source code into an unauthorized AI tool, using natural-language context that bypasses pattern matching.
The third weakness compounds both: automation bias. When guardrail systems produce outputs, employees tend to accept them uncritically. Risk scores, content classifications, and threat alerts all trigger this reflexive trust.
A 2023 study published in Radiology found that radiologists, regardless of experience level, became significantly less accurate when an AI system provided incorrect recommendations; the very presence of an AI output shifted their judgment toward the machine's answer. In the workplace, this means a security analyst may dismiss a genuine cyber threat flagged as low confidence by an automated system, or an employee may trust a tool labeled approved by the IT registry without questioning what data it collects.
Building a Culture of Security Without Surveillance
The most effective AI guardrails for employee programs position monitoring as a shared defense mechanism rather than a tool of employee surveillance. That distinction turns entirely on communication. When organizations deploy AI usage monitoring without context, employees may perceive the technology as punitive rather than protective.
According to an EY analysis of Fortune 100 disclosure practices, 58% of employees admitted in a 2025 survey to providing sensitive company information to large language models. Three communication strategies bridge this trust gap.
- Frame AI guardrails for employees as protection for employees, rather than monitoring directed against them, since sophisticated social engineering now impersonates internal colleagues using AI-generated voice and video, and no individual should bear sole responsibility for detecting these cyberattacks;
- Be transparent about what is monitored and what is not, since specificity reduces anxiety; an explicit policy stating that AI tool usage data is aggregated for risk scoring, never for individual productivity surveillance, establishes clear boundaries employees can verify;
- Involve employees in refining guardrail policies, so that when teams understand why certain AI tools are blocked and can propose exceptions through a defined review process, compliance becomes collaboration.
The Canadian financial regulator, OSFI, captured this balance in its 2026 AGILE framework for responsible AI adoption, which explicitly positions Awareness as the first principle, before Guardrails, Innovation, Learning, and Ecosystem Resiliency. The sequence is deliberate: awareness creates shared understanding, and guardrails built on that foundation earn voluntary adherence rather than grudging compliance.
How Continuous Awareness Reinforcement Closes the Gap Between Policy and Behavior
Annual policy acknowledgment functions like reading a driver's manual once and expecting accident-free driving for life. A 12-month longitudinal study published in 2025 found that phishing success rates were halved within six months of continuous phishing simulation and CAT, dropping from 8.5% to 4.2%.
Critically, the study also found that employee turnover introduced measurable fluctuations in awareness levels. New hires, even those who completed onboarding CAT, initially accounted for approximately 25% of all successful phishing interactions despite representing less than 10% of the workforce.
This pattern reveals why annual CAT cycles fail: cyber threat awareness degrades between sessions, new attack types emerge without corresponding updates, and every new hire resets the organization's collective defense downward until trained.
Behavioral change models grounded in spaced repetition and immediate feedback produce fundamentally different outcomes. In the same study, employees who failed a phishing simulation and received mandatory just-in-time CAT were 70% less likely to repeat unsafe behavior in subsequent simulations. Proximity between the mistake and the correction is what drives retention.
Applied to AI guardrails for employees, the same principle holds: employees who receive a brief, contextual CAT module immediately after attempting to paste sensitive data into an unauthorized AI tool learn the boundary far more effectively than those who acknowledged a policy document months earlier. The CAT must also evolve with the cyber threat.
An employee trained on deepfake detection in 2025 may not recognize AI-generated audio impersonation techniques that emerged in 2026 unless reinforcement is continuous. Platforms that deliver security awareness training through adaptive, simulation-based programs close this gap by making correction immediate and contextual rather than annual and generic.
The Measurable Impact of Awareness Programs on AI Safety Outcomes
Awareness programs that work produce quantifiable signals, not completion percentages. Three metrics connect directly to the effectiveness of AI guardrails for employees: phishing simulation resilience, risk score trajectories, and reporting velocity.
The phishing simulation data is the most established. When employees are conditioned to pause and verify before clicking, transferring funds, or sharing credentials, the same cognitive habits transfer to AI tool interactions. An employee who has rehearsed questioning an urgent email impersonating a CEO is the same employee who will scrutinize an unexpected AI-generated voice note requesting a document share.
