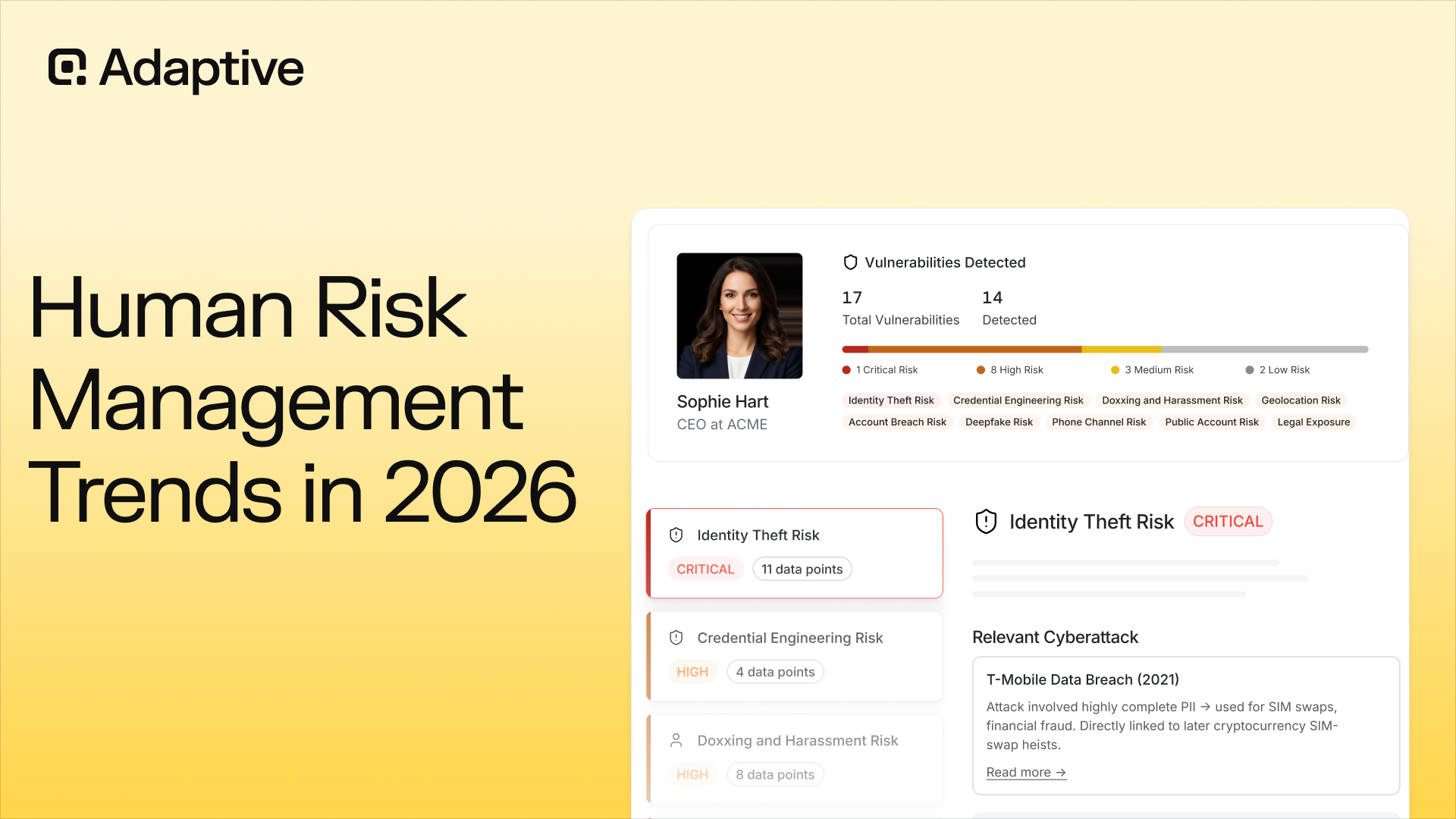
Ransomware incident response is the structured process of detecting, containing, eradicating, and recovering from a ransomware cyberattack. The effectiveness of this process directly determines whether an organization rebounds in hours or faces weeks of operational paralysis. This guide walks security leaders and IT practitioners through every phase of the ransomware incident response lifecycle.
It covers building a pre-incident response capability, identifying and confirming infections, and executing containment strategies. It also addresses how to navigate the ransom payment decision and meet regulatory reporting obligations, along with step-by-step procedures for eradication, system recovery, and post-incident security transformation.
Organizations looking to reduce the human-layer exposure that ransomware depends on can explore Adaptive Security's phishing simulation platform to build measurable behavioral resistance before an attack begins.
Understanding Ransomware: Types, Variants, and Modern Cyberattack Vectors in Ransomware Incident Response
Ransomware is a form of malicious software that encrypts or locks a victim's files, systems, or entire network, rendering them inaccessible until a ransom is paid to the cyberattacker, typically in cryptocurrency. Modern ransomware operations combine encryption with data exfiltration, threatening to publicly leak stolen information if payment is withheld. This tactic has transformed ransomware from a pure availability cyberattack into a confidentiality, regulatory, and reputational crisis.
Ransomware is now present in 48% of all data breaches, up from 44% the prior year, according to the Verizon 2026 Data Breach Investigations Report, making it the most financially disruptive cyber threat facing organizations globally. Unlike malware that operates covertly, ransomware announces itself because the victim's inability to operate is the cyberattacker's central pressure mechanism.

Screen-Locking vs. File-Encrypting Ransomware
Screen-locking ransomware restricts access to a device's user interface by displaying a full-screen ransom note, preventing any interaction with the operating system. This variant does not encrypt files; it blocks the user from reaching them, making it technically simpler to deploy but also far easier to remediate.
A reboot in safe mode or removal of the locking executable by an administrator can often restore access without data loss. Screen-lockers predominantly target mobile devices and low-value consumer endpoints where attack speed matters more than sophistication, and they rarely appear in enterprise incidents.
File-encrypting ransomware is the category that causes the operational paralysis security teams fear most. It uses strong cryptographic algorithms, typically AES-256 for file encryption with RSA-2048 key protection, to render data mathematically irretrievable without the cyberattacker's private decryption key.
Once encryption completes, no amount of malware removal or system restoration returns the files. The only paths to recovery are paying the ransom, restoring from clean offline backups, or hoping a decryption tool exists for that specific strain.
According to the Sophos State of Ransomware 2025 report, 50% of ransomware cyberattacks successfully encrypted data, and among those, 28% also involved data exfiltration, meaning the victim faced operational paralysis and a confidentiality breach simultaneously.
The implications of dwell time decisively separate these two categories. Screen-lockers execute immediately upon infection, offering no detection window before impact, while file-encrypting ransomware grants cyberattackers days to weeks inside the network before triggering encryption.
File-encrypting ransomware therefore poses the far greater data exfiltration risk, as cyberattackers routinely exfiltrate intellectual property, customer records, and employee data before deploying the payload. This converts what was once a straightforward extortion into a multi-dimensional crisis involving breach notification laws, regulatory penalties, and class-action exposure.
Double-Extortion, Multi-Extortion, and Ransomware-as-a-Service (RaaS)
Double extortion is now the operational default for ransomware groups. Cyberattackers first exfiltrate sensitive data, then encrypt systems, and demand payment under two simultaneous threats: permanent data destruction and incremental public exposure of stolen files on dedicated leak sites.
Multi-extortion further escalates the pressure architecture by stacking additional layers of coercion beyond encryption and data leakage. Cyberattackers may contact the victim's customers, partners, or patients directly to notify them that their data has been compromised.
They may file regulatory complaints under GDPR or HIPAA, launch DDoS attacks against public-facing services, or, in healthcare ransomware cases, contact patients individually to warn that their medical records will be disclosed unless the organization pays. Each added layer is designed to make non-payment costlier than payment across operational, reputational, legal, and regulatory dimensions simultaneously.
Ransomware-as-a-Service (RaaS) is the industrialization engine powering this surge in attack volume and sophistication. RaaS operates on an affiliate model: core developers build and maintain the ransomware payload; they then lease it to affiliates who execute cyberattacks in exchange for a percentage of each ransom paid, typically 70 to 80% for the affiliate.
This structure means a cybercriminal with no coding ability and a modest upfront investment can deploy a fully weaponized, professionally maintained ransomware strain. LockBit, the most prolific RaaS operation before its partial disruption, executed over 7,000 cyberattacks globally between June 2022 and February 2024, according to the UK's National Crime Agency.
The ecosystem did not slow after LockBit's takedown. Qilin replaced it as the most active group by mid-2025, launching 81 cyberattacks in a single month, a 47.3% month-over-month increase. The RaaS economy also supports a specialized supply chain of initial access brokers (IABs) who sell pre-compromised credentials and network access on dark web marketplaces, further collapsing the time and skill required to execute a cyberattack.

Primary Cyberattack Vectors: Phishing, RDP Exploitation, Exploit Kits, and Supply Chain Compromise
Phishing remains the most persistent and effective initial access vector for ransomware operators. Cisco Talos Incident Response reported that phishing reemerged as the top means of gaining initial access in Q1 2026, accounting for over a third of all engagements where initial access could be determined, reclaiming the top spot after being surpassed by vulnerability exploitation through much of 2025.