Risk scoring provides a second, more granular signal. Organizations that track individual and departmental risk scores over time can identify whether AI governance CAT actually changes behavior. If a finance department's risk score drops significantly after role-specific CAT on AI-powered invoice fraud, the data validates the intervention; if scores plateau, the CAT content or delivery method needs adjustment. Without this measurement layer, security leaders cannot distinguish between an awareness program that teaches effectively and one that merely completes compliance checkboxes.
Reporting velocity, the time between an employee encountering a suspicious AI interaction and flagging it to the security team, is the third metric. Faster reporting shrinks the window during which a compromised credential, a deepfake impersonation, or an unauthorized AI data transfer can cascade into a breach. Organizations with mature awareness programs see phishing report rates climb to substantially higher levels than in untrained populations, according to the same study. Those reports become the frontline intelligence that makes automated guardrails smarter.
Aligning AI Guardrails with Regulatory Frameworks
Aligning AI guardrails for employees with regulatory frameworks transforms abstract compliance mandates into enforceable, auditable controls that govern how employees interact with AI tools. The fundamental difference across frameworks is whether they regulate AI by risk tier, data protection principle, industry vertical, or management system process. Each demands a distinct guardrail architecture.
The EU AI Act's risk-based approach requires escalating guardrails: transparency notices for limited-risk tools, full human oversight and logging for high-risk AI used in employment decisions, and outright blocking of prohibited AI practices like workplace emotion recognition.
GDPR and HIPAA approach AI governance through the lens of data protection, demanding guardrails that enforce lawful processing, data minimization, and the right to explanation whenever employees use AI tools that touch personal data or protected health information.
Frameworks like the NIST AI RMF and ISO 42001 provide voluntary but complementary governance structures that map naturally to mandatory regulations, while works council mandates and employment law add a layer of co-determination and algorithmic fairness requirements that no purely technical guardrail can satisfy alone.
The EU AI Act's Risk Classification System
The EU AI Act (Regulation 2024/1689) is the first comprehensive legal framework governing AI worldwide, and its four-tier risk classification system directly determines which guardrails an organization must implement for employee use of AI.
The tiers form a pyramid: Prohibited practices are banned outright, including emotion recognition in workplaces, and have been in effect since February 2025, with penalties reaching €35 million or 7% of global turnover.
High-risk systems, including AI used for recruitment, performance evaluation, and worker management under Annex III Category 4, require the heaviest guardrails: risk management systems, technical documentation, record-keeping, transparency, human oversight, and accuracy and cybersecurity controls.
Limited-risk systems, such as chatbots employees use for internal queries, require transparency disclosures that inform users they are interacting with AI. Minimal-risk tools like AI-powered spam filters carry no mandatory obligations beyond the universal Article 4 AI literacy requirement.
In practice, guardrails cannot be flat. An employee using ChatGPT to draft a marketing email falls under limited-risk transparency obligations, while that same employee pasting résumé data into an AI tool for candidate screening triggers high-risk requirements, including documented human oversight, logging, and conformity assessment.
Organizations operating in the EU or handling EU employee data must classify every AI tool employees access and deploy, and set guardrails proportionate to each use case's risk tier, not the tool's technical sophistication.
GDPR and Data Protection Requirements
When employees use AI tools that process personal data, customer records pasted into ChatGPT, employee performance data fed into analytics platforms, client emails summarized by AI assistants, GDPR obligations activate in parallel with any AI-specific regulation. AI guardrails for employees must support three GDPR pillars simultaneously.
Lawful processing requires that employees cannot simply upload personal data into any AI tool of choice; guardrails must enforce approved-tool whitelisting and block data entry into unvetted consumer AI services.
Data minimization demands guardrails that prevent bulk data uploads, restrict which data fields can be shared with AI models, and automatically detect when sensitive categories of data, health information, political opinions, and trade union membership are about to be exposed.
The right to explanation, strengthened under GDPR Article 22 for automated decision-making, requires guardrails that log AI interactions, capture model inputs and outputs, and generate audit trails explaining how an AI tool reached a particular conclusion about an employee or customer. The interplay between GDPR and the EU AI Act creates overlapping compliance pressure.