Cyberattackers use credential-harvesting pages, malicious attachments disguised as invoices or shipping notifications, and increasingly AI-generated spear-phishing emails that replicate internal communication with near-perfect tone and formatting.
Once credentials are captured, the cyberattacker authenticates as a legitimate user, bypassing perimeter defenses entirely and converting the intrusion from a malware problem into an identity problem. Organizations can reduce this exposure by deploying phishing simulations that mirror the real tactics ransomware affiliates use across email, voice, and SMS channels.
RDP exploitation follows closely behind phishing as a delivery mechanism. Exposed Remote Desktop Protocol ports on internet-facing systems allow cyberattackers to brute-force credentials or exploit known vulnerabilities to gain direct console access inside the network. RDP was the top technique for lateral movement across Cisco Talos IR engagements throughout Q3 and Q4 2025 and remained heavily used into Q1 2026.
Exploit kits and unpatched software vulnerabilities constitute the third major vector. Cyberattackers scan for public-facing applications with known but unpatched flaws, web servers, content management systems, and remote management interfaces, then deploy ransomware payloads once a foothold is established.
Supply chain compromise rounds out the attack surface. Cyberattackers breach a trusted software vendor, managed service provider, or cloud platform, then exploit that trust relationship to distribute ransomware across the vendor's entire customer base.
The Kaseya, Accellion, and SolarWinds incidents demonstrated how a single compromised update mechanism can convert one breach into hundreds of victims across dozens of industries simultaneously. The financial and operational toll those victims absorbed reveals why ransomware has become the single most expensive category of cybercrime.
Pre-Incident Preparation: Building a Ransomware Incident Response Capability
Building ransomware incident response capability before a cyberattack occurs demands four interdependent workstreams executed simultaneously:
- Developing a ransomware-specific playbook that pre-makes critical decisions a team will face under pressure;
- Constructing a backup architecture immune to encryption;
- Testing the plan through realistic ransomware simulations on a fixed cadence;
- Hardening the environment against the most common initial access vectors.
Each workstream reinforces the others. A playbook is worthless if backups are encrypted alongside production data, and backups are worthless if nobody has rehearsed restoring them. The first hour of a ransomware incident is decided long before a cyberattack begins.

1. Developing a Ransomware-Specific Incident Response Playbook
A general incident response plan tells a team to contain the cyber threat. It does not specify whether to power machines off or leave them running, whether to preserve forensic evidence before wiping, or who has the authority to even discuss paying a ransom. A ransomware-specific playbook answers those questions in advance, when everyone is calm and rational.
Unlike a data exfiltration incident where containment windows are measured in hours, encryption can spread across an entire domain in minutes.
The CISA Ransomware Response Checklist emphasizes immediate isolation of impacted systems as the first priority, but "isolate" means different things depending on whether the system is a domain controller, a file server, or a workstation with forensic value. A ransomware playbook specifies the exact isolation procedure per system class, including the order of operations and who executes each step.
Every ransomware playbook must include five non-negotiable elements:
- A detection and verification procedure that names the specific tools and log sources consulted to confirm an encryption event, down to the dashboard, alert, and correlation rule;
- A containment section with pre-written isolation commands customized to the environment;
- Explicit decision points pre-vetted by leadership, covering who can authorize taking production systems offline, the organization's position on ransom payment, and which cyber insurer and legal counsel to engage;
- A contacts directory with alternate numbers for every critical role;
- An eradication and recovery sequence that always begins with verifying backup integrity before attempting any restoration.
2. The 3-2-1 Backup Rule, Immutable Backups, and Offline Copies
The 3-2-1 backup rule is the minimum viable standard: keep three copies of every critical dataset, store them on two different media types, and maintain one copy off-site. The National Institute of Standards and Technology's National Cybersecurity Center of Excellence endorses this framework as the baseline for ransomware resilience. The 3-2-1 rule alone, however, is no longer sufficient, since modern ransomware actively targets backup infrastructure before deploying the encryption payload.
Immutable backups close this gap. An immutable backup cannot be modified, encrypted, or deleted, even by a cyberattacker who has compromised domain administrator credentials, for a defined retention period. Most major cloud providers and enterprise backup platforms now offer native immutability.
CISA explicitly recommends that all backup data be encrypted and immutable, covering the organization's entire data infrastructure. Without immutability, a ransomware operator who gains privileged access can simply delete or encrypt backups before the organization knows a cyberattack is underway.
Offline or air-gapped copies add a final layer of defense. At least one backup copy should be physically disconnected from the network: tape, removable drives stored in a fireproof safe, or a cloud storage bucket with no programmatic delete permissions and separate authentication from the production identity provider.
Validate backup integrity quarterly by performing a test restoration of a randomly selected dataset. A backup that has never been restored is not a backup; it is a theory. Documenting exactly how long a full restoration takes under realistic conditions establishes the constraint the incident commander operates against during an actual event.
3. Tabletop Exercises, Red Team Simulations, and Plan Testing Cadence
A ransomware playbook that has never been exercised is a liability. Tabletop exercises convert the document into muscle memory by walking key personnel through a realistic scenario: encryption detected on a Friday at 4:30 p.m., backups partially targeted, the CEO's laptop compromised. Run these at least twice per year, with high-risk sectors, including financial services and healthcare, running them quarterly.
Effective tabletop sessions are specific, not generic. A named scenario, such as Akira ransomware encrypting three file servers with a ransom note demanding $2 million in Bitcoin within 72 hours and a threat actor claiming to have exfiltrated 500 GB of client data, works better than a vague reference to "a ransomware incident." Every participant must operate within their real role.
The facilitator introduces: the insurer demands a specific forensic firm, the CEO asks whether payment is faster than restoration. The facilitator observes where the team hesitates, where the playbook is silent, and who defers decisions they are supposed to own.
After-action reviews are where the real value materializes. Documenting every gap matters, whether that is the IR retainer phone number that nobody had, the backup restoration estimate that was off by 12 hours, or the communications plan that did not address customer notification timing under state breach laws. Update the playbook within one week of the exercise.
Red team simulations add an adversarial layer that tabletops cannot replicate. A ransomware-specific red team engagement tests whether an environment can detect and stop a trained operator attempting to move from initial phishing compromise to domain dominance.
Unlike a generic penetration test, ransomware red teams focus on the specific TTPs used by active groups: credential dumping from LSASS memory, RDP lateral movement, backup enumeration, and data staging for exfiltration. Run these annually, or after any major infrastructure change that alters the attack surface.

4. Hardening the Environment: RDP Security, Application Allow Listing, and Privileged Access Controls
Ransomware operators exploit configuration gaps, not zero-days. The CISA BianLian advisory documents how a single compromised RDP credential, purchased from an initial access broker for a few hundred dollars, enabled a group to breach organizations across multiple critical infrastructure sectors. Every pre-incident hardening effort must begin with the controls that block the most common attack paths.
RDP security demands immediate attention. Disabling RDP on any system that does not require it is the first step; where RDP is necessary, it should sit behind a VPN or zero-trust network access solution, and port 3389 should never be exposed directly to the internet.
Deploying Microsoft Local Administrator Password Solution ensures every machine has a unique, complex, and regularly rotated local administrator password, eliminating lateral movement via shared local credentials. Network-level authentication and account lockout policies after a low threshold of failed attempts round out this control set.
Application allowlisting prevents cyberattackers from executing portable tools. Impacket, Rclone, SharpShares, and custom backdoors all become useless, even after initial access is gained. CISA recommends that organizations implement application controls to block the installation and execution of unauthorized software, noting that antivirus solutions alone often fail to detect malicious portable executables that use compression, encryption, or obfuscation.
Pairing allowlisting with constrained PowerShell adds another layer: restricting PowerShell execution to specific users via Group Policy, updating to PowerShell 5.0 or later, and enabling script block logging, module logging, and transcription with a minimum 180-day retention period.
Privileged access controls complete the hardening triad. Phishing-resistant multifactor authentication should cover all external-facing services and privileged accounts, and the principle of least privilege should be applied rigorously so that no user runs with domain admin rights for daily work. Just-in-time privileged access provisions administrative rights only when needed and revokes them automatically afterward.
Macro restrictions in Microsoft Office block one of the most reliable ransomware delivery mechanisms; disabling macros from the internet by Group Policy closes this path. Configuring SPF, DKIM, and DMARC prevents cyberattackers from spoofing an organization's domain in phishing campaigns that deliver ransomware payloads to employees and partners.
These hardening controls shrink the attack surface to what is operationally necessary and no more. When they hold, the incident never starts. When a cyberattacker finds a way past them, everything built in the preceding stages, including the playbook, the tested backups, and the muscle memory from simulation, determines whether the organization recovers in hours or weeks.
Detection: Identifying and Confirming a Ransomware Infection
Recognizing an active ransomware infection requires scanning endpoints for telltale signs, file extension changes, ransom note appearances, and anomalous process activity, while simultaneously launching forensic tracing to identify patient zero and the initial access vector.
Once ransomware is confirmed, security teams must identify the specific variant using ransom note text, extension patterns, and public identification tools before investigating whether data was exfiltrated prior to encryption.
1. Common Signs of an Active Ransomware Infection on Endpoints
The most visible indicator is a sudden, mass change in file extensions across user directories and network shares. Files that previously ended in .docx, .pdf, or .xlsx will now carry unfamiliar extensions appended by the encryption routine, such as .lockbit, .akira, .play, .blackcat, or randomized alphanumeric strings specific to the variant. An entire department's shared drive may become unreadable within minutes.
Ransomware typically drops a ransom note in every encrypted directory. These notes take the form of .txt, .html, or .hta files with names like README.txt or variant-specific markers such as HowToRestore.txt, containing payment instructions, a countdown timer, and a unique victim ID. The joint FBI-CISA #StopRansomware advisory on Play ransomware notes that some modern strains omit ransom demands from the note entirely and instead direct victims to a Tor-based communication channel.
Endpoint detection and response (EDR) platforms provide the fastest signal of compromise. EDR alerts surface suspicious process chains, such as powershell.exe spawning from winword.exe, or cmd.exe invoking vssadmin.exe delete shadows /all /quiet to destroy volume shadow copies.
Mass file rename operations, unexpected outbound connections to IP addresses with no reputation history, and the sudden termination of backup services are all high-fidelity indicators. Any EDR alert involving shadow copy deletion should be treated as a confirmed ransomware event, triggering immediate containment.
2. Identifying Patient Zero and Tracing the Initial Access Point
Patient zero is the earliest known compromised asset in the attack chain. Tracing begins with correlating timestamps across EDR telemetry, authentication logs, and file system metadata.
Isolating the device where encryption was first detected is the starting point. Forensic analysis should focus on the earliest malicious process execution time, cross-referenced with the creation timestamp of the first ransom note or encrypted file. Windows Event Logs, specifically Event ID 4624 (successful logon) and 4688 (process creation), reveal the user account under which the ransomware payload executed and whether that account authenticated from an unusual IP address or outside normal business hours.
Tracing backward through the kill chain answers whether the ransomware was launched from a malicious email attachment, a macro-enabled document downloaded via a phishing link, or a compromised RDP session.
The Sophos State of Ransomware 2025 report found that exploited vulnerabilities and compromised credentials remain the two most common root causes. Checking VPN and identity provider logs for impossible-travel anomalies, MFA push acceptance from unknown locations, or newly registered devices that appear shortly before encryption begins rounds out this analysis.
Reviewing the Microsoft 365 Unified Audit Log or Google Workspace audit trail for the compromised account during the 72 hours preceding encryption can surface mailbox rule creation, forwarding rule deployment, or unusual file download activity. These are classic signs of a cyberattacker establishing persistence before detonating the payload.
3. Determining the Ransomware Variant
Identifying the specific ransomware strain shapes every downstream decision, from whether a working decryptor exists to how aggressively the organization must investigate data exfiltration. Variant identification begins with the ransom note text, the file extension appended to encrypted data, and any email addresses or Tox chat IDs left by the cyberattackers.
The most reliable free tool for strain identification is ID Ransomware, operated by the MalwareHunterTeam. Security teams upload a copy of the ransom note or a sample encrypted file, and the service cross-references both against a continuously updated database of known ransomware signatures. The tool returns the strain name, whether a free decryptor is available, and links to decryption resources when applicable.
File extension analysis provides rapid triage even before uploading samples. Extensions including .akira, .lockbit, .play, .medusa, .blackbyte, and .royal each map to specific ransomware-as-a-service (RaaS) operations with known behaviors around data exfiltration, negotiation style, and industry targeting patterns. Mapping the extension to a known group lets incident responders make faster containment decisions in the critical first hours.
4. Detecting Data Exfiltration
Determining whether exfiltration occurred changes the incident from a restoration problem into a breach notification, regulatory disclosure, and legal liability event.
Network telemetry is the primary detection source. Examining firewall and netflow logs for the compromised endpoint during the 7 to 14 days preceding encryption can reveal large outbound transfers to IP addresses geolocated in regions with no business justification, connections to known onion routing nodes, or sustained data egress patterns during off-hours. Cyberattackers increasingly tunnel exfiltration through HTTPS on port 443 using non-standard user agents to blend into normal web traffic.
Data loss prevention (DLP) logs provide a second detection layer. Reviewing DLP alerts for the compromised user can surface policy violations involving bulk file transfers, USB mass storage activity, or uploads to personal cloud storage services.
Organizations using cloud access security broker (CASB) tooling should also audit cloud application activity for anomalous download volumes, file sharing permission changes, or the creation of public sharing links on sensitive repositories.
Checking the ransomware group's dark web leak site provides final confirmation. Most RaaS operations maintain a name-and-shame page where they publish victim identities and stolen data samples. If the organization's name appears on that site, with or without a countdown to full publication, exfiltration is confirmed, and the clock on regulatory notification obligations has already started. Confirming what was taken and where it went defines whether the next phase is technical recovery or full-scale legal response.
Containment: Stopping Ransomware From Spreading Across a Network
Containment begins the moment ransomware is confirmed on a single endpoint. Isolating every affected system by disconnecting it from the network, placing it into hibernation rather than restarting, and photographing the ransom note with a separate device before anything else are the foundational first actions. The speed and precision of these containment actions directly determine how much data the cyberattackers encrypt before the response stops them.
1. Immediate Isolation Procedures: Disconnect, Don't Restart, and Photograph the Ransom Note
The first five minutes after ransomware detection separate a contained incident from a company-wide encryption event. CISA's ransomware response guidance is unambiguous: determine which systems were impacted and immediately isolate them.
Disconnecting Ethernet cables, disabling WiFi and Bluetooth, and severing all network connections on every affected or potentially affected device matters because modern ransomware variants scan networks aggressively for lateral movement paths. Every second a compromised machine stays connected gives the payload time to find and encrypt the next target.
Infected devices should never be restarted. Some ransomware strains detect reboot attempts and respond by damaging Windows boot configurations or permanently deleting partially encrypted files. Rebooting also wipes volatile memory, the RAM that contains encryption keys, command-and-control connection artifacts, and forensic evidence incident response teams need to identify the variant and its propagation method.
Placing affected systems into hibernation instead preserves evidence. As IBM's ransomware response guidance explains, hibernation preserves all memory contents by writing them to a reference file on the hard drive, creating a forensically intact snapshot that investigators can analyze without risking data loss from a full shutdown.
Photographing the ransom note before doing anything else, using a smartphone or separate camera to capture the screen of the affected device, preserves the exact text, payment instructions, threat actor contact information, and any cryptographic identifiers displayed.
Those details serve three critical functions: they help law enforcement match the incident to known threat actor campaigns; they provide the evidence a cyber insurance carrier requires to process a claim; and they allow the incident response team to identify the ransomware variant through free identification tools. CISA also recommends taking a system image and memory capture from a sample of affected devices before beginning any eradication effort.
The first five isolation actions, executed in sequence, are:
- Disconnect the affected system from all networks and disable wireless radios;
- Place the machine into hibernation;
- Photograph the ransom note;
- Disconnect backup storage from the network to prevent encryption of recovery data;
- Disable any automated maintenance tasks, including log rotation, temporary file deletion, and patch management jobs, that could destroy forensic artifacts or interfere with recovery.
2. Short-Term vs. Long-Term Containment Strategies
Short-term containment halts active encryption spread in the first hour. It is reactive, blunt, and designed around speed: disabling compromised user and service accounts across the identity provider, revoking all active sessions for affected users, forcing password resets on privileged accounts, and blocking known malicious IP addresses and domains at the firewall.
At this stage, disrupting business operations is an acceptable cost. Quarantining an entire VLAN or shutting down a file server is preferable to letting encryption cascade through the environment. Short-term containment also means deploying an out-of-band communication channel that the cyberattacker cannot monitor, since threat actors who have established persistence routinely read internal emails and Slack messages to anticipate the response.
Long-term containment is architecture-level. Once the immediate encryption process is halted, the focus shifts to building a containment posture that prevents the cyberattacker from regaining access through backdoors installed during the initial compromise.
This includes rebuilding affected systems from trusted golden images rather than attempting to clean them, rotating all credentials, including service account passwords, API keys, and certificate private keys, and implementing network access control policies that deny lateral movement by default.
Long-term containment also means isolating backup infrastructure behind separate authentication systems with different administrative credentials, since modern ransomware groups specifically target backup servers to eliminate recovery options before deploying the payload.
The transition between short-term and long-term containment is where most response efforts stall. Security teams contain the immediate threat, declare the incident under control, and resume normal operations, only to discover the cyberattacker maintained a second persistence mechanism that activates days or weeks later.
Sustained containment requires 24/7 monitoring of all egress traffic, a complete audit of every account that authenticated during the compromise window, and forensic verification that no unauthorized cloud API keys or OAuth tokens were created during the cyberattacker's dwell time.