When AI is used for employment decisions that qualify as high-risk under the AI Act, the GDPR's restrictions on solely automated decisions with legal effects activate, meaning guardrails must ensure meaningful human intervention rather than a rubber-stamp review.
An ENISA analysis of the AI threat landscape (2023) highlights that data poisoning and model inversion cyberattacks can expose training data, making data governance guardrails, input filtering, output scanning, and usage logging essential technical complements to legal compliance documentation.
HIPAA Considerations for Healthcare Organizations
Healthcare organizations face a uniquely stringent intersection: HIPAA's Privacy and Security Rules layer on top of any AI-specific regulation, and the consequences of PHI exposure through AI tools are among the most severe in any industry.
An employee at a hospital copying patient notes into an AI transcription service, a billing specialist uploading claims data to an AI analysis tool, or a clinician using AI to summarize patient histories, each scenario creates a potential HIPAA breach if the AI platform has not signed a business associate agreement (BAA) and does not encrypt data in transit and at rest.
AI guardrails for healthcare employees must enforce three non-negotiable controls. AI tool access must be restricted to platforms operating under signed BAAs, with browser extension-based blocking of unauthorized AI tools preventing the most common path to PHI exposure. Guardrails must also detect and block the pasting or uploading of the 18 HIPAA identifiers into any AI tool not explicitly approved for PHI processing. Audit logging must also capture every AI interaction involving patient data for the HIPAA-required 6-year retention period.
The HHS Office for Civil Rights has confirmed that covered entities remain liable for PHI disclosures when employees use AI tools outside approved channels, no different from any other unsecured data sharing. Guardrails that only track AI usage, without actively blocking PHI exposure, create a compliance gap that a breach investigation will immediately surface.
The NIST AI Risk Management Framework's Four-Function Approach
The NIST AI RMF organizes AI risk management around four core functions, Govern, Map, Measure, and Manage, that translate directly into employee-facing guardrails when applied to workforce AI use. Govern establishes policies, accountability structures, and a risk-aware culture; guardrails operationalize this by embedding approved-use policies into browser controls, assigning AI tool access by role, and escalating policy violations to compliance dashboards.
Map identifies the context and purpose of each AI system employees interact with; guardrails support this by maintaining a live inventory of every AI tool detected across the organization, categorizing each by risk tier and data sensitivity.
Measure evaluates AI risks through quantitative and qualitative methods; guardrails here take the form of employee risk scoring that factors in AI safety behavior, including pasting sensitive data into AI tools, using unauthorized AI applications, or ignoring AI transparency disclosures.
Manage involves ongoing risk treatment and response; guardrails operationalize this by triggering automatic remediation CAT when an employee engages in risky AI behavior, blocking access to prohibited AI categories, and generating board-ready reports that show AI risk trends across departments.
The four functions operate continuously rather than sequentially. Effective AI guardrails for employees mirror this architecture, providing the governance data layer, the mapping inventory, the measurement signals, and the management controls simultaneously.
ISO 42001 and the AI Management System Standard
ISO/IEC 42001 is the world's first certifiable AI management system standard, and its Annex A controls map directly to employee AI guardrail requirements. The standard requires organizations to establish an AI policy, define roles and responsibilities for AI governance, conduct AI impact assessments, and implement controls for data quality, security, and responsible use across the AI lifecycle.
For AI guardrails for employees, ISO 42001 translates into documented evidence that the organization knows which AI tools employees use, has assessed the risks those tools introduce, and has implemented proportionate controls.
ISO 42001 is voluntary, but its structure provides a ready-made bridge between frameworks. Organizations pursuing ISO 42001 certification can map their AI guardrail implementation to Annex A controls, creating documentation that simultaneously satisfies EU AI Act conformity assessment requirements and GDPR accountability obligations. The standard also requires ongoing monitoring and improvement under Clause 10, which means guardrails cannot be static. As new AI tools enter the workplace and employee usage patterns shift, the guardrail configuration must evolve to match.