3. Network Segmentation, Lateral Movement Prevention, and Disabling Automated Tasks
Existing network segmentation is the most powerful containment tool available during an active ransomware incident. Organizations that have already separated IT and operational technology networks, segmented sensitive data zones, or implemented microsegmentation between application tiers can isolate the blast radius to a single segment while keeping other parts of the business operational.
During the incident, immediately restricting inter-VLAN routing for any segment containing affected systems and applying emergency access control list rules that deny all traffic to and from those zones, except for explicitly authorized incident response workstations, limits the spread. Organizations that discover segmentation gaps during an incident, such as a flat network with no internal boundaries, face a binary choice: shut everything down or accept that encryption will spread unchecked.
Automated maintenance tasks must be disabled the moment ransomware is confirmed. Database log rotation, scheduled temp-file cleanup, automated patching agents, and any cron job or scheduled task that modifies files can destroy forensic evidence or interfere with partial encryption in progress. Some ransomware strains encrypt files in phases, and interrupting that process with a disk cleanup operation can render files permanently unrecoverable even if a decryption key is later obtained.
This rule extends to backup jobs. Disabling any automated backup process that connects to production systems matters because ransomware frequently propagates through backup agents that have write access to both production and backup storage.
Securing privileged accounts during an active incident requires immediate and aggressive action. Every privileged credential in the environment should be treated as compromised, since ransomware operators routinely harvest credentials from memory and credential stores during the dwell period before deploying encryption.
This means forcing rotation of all domain administrators, enterprise administrators, and service account passwords, and revoking every active session token for privileged users across all identity providers and cloud platforms.
Creating new, temporary administrator accounts dedicated to incident response activity, used exclusively from clean, air-gapped workstations that were never connected to the compromised network, prevents the cyberattacker from intercepting response communications.
The Canadian Center for Cyber Security's ransomware playbook, updated in January 2026, recommends dedicated administrative workstations with public internet access removed as a critical control.
Once containment is stable, implementing the principle of least privilege at the network layer means no user account should have access to any system or segment beyond what their role explicitly requires, and every lateral authentication attempt should generate an alert.
Reducing human-layer risk through phishing simulations that train employees to recognize the initial access attempts, credential harvesting emails, and social engineering lures that deliver ransomware payloads remains the most effective way to prevent a cyberattack from ever reaching the containment stage.
Eradication: Removing Ransomware and Breaking Cyberattacker Persistence
Eradication moves beyond containment to remove every trace of the ransomware payload and systematically hunt down persistence mechanisms that cyberattackers embedded during their dwell time. The global median dwell time reached 14 days in 2025, according to the Mandiant M-Trends 2026 report, up from 11 days the prior year.
Using endpoint detection and response (EDR) tooling to kill malicious processes, identify and disable scheduled tasks, registry run keys, and WMI event subscriptions, and then execute the Active Directory recovery procedures that adversaries bank on organizations skipping, defines this phase.
The decision to sanitize or rebuild each compromised system must be made with surgical precision, since a single missed persistence hook can restore the cyberattacker's foothold within hours of declaring the incident closed.
1. Eradicating the Ransomware Payload and Hunting for Adversary Persistence Mechanisms
Removing the ransomware binary itself is the most visible step, but it is rarely sufficient. Ransomware operators increasingly operate as secondary actors in a broader access-broker ecosystem. According to the Mandiant M-Trends 2026 report, prior compromise was the top initial infection vector in ransomware operations, accounting for 30% of ransomware-related intrusions. The ransomware payload was deployed onto a network where cyberattackers already had a durable foothold, and if that foothold survives eradication, re-encryption is a matter of time.
Beginning with EDR to kill all malicious processes and quarantine the ransomware binary across every impacted endpoint comes first. Pivoting immediately to persistence hunting follows: working through the registry for Run and RunOnce keys, Services entries, and AppInit_DLLs modifications. Cyberattackers frequently plant scheduled tasks configured to re-execute payloads after reboot or at timed intervals, and each must be identified and removed.
WMI event subscriptions are equally dangerous because they can trigger code execution in response to system events without touching the filesystem directly.
The hand-off window between initial access brokers and ransomware operators collapsed to just 22 seconds in 2025, as illustrated by Jurgen Kutscher, Vice President of Mandiant Consulting at Google Cloud, in the M-Trends 2026 analysis. Initial access partners are pre-staging malware and tunnels during the initial infection, meaning secondary actors are fully equipped to launch operations the moment they first interact with the network. That speed leaves zero margin for incomplete eradication.
Hunting for less-obvious persistence rounds out this work: Active Directory group membership modifications that grant the cyberattacker privileged access, rogue domain accounts created during the intrusion, and credential-dumping artifacts indicating the cyberattacker harvested material for return access. Mapping every technique against the MITRE ATT&CK Persistence tactic (TA0003) ensures no blind spots remain, and documenting every artifact removed becomes critical for the post-incident report and for demonstrating to auditors that remediation was comprehensive.
2. Resetting krbtgt, Deploying LAPS, and Securing Active Directory After a Domain Compromise
If the cyberattacker achieved domain administrator privileges, which is the goal of nearly every sophisticated ransomware operation, Active Directory itself is compromised. No amount of endpoint cleaning will matter if the cyberattacker holds forged Kerberos tickets or has manipulated the domain trust fabric. The krbtgt account, which encrypts and signs all Kerberos tickets in the domain, is the single highest-value target in a compromised AD environment.
Resetting the krbtgt password must be performed twice, with a minimum 10-hour replication interval between resets. The first reset invalidates all existing Kerberos tickets, and the second reset ensures that any tickets generated using the password history, which Active Directory retains, are also rendered useless.
Microsoft's forest recovery guidance explicitly mandates this double-reset procedure following a domain compromise. Skipping the second reset or compressing the interval below 10 hours creates a gap where forged tickets remain viable.
Deploying Microsoft Local Administrator Password Solution (LAPS) across every Windows endpoint follows the krbtgt recovery. LAPS assigns unique, randomly generated local administrator passwords to each machine and rotates them automatically, eliminating the lateral movement path that ransomware operators exploit when they compromise a single local admin credential and use it to hop across the network. Without LAPS, one compromised workstation becomes the skeleton key to every machine sharing that local admin password.
Enforcing Group Policy restrictions that prevent privileged domain accounts from signing into workstations is also necessary; domain admins should authenticate only to domain controllers and secure administrative jump hosts.
3. The Sanitize-vs-Rebuild Decision for Compromised Systems
Every compromised system forces a binary choice: sanitize what exists or rebuild from known-good media. The default answer in any domain-compromise scenario should be rebuild, since cyberattackers today deploy custom in-memory malware that leaves minimal forensic artifacts.
The Mandiant M-Trends 2026 report documented backdoors like BRICKSTORM achieving dwell times of nearly 400 days on edge devices, where file system forensics were effectively impossible. If a system's cleanliness cannot be proven, it should not be treated as clean.
Sanitization is acceptable only when three conditions are met simultaneously: the ransomware variant must be well-documented with no known persistence beyond its encryption routine; forensic analysis must confirm no secondary malware was deployed; and the system must run a modern, supported operating system with full EDR visibility.
Legacy operating systems, including Windows Server 2012, Windows 7, or any OS beyond end-of-life, should be rebuilt unconditionally. They lack the security telemetry and logging granularity required to validate eradication, and cyberattackers specifically target them because defenders cannot see what happened.
Rebuilding does not end with re-imaging. Restoring data from backups that were verified clean before the intrusion window, applying all security patches before reconnecting the system to the network, and enrolling the rebuilt machine in EDR before it communicates with anything else are all required steps.
A system should never be restored using domain credentials that existed during the compromise window; freshly provisioned accounts prevent the cyberattacker from intercepting credentials during restoration.
The CISA ransomware response checklist emphasizes triaging impacted systems for restoration and recovery as a core step, and that triage must include the explicit sanitize-or-rebuild decision for every affected asset.
Eradication is the phase where ransomware incident response succeeds or fails silently. Organizations that remove the payload but miss the persistence hook discover the gap when the ransom note reappears. The systems that survive eradication become the foundation for the recovery phase, and every corner cut here compounds into extended downtime during restoration.
Recovery: Restoring Systems and Data With Confidence
Restoring systems after a ransomware cyberattack demands a disciplined, verification-first approach rather than a race to resume operations. Locating every backup repository and cryptographically verifying its integrity before restoring a single file comes first, followed by rebuilding systems in strict priority order inside isolated recovery environments. Rushing restoration without confirming backups are clean guarantees reinfection and multiplies the total cost of the incident.
1. Locating and Verifying Backup Integrity After a Network Compromise
Before restoration can begin, it is essential to confirm that every backup is intact, complete, and free of cyberattacker tampering. Modern ransomware operators specifically target backup infrastructure, deleting shadow copies, encrypting backup files, and corrupting backup catalogs, because destroying the recovery path maximizes the probability of a ransom payment. NIST IR 8374r1 explicitly requires that the integrity of backups and other restoration assets be verified before using them for restoration. An unverified backup is a liability, not an asset.
Inventorying every backup repository, including on-premises NAS, cloud object storage, tape archives, and replication targets, comes next. Generating cryptographic checksums against known-good baselines created during the last verified backup window for each repository allows any checksum mismatch to signal potential compromise, triggering a deeper forensic review before that backup is used. Modified timestamps on catalog databases, unexpected size changes in backup files, and altered retention policies all indicate that cyberattackers attempted to sabotage recovery.
Immutable backups stored in WORM (write once, read many) format provide the strongest integrity assurance because no actor, including privileged administrators, can modify them. Organizations that maintain offline or air-gapped backup copies fare dramatically better during recovery.
The CISA Ransomware Response Checklist recommends triaging impacted systems for restoration immediately after isolation, but that triage is worthless if the backup source itself is compromised. Isolating verified backup repositories on a dedicated recovery VLAN before proceeding ensures residual malware on production networks cannot reach the one clean copy of organizational data.
2. Step-by-Step System and Data Restoration Procedures
Restoration follows a strict dependency chain. Rebuilding infrastructure in the wrong order creates configuration gaps cyberattackers can exploit or leaves critical services unable to function. The sequence that consistently produces clean recoveries across enterprise environments works in four phases.
First, core identity and authentication services (Active Directory, Entra ID, Okta, or equivalent) must be stood up in an isolated recovery environment, since no other system can authenticate users or enforce access policies without directory services.
Domain controllers should rebuild from verified media, never from snapshots of potentially compromised running instances. Forcing a reset of all privileged account credentials, including service accounts, before joining any additional systems to the recovery domain matters because one overlooked service account with a compromised credential is all a cyberattacker needs to re-enter the environment.
Second, network infrastructure restoration covers firewalls, switches, VPN concentrators, and DNS servers. Applying the most recent known-good configuration backups and validating that segmentation rules are enforced before traffic flows resume establishes a controlled network where east-west movement is restricted, and internet-bound traffic is filtered.
Third, storage and database platforms come online, followed by application servers in priority order based on business impact analysis. Finance systems, EHR platforms, and customer-facing applications typically take precedence over internal tools. For hybrid and multi-cloud environments, coordinating restoration across on-premises VMware or Hyper-V clusters and cloud-native services like AWS EC2, Azure VMs, or GCP Compute Engine simultaneously prevents cross-environment reinfection.
Fourth, endpoint systems restore last. Workstations rarely hold unique data that justifies early restoration priority, and bringing endpoints online too early expands the attack surface before monitoring and EDR tooling are fully operational. Breach identification and containment timelines that stretch into months underscore why rushing endpoint restoration before the monitoring stack is in place defeats the purpose of methodical recovery.
3. Validating Restored Data Integrity and Handling Legacy Operating Systems
Post-restoration validation answers a single question: Is this data exactly what existed before the cyberattack, with no malicious modifications? Running automated integrity checks against restored databases, file shares, and configuration stores, comparing file counts, directory structures, and sample data against pre-incident baselines, addresses this.
For structured data in SQL Server, Oracle, or PostgreSQL databases, verifying row counts and checksums across critical tables matters; any discrepancy, even a single modified stored procedure in a financial application, must be treated as potential cyberattacker persistence until disproven.
Malware scanning of restored data is essential but insufficient on its own. Signature-based scanners miss novel payloads, and restored binaries that were clean at backup time may have been benign components of a multi-stage attack chain. Sandboxing any executable content restored from backup and monitoring its runtime behavior before reintroducing it to production addresses this gap. For document and media files, inspecting for macro code, embedded scripts, and anomalous metadata that could indicate weaponization is equally important.
Legacy operating systems, such as Windows Server 2012, Windows 7, RHEL 6, and similar end-of-life platforms, present a compounding risk during restoration. These systems cannot run current endpoint detection and response (EDR) agents, receive no security patches, and often lack support for modern authentication protocols.
Isolating legacy systems on dedicated network segments with no internet access and strict inbound and outbound traffic rules limits exposure. Where possible, restoring legacy application data to a modern OS running the application in compatibility mode is preferable to rebuilding the insecure original environment.
If the business requires the legacy OS to remain online, deploying a compensating control stack, including application allowlisting, network-level IDS, and aggressive log forwarding to the SIEM, alongside formal documentation of the accepted risk, is the appropriate path. The restoration phase is the right moment to retire technical debt rather than preserve it.
Lessons learned during restoration about which systems were targeted, how cyberattackers moved laterally, and which defenses failed become the blueprint for the security architecture that replaces what was lost.
The Ransom Decision: To Pay or Not to Pay
Paying a ransom funds the criminal ecosystem holding an organization's data hostage. Refusing to pay can mean weeks of operational paralysis and the permanent loss of critical data. A Semperis study of nearly 1,000 IT and security professionals (2024) found that 35% of victims who paid either received no decryption key at all or received keys that were corrupted and unusable.
The decision is never purely financial; it sits at the intersection of business continuity, legal liability, regulatory exposure, and organizational ethics, and no two ransomware incidents present exactly the same calculus.
The Risks of Paying: No Guarantees, Funding Criminal Enterprises, and Future Targeting
The most immediate risk of paying a ransom is that it often fails to deliver what it promises. Decryption is a slow, manual, unreliable process even when keys are delivered, since cyberattackers have no incentive to ensure data integrity, and their decryption tools frequently fail on large or complex file systems.
Repeat targeting is the second risk, backed by hard data. The same Cybereason research found that 80% of organizations that paid a ransom were attacked again, often by the same threat group. The Semperis data reinforces this pattern: 74% of respondents were attacked multiple times, with many strikes occurring within the same week.
Attackers share victim intelligence, and an organization that pays once signals willingness and capability to pay again, a signal that travels through ransomware-as-a-service affiliate networks with remarkable speed.
The sanctions dimension adds another layer of exposure. The U.S. Treasury Department's Office of Foreign Assets Control (OFAC) has made clear that paying a ransom to a sanctioned entity carries civil penalty exposure regardless of whether the payer knew the recipient was sanctioned. Numerous ransomware groups appear on OFAC's Specially Designated Nationals (SDN) list.
OFAC's advisory explicitly states that facilitating ransomware payments threatens U.S. national security and foreign policy interests, and the agency will consider a company's cooperation with law enforcement as a mitigating factor when evaluating enforcement actions.
Paying also fuels the broader ransomware economy. Total ransomware payments reached $813.55 million in 2024, a 35% decline from the record $1.25 billion in 2023, according to Chainalysis. That sum still constitutes an enormous revenue stream funding increasingly sophisticated operations, including AI-enhanced reconnaissance, automated payload deployment, and more convincing social engineering lures.
Free Decryption Tools and the No More Ransom Project
Before considering payment, organizations should exhaust the growing ecosystem of free decryption resources. The No More Ransom portal, launched in 2016 as a collaboration between Europol, the Dutch National High Tech Crime Unit, and cybersecurity vendors including Trellix (formerly McAfee) and Kaspersky, now hosts decryptors for over 165 ransomware variants. The project has helped millions of victims recover files without paying a single dollar to cyberattackers.
The process of using these tools is straightforward. Identifying the ransomware variant that encrypted the files comes first and is often indicated by the ransom note, changes in file extensions, or the cyberattacker's contact method. If the strain is not immediately identifiable, uploading a sample encrypted file and the ransom note to ID Ransomware, a free service that cross-references file markers against a database of known variants, returns a match within seconds.
Once identified, the No More Ransom portal provides a searchable index of available decryptors. Major antivirus vendors, including Emsisoft, Avast, and Bitdefender, separately maintain free decryption libraries that cover hundreds of additional strains.
Law enforcement decryptors represent an underutilized resource. Since 2022, the FBI's Internet Crime Complaint Center (IC3) has provided thousands of decryption keys to ransomware victims, preventing over $800 million in ransom payments.
When international operations disrupt ransomware infrastructure, as occurred with the takedowns of Hive, LockBit, and BlackCat, law enforcement agencies frequently recover decryption keys and make them available to victims. Organizations should contact their local FBI field office or the national cybersecurity agency immediately after a cyberattack, as the keys may already be in the hands of cyberattackers.
The critical limitation is timing. New ransomware variants and custom builds deployed by targeted cyberattackers often have no known decryptor. Immutable offline backups remain the single most reliable defense against encryption-based extortion. Organizations that maintain tested, air-gapped backups with verified recovery procedures position themselves to refuse payment from a position of operational strength rather than desperation, a position that cyber insurers increasingly require before they will even underwrite a policy.
The Role of Cyber Insurance and Cryptocurrency Tracing in Ransomware Negotiations
Cyber insurance has reshaped the ransom decision, often in unexpected ways. Insurers have become the de facto gatekeepers of payment decisions because their policies typically require policyholder consent before any ransom is paid. They employ specialized incident response firms, ransomware negotiators, and cryptocurrency forensics teams that bring structured decision-making to what would otherwise be a crisis-driven impulse.
According to Marsh's 2025 cyber insurance market analysis, U.S. cyber insurance rates declined 5% in Q4 2024, and coverage requirements have become more stringent, with carriers now routinely mandating multi-factor authentication, endpoint detection, and immutable backups as conditions of coverage.
Insurance does not make paying easier; it imposes rigor. Aon reported that its U.S. broking clients saw average ransom payments drop by 77% in 2024, reflecting improved security controls, better backup strategies, and insurer-driven negotiation discipline.