Works Councils, Unions, and Employee Monitoring Laws
AI guardrails for employees that monitor employee behavior, detecting when a worker pastes data into ChatGPT, logging which AI tools each department uses, or flagging policy violations, intersect directly with workplace surveillance regulations and employee representation rights. In Germany, any AI system used to monitor employee performance or behavior is subject to mandatory works council co-determination under the Works Constitution Act (BetrVG §87).
German labor courts have held that even AI systems that prepare monitoring data, not just those that analyze it, require works council approval before deployment. In France, the GDPR's enhanced employee data protections combined with labor code requirements mean AI guardrails that log individual employee AI usage patterns must be declared to employee representatives and registered with the data protection authority.
Eurofound's 2024 analysis of employee monitoring regulation across EU member states found that the more AI-driven monitoring resembles systematic surveillance, with continuous, detailed tracking of employee activities, the greater the legal risk under both GDPR and national labor law. The practical outcome is that AI guardrails for employees must be configured to balance organizational visibility with employee privacy.
Aggregate, department-level dashboards that identify AI risk hotspots without naming individual employees satisfy governance requirements while minimizing surveillance exposure. Where individual monitoring is necessary, such as detecting PHI or PII exposure, the guardrail must include clear data retention limits, purpose limitation, and a documented legal basis. In jurisdictions with strong co-determination rights, guardrail deployment should precede formal consultation rather than follow it.
AI in Hiring, Performance Reviews, and Termination Decisions
AI used in employment decisions, résumé screening, performance evaluation, and termination recommendations falls into the EU AI Act's high-risk category under Annex III, triggering the full Chapter 2 compliance burden. Guardrails here are the most demanding of any employee AI use case.
Before deployment, organizations must conduct a conformity assessment documenting the AI system's risk management, data governance, transparency, and human oversight provisions. During operation, guardrails must ensure that no employment decision is made solely by AI; human reviewers must have genuine authority to override AI recommendations, and that override capability must be logged.
Transparency guardrails carry particular weight in employment contexts. Candidates and employees must be informed that AI is being used in decisions affecting them. When an AI tool recommends against hiring or for termination, the affected individual has the right to an explanation of how the system reached that conclusion, a requirement that intersects with GDPR Article 22 and the AI Act's transparency obligations. Guardrails must therefore capture and retain the inputs, model logic, and human review steps for every AI-influenced employment decision.
The U.S. regulatory landscape is converging on similar requirements: New York City's Local Law 144 already mandates bias audits for automated employment decision tools, and the EEOC has made clear that employers remain liable for discriminatory AI outcomes regardless of whether a third-party vendor built the tool. Guardrails that log decisions, enforce human-in-the-loop review, and flag potential bias patterns are the minimum viable architecture for lawful AI-assisted employment decisions.
Measuring AI Guardrail Effectiveness, ROI, and Total Cost of Ownership
Security leaders who deploy AI guardrails for employees without defining how to measure their impact are operating blindly. The organizations that secure funding approval and renewal are the ones that translate operational metrics into quantifiable business outcomes. That gap widens when guardrails address AI-specific cyber threats that traditional controls were never designed to catch.
Key Operational Metrics That Signal Guardrail Health
Four metrics tell security leaders whether AI guardrails for employees are working or merely occupying budget line items. Mean time to detect (MTTD) measures how quickly the organization identifies an AI safety violation, whether an employee pastes sensitive source code into ChatGPT, a finance team member receives a deepfake CFO call, or a policy breach occurs on an unauthorized AI tool.
The target is under five minutes; anything slower means the violation has already produced downstream consequences that compound the cost of remediation. Mean time to respond (MTTR) tracks the gap between detection and containment, with a target under 15 minutes, since an AI-generated phishing email that outpaces the containment window becomes a breach rather than an alert.
False positive rate is the metric that determines whether the guardrail system earns or burns organizational trust. Every flag that incorrectly blocks a legitimate AI use case trains employees to ignore warnings and find workarounds.
Policy violation rate, the percentage of AI interactions that trigger a policy breach, reveals whether guardrails are calibrated correctly. A rate that trends upward month-over-month suggests either that employees are pushing AI tools beyond safe boundaries or that policy definitions are too restrictive for actual workflows. Either condition demands investigation.