When insurers are involved, payment decisions pass through a structured evaluation covering whether viable decryption is possible, the actual business interruption cost of refusing, and any sanctions implications if the threat actor is OFAC-listed. The insurer's ransomware negotiator, often a former law enforcement hostage negotiator, works to reduce demands, extend deadlines, and gather intelligence even as the organization evaluates alternatives.
Cryptocurrency tracing has introduced a parallel dynamic. Blockchain analysis firms such as Chainalysis and TRM Labs now work with law enforcement to trace ransom payments through cryptocurrency wallets, mixers, and exchanges with increasing speed.
The FBI's IC3 reports that rapid tracing has enabled seizure of ransomware proceeds and, in some cases, recovery of decryption keys from infrastructure seized during coordinated takedowns. This capability does not eliminate the payment dilemma, but it does shift the negotiation landscape, since cyberattackers know that payments create an auditable trail and law enforcement's growing success in following that trail reduces the safe harbor that cryptocurrency once provided.
Organizations preparing for negotiation scenarios should establish decision frameworks before an incident occurs. Identifying who holds payment authority, pre-negotiating engagement terms with a ransomware response firm, and confirming that the cyber insurance policy covers ransom payments, including any sub-limits or exclusions, are essential steps.
Maintaining the operational capability to refuse payment through tested backups, documented recovery procedures, and executive alignment on the conditions under which payment would and would not be considered defines the strongest negotiating position: the ability to walk away.
Communication, Legal Considerations, and Regulatory Reporting
Ransomware cyberattackers impose a payment countdown, but regulators impose their own ticking clocks, and the two rarely align. Under CIRCIA, covered entities must report significant cyber incidents to CISA within 72 hours and ransomware payments within 24 hours of making them.
This compressed timeline runs in parallel with forensic investigation, stakeholder communication, and legal strategy. Organizations that treat these as sequential workstreams rather than simultaneous tracks discover too late that a single missed deadline can escalate into regulatory enforcement, civil litigation, and irreversible reputational harm.
Internal and External Stakeholder Communication During an Active Ransomware Incident Response Effort
Communication breaks down fastest when no one knows who is authorized to speak. The first 60 minutes after confirming a ransomware incident should activate a pre-defined communication hierarchy, designating a single incident communications lead who owns internal cadence, external statements, and coordination with legal and executive teams before an incident ever occurs.
Internally, employees need enough information to stop harmful behaviors without enough detail to leak. An initial employee notification sent within the first two hours should confirm the organization is managing a security incident and provide clear instructions: disconnect from VPN, stop using email if instructed, and forward suspicious messages to a designated channel. It should also explicitly state what employees must not do: speculate on social media, discuss the incident with external parties, or attempt to contact the threat actor.
Follow-up updates should arrive at predictable intervals, every four to six hours during active containment, even when there is no new information, since silence breeds rumor and rumor travels faster than any official statement.
Executive updates require a different format altogether. Board members and senior leadership need a concise situation report structured around four questions: what is known, what is not known, what is being done right now, and what is needed from them. Avoiding technical forensic detail and framing every update in terms of business impact, containment progress, and regulatory exposure keeps leadership oriented. The CEO should never learn about a ransomware incident from a journalist.
Customer communications carry the highest stakes. Premature disclosure can tip off cyberattackers or trigger panic, while delayed disclosure invites regulatory penalties and breach-of-trust litigation. The legal team must approve every external statement, but marketing and communications leads should draft pre-approved holding statements for three scenarios long before an incident occurs: confirmed breach with data exposure, confirmed breach with no evidence of data exposure, and investigation in progress.
Media statements should follow the same principle: acknowledging the incident without speculating on scope, describing the containment actions underway, and directing inquiries to a single press contact. A routine phishing click should never be described as a sophisticated attack. Credibility lost during incident communications is rarely regained.
Reporting to Law Enforcement: FBI, CISA, and International Authorities
Engaging law enforcement is not an admission of failure; it is an operational necessity. The FBI, through its Internet Crime Complaint Center (IC3), and CISA both offer tangible investigatory and remediation resources that no private-sector incident response team can replicate.
CISA's regional cybersecurity personnel can provide technical assistance, malware analysis, and indicators of compromise that connect an incident to broader campaigns. The FBI can use subpoena power, international partnerships, and financial tracing to identify threat actors and potentially recover funds.
Reporting to the FBI as early as possible, ideally within hours of confirming a ransomware incident, is recommended. The IC3 portal accepts complaints online at ic3.gov, but organizations facing active ransomware should also contact their local FBI field office directly. The Bureau needs:
- A timeline of the intrusion;
- Known indicators of compromise (file hashes, IP addresses, command-and-control domains);
- The ransomware variant,t if identified, including samples of the ransom note and any encrypted file headers;
- The cryptocurrency wallet address if a ransom demand has been made;
- An inventory of what data was accessed or exfiltrated.
CISA reporting under CIRCIA will carry the force of law for over 316,244 covered entities across 16 critical infrastructure sectors. CISA targeted May 2026 for the final rule but has indicated that ongoing DHS funding constraints may delay publication. Organizations operating in covered sectors should build 72-hour incident reporting workflows now in anticipation of the final rule.
The proposed rule requires covered entities to report significant cyber incidents within 72 hours of a reasonable belief that one has occurred, and ransomware payments within 24 hours, as detailed in a 2026 Fisher Phillips analysis of CIRCIA regulations.
Organizations operating in healthcare, financial services, energy, transportation, IT, and defense contracting should assume coverage and build reporting workflows now, before the final rule publishes. The 72-hour clock starts when an organization reasonably believes an incident occurred, not when the investigation confirms it.
For multinational organizations, notifying the relevant data protection authority in every jurisdiction where affected individuals reside matters. In the UK, breaches must be reported to the Information Commissioner's Office within 72 hours. In Australia, the Australian Cyber Security Center and the Office of the Australian Information Commissioner each have distinct notification obligations. INTERPOL and Europol can assist with cross-border investigations when threat actors operate across jurisdictions.
Industry-Specific Regulatory Reporting Timelines
The regulatory landscape is a patchwork of overlapping deadlines, and none of them pause during a ransomware incident. Missing a notification window, even by a day, can convert a recoverable breach into a compliance enforcement action.
HIPAA requires covered entities and business associates to notify affected individuals without unreasonable delay and no later than 60 calendar days from breach discovery. Breaches affecting 500 or more individuals must also be reported to the HHS Office for Civil Rights contemporaneously with individual notification, and a media notice must be issued. For breaches affecting fewer than 500 individuals, covered entities have until March 1 of the following calendar year to submit an annual log. The 60-day clock is a ceiling, not a target.
The Gramm-Leach-Bliley Act (GLBA) Safeguards Rule requires financial institutions to notify customers as soon as possible following discovery of a breach involving unauthorized access to or use of sensitive customer information.
While the rule does not prescribe a specific day count, the FTC and federal banking regulators have consistently interpreted "as soon as possible" to mean within 30 days. State-level financial privacy laws in New York (23 NYCRR 500) and California impose stricter timeframes, and financial institutions should also file a Suspicious Activity Report with FinCEN when ransomware payments are made.
FERPA requires educational institutions to notify affected students and parents without unreasonable delay following discovery of a breach involving education records. The Department of Education has not defined a specific numeric deadline, but enforcement precedent suggests anything beyond 30 days without compelling justification invites scrutiny.
GDPR Article 33 mandates notification to the relevant supervisory authority within 72 hours of becoming aware of a personal data breach, unless the breach is unlikely to result in risk to individuals' rights and freedoms. Failure to notify within the window can result in fines up to €10 million or 2% of annual global turnover, separate from any fines for the underlying security failure.
When the breach is likely to result in high risk to individuals, Article 34 requires notifying affected data subjects without undue delay. The 72-hour obligation runs regardless of whether the forensic investigation is complete.
State breach notification laws add another layer entirely. All 50 states have enacted breach notification statutes, and most require notification within 30 to 45 days, though several impose shorter windows. Florida requires notification to affected individuals within 30 days, and notification to the Florida Department of Legal Affairs within the same window if 500 or more residents are affected.
California's CCPA creates a private right of action with statutory damages of $100 to $750 per consumer per incident, making timely notification both a regulatory obligation and a litigation risk management strategy. For multi-state breaches, complying with the strictest applicable deadline across all affected states is the safest approach, since the patchwork does not average out.
Preserving Attorney-Client Privilege and Chain of Custody
The single most consequential phone call after confirming a ransomware incident is to outside counsel. Retaining outside counsel first, then having counsel retain the forensic investigator under a clear engagement letter that establishes the investigation's purpose as supporting legal advice in anticipation of litigation, creates the strongest foundation for asserting attorney-client privilege and work product protection. This structure is rooted in the Kovel doctrine.
That foundation is under active assault in federal courts. A series of recent decisions, including Capital One (2020), Rutter's (2021), and Leonard v. McMenamins (2023), have narrowed the scope of protection for post-breach forensic reports. Courts are scrutinizing whether the forensic firm was truly assisting legal counsel or performing a business function that would have occurred regardless of litigation risk.