Total Cost of Ownership Breakdown
AI guardrails for employees total cost of ownership spans four categories that security leaders must model before approaching the CFO. Licensing costs vary by deployment architecture: browser-extension-based systems that monitor AI tool usage without requiring endpoint agents or network changes typically run lower than data loss prevention (DLP) suites that require infrastructure reconfiguration.
Per-seat annual licensing reflects detection scope, since platforms monitoring dozens of AI tools and SaaS applications across the organization cost more than those covering only ChatGPT and a handful of major models.
Implementation investment includes integration with existing identity providers, HRIS systems for employee attribution, and SIEM or SOAR platforms for incident workflow routing. Organizations with mature single sign-on and API-first architectures can deploy browser-extension guardrails in hours, while those requiring custom integrations with legacy systems should budget two to four weeks of engineering time.
Staffing requirements depend on the depth of automation: a guardrail platform that auto-classifies violations and triggers automated remediation workflows substantially reduces analyst burden per thousand employees for triage and escalation, while manual review models demand far more. Ongoing maintenance covers policy tuning, coverage of new AI tools as employees adopt emerging platforms, and quarterly rule updates to align with evolving regulatory requirements, such as the EU AI Act.
Calculating ROI: Connecting Guardrail Investment to Breach Cost Reduction
The ROI equation for AI guardrails for employees starts with the cost of avoided breaches. At an average breach cost of $4.88 million in 2024, a single prevented AI-facilitated incident pays for years of guardrail licensing across an entire organization.
The more granular calculation factors in the probability of an AI-related incident without guardrails. Organizations with active AI adoption but no governance controls face compounding risk, since each employee using unmonitored AI tools represents an independent vector for data exfiltration, regulatory noncompliance, and social engineering.
Faster incident response produces savings that compound across the security operations center. When an AI guardrail detects a policy violation in under five minutes and triggers automated containment, the organization avoids the investigation costs that escalate quickly when external digital forensics consultants enter the picture, consultants who routinely bill $1,500 to $2,000 per hour, according to Splunk's analysis of security investigation costs.
A 2024 California Management Review analysis found that companies implementing generative AI with appropriate guardrails were 27% more likely to achieve higher revenue performance than peers without them. Guardrails enable safe AI adoption rather than blocking it.
Productivity preservation is the multiplier that loss-aversion calculations miss. When employees can safely use AI tools to accelerate coding, drafting, and analysis workflows, the organization captures the productivity gains that CIOs originally promised when approving access to AI tools.
The AI-Specific Incident Response Plan
Every AI safety incident response plan must define three elements that traditional IR playbooks overlook. Employee reporting channels need a mechanism faster than email and more accessible than a ticketing portal, such as a one-click reporting button embedded in the browser or an AI tool interface that automatically captures the violation context.
When an employee encounters a suspicious AI-generated message or realizes that sensitive data has been inadvertently shared with an external model, the friction in reporting determines whether the incident is contained within minutes or discovered weeks later in an audit log.
Escalation paths must route AI-specific incidents to responders who can distinguish between a traditional phishing alert and an AI safety event. An employee pasting customer PII into a public AI model requires a different containment sequence than clicking a malicious link. The escalation matrix should designate AI governance leads who can assess the scope of data exposure, coordinate with privacy and legal teams, and trigger regulatory notification workflows where applicable.
Remediation workflows close the loop by automating the response: quarantining the affected session, revoking the AI tool access for the specific user, delivering just-in-time CAT on the violated policy, and logging the incident to the employee's unified risk score for trend analysis. This human risk management approach ensures that every AI safety incident strengthens the organization's defensive posture rather than becoming a forgotten alert.
Board-Ready Reporting
Translating operational guardrail metrics into board-level business risk language requires abandoning the SOC dashboard format. Boards do not need MTTD in seconds; they need to know whether the organization's AI adoption velocity is outpacing its governance maturity. Framing the report around three questions clarifies the stakes: whether data is being lost through AI tools that remain unknown to the organization, what regulatory exposure exists if current AI usage patterns continue, and whether the productivity benefits of AI are being captured without the liability.
Reporting the policy violation trend as a percentage of total AI interactions, benchmarked quarter-over-quarter, alongside the remediation rate showing what percentage of violations were contained within the target response window, gives boards a concrete baseline.
Mapping AI tool adoption across the organization by department, overlaid with the guardrail coverage percentage, shows the board whether shadow AI usage is outpacing governance controls. One forward-looking metric, projected regulatory exposure based on current violation patterns mapped against announced enforcement timelines for frameworks such as the EU AI Act, completes the picture.
Every data point should answer one question: whether investment in AI guardrails for employees is adequate relative to the organization's AI appetite, or whether governance is being funded at yesterday's levels while AI usage accelerates well beyond it.
The board conversation flows from the data the guardrail platform produces. Without that data layer, security leaders are left making the case for AI governance with intuition rather than evidence, and intuition rarely survives the budget cycle.
Frequently Asked Questions About AI Guardrails for Employees
What percentage of enterprises have implemented AI guardrails for their employees?
According to Ivanti research published in 2026, only 50% of organizations have formal AI guardrails for employees in place to guide the deployment and operation of AI systems and agents. The gap between adoption velocity and guardrail implementation means roughly half of all enterprises operate without structured controls over how employees interact with generative AI tools. This leaves sensitive data, compliance postures, and brand reputation exposed to preventable risk.
How do AI guardrails differ from traditional content moderation tools?
AI guardrails for employees are runtime safety layers that validate, filter, and enforce policies on LLM inputs and outputs in real time, while traditional content moderation tools typically operate as post hoc classifiers applied to static content. Guardrails are policy-aware and context-sensitive, enforcing rules that account for who is using the tool, what data they are accessing, and what actions they are attempting. Traditional moderation applies uniform rules regardless of user context.
Guardrails span multiple layers, including input sanitization, output validation, and tool-use restriction, whereas moderation focuses narrowly on flagging prohibited content categories. The boundaries within AI guardrails are not fixed; they continuously adapt to new cyber threat patterns and evolving organizational policies, which static moderation rule sets cannot do.
What are the penalties for non-compliance with the EU AI Act's AI governance requirements?
The EU AI Act establishes a three-tier penalty structure under Article 99. Non-compliance with prohibited AI practices, such as deploying systems that exploit vulnerabilities or manipulate behavior, carries fines of up to €35 million or 7% of total worldwide annual turnover, whichever is higher.
Violations involving high-risk AI system obligations, including data governance and transparency requirements, can result in fines of up to €20 million or 4% of global turnover. General-purpose AI model providers face fines of up to €15 million or 3% of annual turnover for failing to meet their specific obligations.
The Act entered into force in August 2024, with enforcement phasing in through 2027. Organizations operating in EU markets must treat these penalties as material financial and reputational risks rather than abstract regulatory thresholds.
Can AI guardrails completely prevent data leakage through generative AI tools?
No. AI guardrails for employees significantly reduce, but cannot eliminate, the risk of data leakage through generative AI tools. Even sophisticated guardrail architectures face inherent limitations. Employees may find creative workarounds, novel prompt injection techniques can bypass input filters, and sensitive data can leak through memorized training data or improperly isolated test environments.
A Unit 42 analysis of commercial LLM guardrails found that even top-performing platforms exhibited failure cases across different content categories. Model-level safety CAT reduces harmful outputs but does not provide an absolute guarantee.
This is why security leaders treat guardrails as one component of a layered defense strategy that includes employee CAT, access controls, continuous monitoring, and incident response planning. No single control layer can promise zero leakage in a production AI environment.
What is the first step an organization should take to implement AI guardrails for employees?
The first step is to conduct a comprehensive internal AI use audit to identify every AI tool employees are actually using, including personal accounts accessed for work purposes. Before writing any policy or deploying technical controls, organizations need ground-truth data on the scope of AI adoption across their workforce.
This audit maps which tools are in use, what data employees are feeding into them, and where unsanctioned shadow AI tools are proliferating. Without this baseline, guardrail investments risk protecting against hypothetical cyber threats while real exposure remains unaddressed.