In Leonard, the court not only denied privilege to the forensic report but also found that communications between counsel and the client, in which the forensic firm was copied, were not privileged when they concerned the facts of the attack rather than legal advice.
As a 2025 Greenberg Traurig analysis of the shifting privilege landscape noted, courts increasingly scrutinize privilege claims for post-breach forensic reports, particularly when forensic firms participate directly in client-counsel communications.
Practical steps to maximize privilege protection include ensuring the engagement letter between counsel and the forensic firm explicitly references the breach's litigation risk and counsel's need for technical analysis to provide legal advice, issuing a litigation hold at the outset of the investigation, and conducting substantive discussions about forensic findings by phone rather than email whenever feasible.
Excluding the forensic firm from email threads that contain pure legal strategy and limiting the internal distribution list for investigation updates to individuals with a genuine need to know also matters, since every additional person copied on an email weakens the privilege claim. Forensic reports should never route through IT or security operations channels separate from the legally directed investigation, since parallel investigations create parallel discovery obligations.
Chain of custody is the operational counterpart to legal privilege. Forensic evidence that cannot be authenticated is inadmissible in litigation and useless for insurance recovery. Documenting every step of the evidence collection process, including who accessed which systems, at what time, using what tools, and what was collected, is essential.
System logs, network flows, memory captures, and disk images must be preserved in their original, unaltered state. Hashing all forensic images immediately upon collection and recording those hashes in a contemporaneous evidence log creates an auditable trail.
Under CIRCIA's proposed rules, covered entities must preserve incident-related records for two years from the date a report was submitted or required. Evidence preservation should be treated as a legal function supervised by counsel, not an IT task. That same chain-of-custody discipline becomes the foundation for the forensic investigation itself, where every preserved log, every hashed image, and every timestamped record lets investigators reconstruct the attack timeline with enough precision to identify exactly what was taken.
Post-Incident Review and Long-Term Security Transformation
Moving from emergency response to systematic improvement requires conducting a blameless after-action review, measuring what worked against defined metrics, and channeling the urgency of the incident into architectural hardening.
Every ransomware event creates a narrow window where leadership is receptive to security investment. Wasting that window means the same attack vector will likely succeed again. The organizations that emerge stronger treat the post-incident phase not as cleanup but as the starting line for a fundamentally different security posture.
1. Conducting a Blameless Post-Incident Review and Documenting Lessons Learned
A post-incident review that devolves into assigning blame produces exactly one outcome: the people who know what happened will never share the full truth. The alternative is a structured, blameless methodology that treats every decision made during the incident as rational, given the information available at the time.
Psychological safety is the non-negotiable foundation. When teams fear retribution, reviews produce sanitized narratives that conceal the systemic failures that actually allowed the cyberattack to succeed, including process confusion, alert fatigue, and unclear escalation paths.
A Dark Reading analysis of post-incident review best practices found that without this cultural foundation, reviews devolve into vague narratives or sanitized reports that gloss over critical failures.
The review itself must document four elements with forensic precision: the full attack path from initial access to encryption; how detection occurred or failed at each stage; the sequence and timing of every response action; and the broader business impact, including systems affected and revenue lost.
Technical logs supply the timeline, while structured conversations with responders supply the context. Understanding why a containment strategy was chosen, perhaps because a runbook was ambiguous or a critical tool was unavailable, reveals far more than logs alone.
After-action findings must convert into a prioritized remediation register. Ranking each action by the business risk it addresses, rather than just technical severity, ensures a patched vulnerability that would have stopped the cyberattack outranks a dozen low-impact configuration tweaks. Assigning every item an owner and a deadline, then tracking completion through the same governance process used for audit findings, closes the loop.
2. Measuring Incident Response Effectiveness: Metrics, KPIs, and Board Reporting
Boards do not fund what they cannot measure. After a ransomware incident, security leaders must translate operational response data into metrics that show whether the organization is actually improving or just getting lucky.
The four metrics that matter most are dwell time, time-to-contain, time-to-restore, and phishing susceptibility rates.
Time-to-contain measures how quickly the response team isolates affected systems once the incident is declared.
Phishing susceptibility rates deserve equal board-level attention because phishing and social engineering remain the dominant initial access vector for ransomware. Tracking click rates on simulated phishing campaigns before and after cybersecurity training interventions, and reporting the delta rather than the absolute number, tells the real story. A 3% click rate that was 12% six months ago signals improvement, while a flat 3% signals stagnation.
Presenting these metrics in a format that boards can act on means showing the trend line, benchmarking against industry peers where data exists, and connecting each metric to a financial consequence.
3. From Emergency Response to Long-Term Security Transformation
A ransomware incident creates a rare organizational moment: the abstract case for security investment becomes concrete, urgent, and universally understood. The worst outcome is letting that moment pass without converting it into architectural change.
Zero Trust architecture should be the first structural investment. Cyberattackers move laterally because most networks still operate on implicit trust once inside the perimeter. Implementing microsegmentation that restricts east-west traffic between workloads, enforcing just-in-time privileged access that expires after use, and requiring phishing-resistant MFA, such as FIDO2 hardware tokens or platform authenticators rather than push notifications that cyberattackers can fatigue-bomb, addresses this gap. Network segmentation alone reduced average recovery time by seven days in organizations that had it in place before a cyberattack.
Identity hardening follows directly from the attack path analysis. If intruders compromised a service account with excessive privileges or exploited a dormant account never deprovisioned, that finding must drive an immediate privileged access review. Eliminating standing admin rights for everyday user accounts and enforcing conditional access policies that evaluate device health, location, and risk signals before granting access to sensitive systems closes the gap.
The transformation must extend to the human layer. Ransomware cyberattackers increasingly use AI-generated phishing, vishing, and deepfake impersonation to obtain initial credentials.
Employees who have practiced recognizing these tactics in realistic phishing simulations are dramatically less likely to become the entry point for the next cyberattack.
4. The Hidden Costs of Ransomware Recovery
Sophos's 2025 data shows the average ransom payment fell to $1.0 million while mean recovery costs, excluding any ransom, reached $1.53 million, and that figure only counts direct restoration expenses.
Lost business dwarfs both figures. IBM's 2024 breach analysis found that lost business costs, covering revenue lost to system downtime, customer churn, and reputational damage, averaged $1.47 million per incident. Customers whose data was exposed or whose operations were disrupted rarely return at full value.
Regulators add another layer of costs. HIPAA fines for healthcare breaches, GDPR penalties in Europe, and a growing patchwork of state-level data protection laws in the U.S. impose penalties that compound for months or years after systems are restored. Litigation from affected customers, business partners, and shareholders routinely follows.
The cost that no balance sheet captures is the human toll. A 2025 Object First survey of 500 U.S. IT professionals found 84% reported feeling uncomfortably stressed at work due to security risks, and 78% feared they would be held personally responsible for a breach.
The weeks of sleepless nights during recovery, the attrition of burned-out incident responders, and the months of second-guessing every alert are real organizational losses that no insurance policy covers. Organizations that invest in employee resilience and realistic security awareness training recover faster and retain the people they need to prevent the next incident.

How Employee Awareness and Training Reduce Ransomware Risk in Incident Response Planning
Ransomware operators depend overwhelmingly on human error to break into organizations. Tricking an employee into clicking a malicious link costs cyberattackers virtually nothing, while weaponizing a zero-day vulnerability demands time, skill, and substantial resources.
According to the Verizon 2026 Data Breach Investigations Report, 62% of confirmed incidents involve a non-malicious human element, and phishing remains the single most common initial access vector cyberattackers use to deploy ransomware payloads. Training employees to recognize and resist these entry points does not eliminate ransomware risk, but it measurably shrinks the attack surface.
Why Does Phishing Remain the Dominant Ransomware Delivery Mechanism?
Phishing is not the most sophisticated cyberattack technique available to threat actors. It is, however, the most reliable. A single convincing email can bypass millions of dollars in perimeter defenses by targeting the one component no firewall can patch: human judgment.
Ransomware groups, including LockBit, ALPHV, and Clop, have refined phishing into an industrial process. They scrape open-source intelligence (OSINT) from LinkedIn, corporate websites, and data broker databases to build emails that reference real projects, real colleagues, and real urgency. The message arrives looking like a late invoice from a known vendor or a shared document from a team leader, and the employee clicks. Minutes later, ransomware encrypts file shares across the organization.
Phishing-initiated breaches remain among the most expensive to contain, with remediation often requiring full network rebuilds, forensic investigation, and regulatory notification. Security awareness training must treat phishing not as a generic warning against clicking suspicious links, but as a structured defense against ransomware's primary on-ramp. Employees who identify a spear phishing attempt before interacting with it become a control point that no technical solution can replicate.
What Makes AI-Generated Phishing and Multi-Channel Cyberattacks Harder to Detect?
The phishing that delivered ransomware in 2019 was recognizable: spelling errors, generic greetings, improbable urgency. The phishing that delivers ransomware in 2026 is grammatically flawless, contextually specific, and frequently arrives across multiple channels simultaneously.