The audit also builds organizational awareness that drives buy-in for the policy and technical controls that follow. Starting with discovery rather than restriction signals that the goal is safe enablement, and it produces the baseline data needed to measure a guardrail program's maturity and coverage gaps.
Key Takeaways
- Effective AI guardrails for employees combine policy, training, and technical enforcement across four layers: data, model, application, and infrastructure;
- Shadow AI and ungoverned tool use create the largest source of sensitive data exposure, often without triggering traditional security alerts;
- Risk-tiered, graduated enforcement preserves productivity while applying friction proportional to actual exposure;
- Employers carry legal liability for AI-driven harm regardless of whether an employee followed policy, making documented guardrails essential to a defensible compliance posture;
- CAT must be continuous and contextual, since one-time compliance sessions fail to produce lasting behavioral change;
- Aligning guardrails with frameworks like the EU AI Act, GDPR, HIPAA, and the NIST AI RMF turns abstract compliance obligations into enforceable, auditable controls;
- Measuring guardrail effectiveness using metrics such as MTTD, MTTR, and policy violation rate connects security investment to quantifiable business outcomes.
Evaluate Organizational AI Guardrail Readiness
Half of all organizations still operate without formal AI guardrails, even as employee use of generative AI tools accelerates across every department. Explore Adaptive Security's self-guided platform tour to see how modern security awareness training can educate employees about safe AI usage.
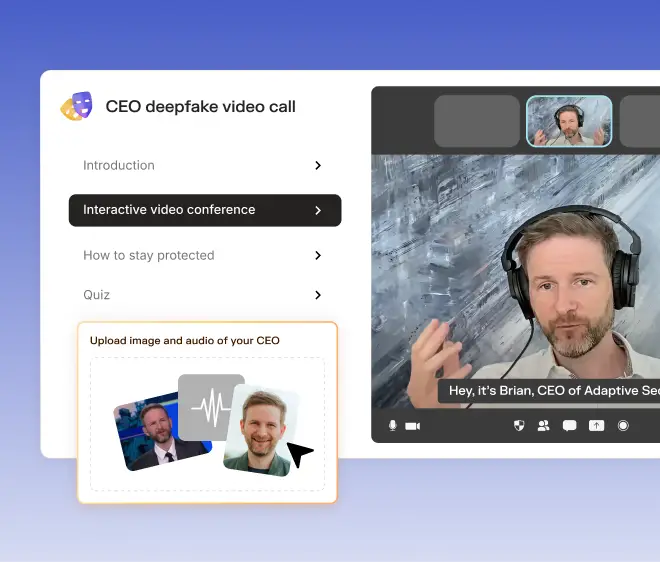

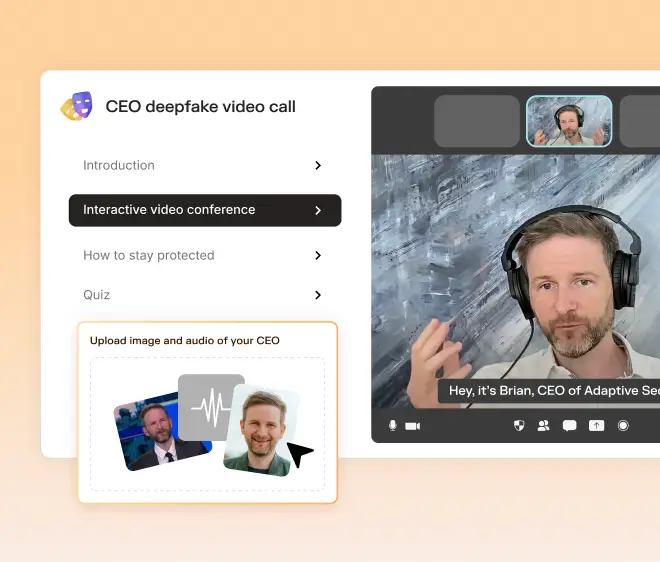
As experts in cybersecurity insights and AI threat analysis, the Adaptive Security Team is sharing its expertise with organizations.
Contents