Generative AI enables cyberattackers to craft spear phishing emails that mirror a colleague's writing style, complete with inside references scraped from public sources. These same tools generate convincing voice clones used in vishing calls that follow the email to reinforce its legitimacy, plus smishing messages that appear to come from internal IT or payroll systems.
An employee who dismisses a suspicious email may still respond when the same request arrives by phone minutes later, delivered in a voice they recognize.
Training that covers only email-based phishing leaves employees unprepared for the coordinated attack patterns that ransomware operators now deploy. Effective programs must simulate vishing, smishing, and AI-generated spear phishing alongside traditional email-based phishing simulations so employees build recognition across every channel an attacker might use.
How Do Phishing Simulation Exercises Identify High-Risk Employees Before a Cyberattack?
Phishing simulations function as diagnostic tools, not punitive measures. When an organization runs a simulated ransomware-delivery email, a fake invoice attachment, or a credential-harvesting link disguised as a shared document, the results reveal exactly where human-layer vulnerabilities live.
Finance and human resources departments consistently show higher click rates on business email compromise (BEC) simulations because their roles require opening attachments from external contacts.
Other patterns surprise even experienced security leaders, such as a single executive assistant whose public LinkedIn activity makes them a high-value spear phishing target, or an engineering team that trusts internal-looking technical documents without scrutiny. Simulation data pinpoints these concentrations of risk with precision that annual compliance training never achieves.
This information is actionable. When simulation results show that 12% of the accounting team clicked a vendor impersonation email, the security team can deploy targeted microlearning to that specific group within days, rather than waiting for the next annual cybersecurity training cycle.
The same results inform role-based simulation design, since departments that show susceptibility to credential phishing face increasingly sophisticated credential-harvesting simulations. The feedback loop between testing and security awareness training continuously narrows the gap between where employees are and where they need to be.

Why Does Continuous Microlearning Outperform Annual Compliance Training?
Annual compliance training operates on a broken model. Employees complete a 45-minute module once per year, pass a multiple-choice quiz, and return to their inboxes with no reinforcement until the same module reappears twelve months later. Hermann Ebbinghaus's forgetting curve research demonstrated that without spaced reinforcement, learners forget approximately 70% of new information within 24 hours and 90% within a week. The compliance checkbox gets checked, but the behavioral resistance never forms.
Continuous microlearning reverses this dynamic. Instead of a single annual session, employees receive short, focused modules, typically under ten minutes, delivered at the moment of need. An employee who clicks a simulated phishing link receives immediate cybersecurity training on what they missed and why, then faces a follow-up phishing simulation within weeks to verify the lesson. The content stays current because the platform updates attack scenarios as threat actor techniques evolve, rather than following an annual curriculum calendar.
Fewer employees clicking means fewer opportunities for ransomware payloads to reach the network.
How Does Human Risk Scoring Translate Employee Behavior Into Board-Ready Ransomware Incident Response Metrics?
Security leaders face a persistent communication gap with the board. Technical metrics, such as detection rates, dwell time, and mean time to remediate, mean little to directors who need to understand organizational exposure in financial and operational terms. Human risk scoring bridges this gap by converting employee behavior data into a quantifiable, trendable metric that answers the question boards actually ask: how exposed is the organization, and is that exposure going up or down?
A human risk score aggregates multiple signals: simulation click rates across email, voice, and SMS channels; cybersecurity training completion velocity; OSINT exposure data that reveals what cyberattackers can learn about each employee from public sources; credential breach history; and browser-based behavior signals such as pasting sensitive data into consumer AI tools.
Every data point ties to an observable decision, not a self-reported attitude. The resulting score, visible at the individual, department, and organizational level, gives the board a single number that moves in response to the security team's investments.
This changes the ransomware conversation from reactive to proactive. Instead of briefing the board after an incident about what went wrong, the CISO can report quarterly on which departments reduced their human risk scores, which remain elevated, and what targeted interventions are underway. The score becomes a leading indicator. Rising scores in finance or executive leadership signal elevated ransomware exposure before an incident materializes, giving leaders time to act before a phishing click turns into a full-scale encryption event.

Ransomware Incident Response FAQs
How long does it take to recover from a ransomware attack?
Recovery from a ransomware cyberattack takes an average of 21 to 24 days of downtime before systems are operational again. The Sophos State of Ransomware 2024 report found that full operational restoration can take a median of more than 100 days. Only 35% of victim organizations recovered within one week in 2024, up from 22% in 2023.
Recovery time depends on backup integrity, ransomware variant complexity, whether data exfiltration occurred, and the maturity of the organization's incident response plan. Organizations that deployed AI and automation in their security operations contained breaches in 51 days compared to 79 days without, according to the IBM Cost of a Data Breach Report 2024. The fastest recoveries consistently involve tested, immutable backups and pre-rehearsed restoration procedures.
What should organizations do in the first hour of discovering a ransomware incident?
The first hour after discovering ransomware must focus on immediate containment. Disconnecting all affected systems from the network immediately is the priority, and compromised machines should not be restarted, since this can destroy forensic evidence and, in some cases,s trigger additional encryption routines. Photographing the ransom note serves law enforcement and insurance purposes.
The CISA Ransomware Response Checklist states that if devices cannot be disconnected, powering them down is an acceptable last resort. Simultaneously, the ransomware-specific incident response plan should be activated, and the IR team assembled, including executive leadership, legal counsel, and the incident commander.
Disabling shared drives, VPN connections, and any automated maintenance tasks that could propagate the infection or overwrite clean backup copies, alongside securing and immediately resetting all privileged account credentials on unaffected systems, completes the first hour.
How do ransomware incident response plans differ from general incident response plans?
A ransomware-specific incident response plan builds on the general NIST framework of preparation, detection, containment, eradication, and recovery,y but adds threat-specific procedures that a generic IR plan omits. Ransomware plans must include a pre-determined ransom payment decision framework with defined roles for executive leadership, legal counsel, and cyber insurance carriers.
They require backup integrity verification procedures because ransomware operators routinely target and delete backups before encrypting production data. They specify law-enforcement engagement protocols, including notification thresholds for the FBI and CISA. Ransomware plans also address cryptocurrency acquisition logistics, negotiation procedures, and decryption tool evaluation through resources such as the No More Ransom Project. Critically, ransomware plans mandate immediate disconnection rather than standard network isolation, because ransomware spreads laterally within seconds to minutes.
Can law enforcement or free tools help decrypt files after a ransomware attack?
Yes. Law enforcement agencies and the No More Ransom Project, a joint initiative by Europol, the Dutch National Police, and multiple security vendors, offer free decryption tools covering more than 165 ransomware variants. Before exploring payment, organizations should use the ID Ransomware service to identify the strain and then check the No More Ransom portal for a matching decryptor.
The FBI and CISA can also provide technical assistance and may possess decryptors not publicly available. However, many modern ransomware variants use robust encryption that currently has no known decryption key outside the cyberattacker's control. Decryption tools are typically available for older or operationally disrupted strains where law enforcement has seized cyberattack infrastructure. Organizations with immutable, offline backups have a faster and more reliable path to recovery than relying on decryption tools alone.
Key Takeaways
- Ransomware incident response succeeds or fails based on preparation completed long before a cyberattack begins, including a tested playbook, immutable backups, and rehearsed restoration procedures;
- Containment speed in the first minutes of a confirmed ransomware incident response effort determines whether encryption stays confined to one endpoint or spreads across an entire domain;
- Eradication must address persistence mechanisms, not just the visible ransomware payload, since cyberattackers routinely maintain a foothold that survives surface-level cleanup;
- Recovery should follow a verification-first approach, confirming backup integrity before any restoration begins to avoid reinfection;
- The ransom payment decision sits at the intersection of business continuity, legal liability, and regulatory exposure, with no guarantee that payment restores clean data;
- Regulatory reporting obligations under frameworks including CIRCIA, GDPR, and HIPAA run on parallel and unforgiving timelines that demand pre-built workflows;
- Human risk reduction through cybersecurity training and phishing simulations remains one of the most effective ways to prevent ransomware from gaining initial access in the first place.
The bottom line: Effective ransomware incident response depends on preparation, rapid containment, disciplined recovery, and a security culture that reduces the human-layer risk cyberattackers exploit to gain initial access.
See How Adaptive Security Reduces Ransomware Risk Across Organizations
Ransomware operators continue to target employees through increasingly convincing AI-generated phishing, vishing, and smishing attacks that bypass email gateways and reach the human layer directly. Strengthening ransomware incident response starts long before containment and recovery, with a workforce capable of recognizing the social engineering tactics that deliver ransomware payloads in the first place.
Adaptive Security's AI-powered phishing simulations and security awareness training build real behavioral resistance across an organization's workforce, reducing phishing susceptibility and the human risk that ransomware depends on. The platform identifies high-risk employees through human risk scoring and delivers targeted cybersecurity training to close the gap before cyberattackers exploit it.
Take a self-guided tour of the Adaptive Security platform to see how it identifies high-risk employees and strengthens an organization's last line of defense against ransomware.

As experts in cybersecurity insights and AI threat analysis, the Adaptive Security Team is sharing its expertise with organizations.
Contents