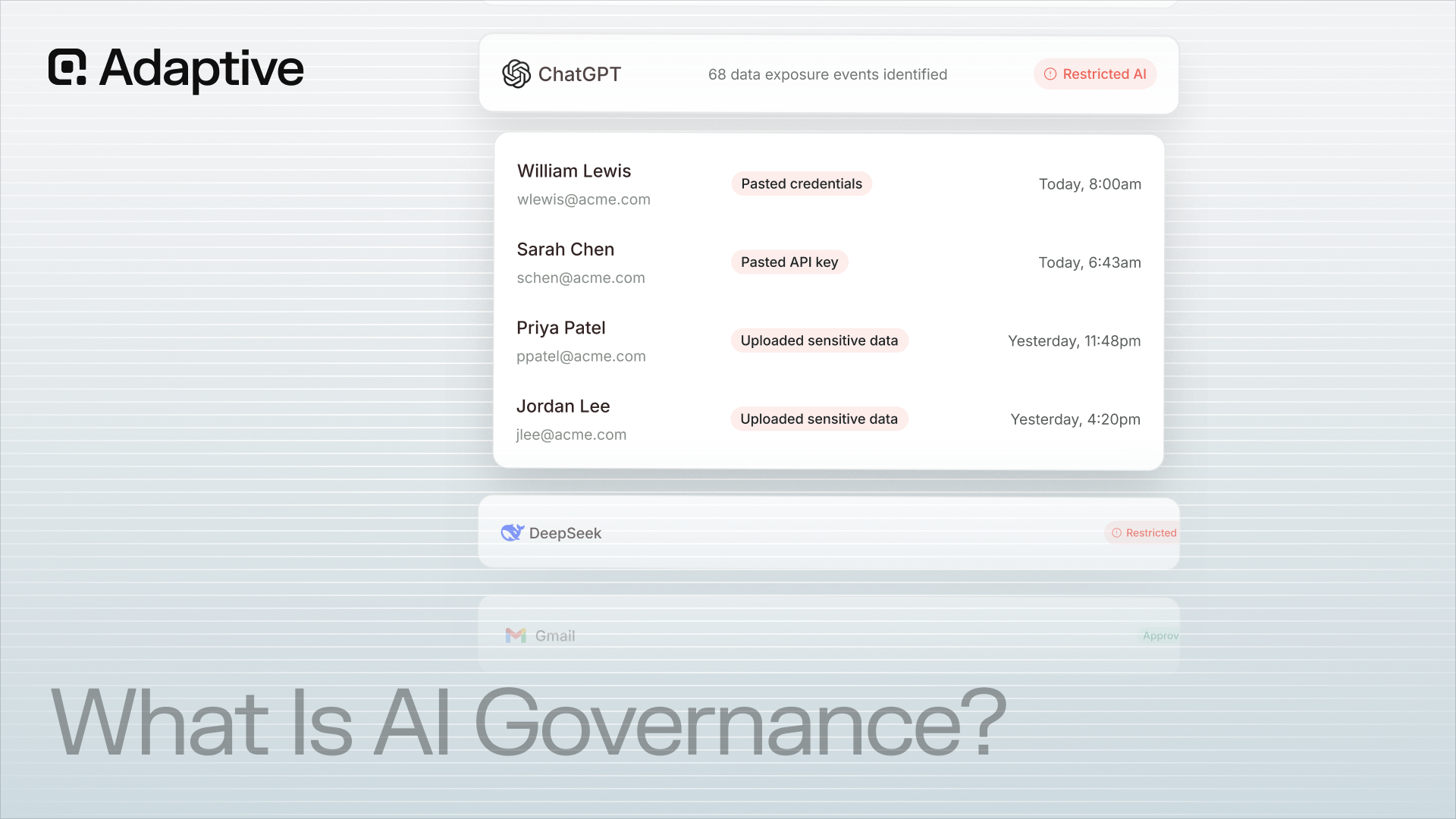

Knowing how to evaluate deepfake detection tools determines whether an organization catches a synthetic CFO demanding an urgent wire transfer or becomes the next headline. The Arup case proved the stakes are not hypothetical: a finance employee approved a multimillion-dollar transfer after joining a video call where every visible participant was a deepfake. Vendor marketing promises near-perfect accuracy, yet state-of-the-art detection systems lose a significant fraction of that accuracy when they move from controlled benchmarks to operational environments, a gap this guide quantifies and explains.

That gap is the difference between flagging a synthetic media cyberattack before funds clear and discovering the breach only after the money is gone. This guide on how to evaluate deepfake detection tools moves past the benchmark scores in vendor decks and into what procurement teams actually need to verify before signing a contract. It includes:
- Why structured evaluation of deepfake detection tools must precede any vendor conversation;
- Which accuracy metrics reveal real performance and which mislead on imbalanced data;
- How forensic analysis, AI classifiers, and trained employees each fit a layered defense;
- What questions a formal RFP must force vendors to answer before an organization commits to deepfake detection tools;
- How detection intelligence feeds cybersecurity awareness training so every near-miss strengthens the human layer.
Detection tools fail silently, and no one realizes until a fraudulent transfer has already cleared. Adaptive Security trains employees across email, voice, SMS, and video to catch the synthetic media that slips past automated screening.
What Deepfake Detection Tools are and why Structured Evaluation Matters
Deepfake detection tools are software systems that analyze images, video, and audio to determine whether content is authentic or AI-generated. They identify telltale artifacts invisible to the human eye: inconsistencies in lighting, unnatural facial motion, audio-visual mismatches, and compression signatures that generative models leave behind. These tools sit at the intersection of digital forensics and machine learning, and no single solution catches every synthetic media variant in every context. Understanding how to evaluate deepfake detection tools starts with understanding the two paradigms the market is built on.
The first paradigm, forensic analysis, examines pixel-level anomalies, compression signatures, and metadata fingerprints. The digital residue that generative adversarial networks (GANs) and diffusion models leave during content synthesis provides the signal forensic tools hunt for. The second, AI-based classification, deploys trained neural networks that learn to distinguish real from synthetic media by processing millions of labeled examples. Most commercial tools blend both approaches, layering forensic heuristics underneath deep learning classifiers to improve robustness across cyberattack types.
How Deepfake Detection Tools are Packaged and Deployed
How a tool is packaged directly shapes which evaluation criteria matter, so anyone learning how to evaluate deepfake detection tools must start with the delivery model. Deepfake detection tools reach buyers through four primary models, each carrying distinct trade-offs that security procurement teams must account for.
- Cloud APIs accept media uploads or stream content through REST endpoints and return a probability score within seconds, which suits organizations that want rapid integration without infrastructure overhead. The trade-off is data sovereignty, because every analyzed file leaves the organization's perimeter and creates compliance friction in regulated industries. Cloud APIs also introduce latency that makes them unsuitable for real-time video conferencing.
- On-premises software keeps all media inside the organization's network, addressing the data residency requirements that financial services, healthcare, and government buyers cannot negotiate away. The cost is deployment complexity, since these engines require GPU-accelerated hardware to process video at production volumes and model updates must be pulled and validated manually.
- Embedded SDKs integrate detection directly into video conferencing platforms, identity verification workflows, and collaboration tools, delivering the lowest latency and the tightest user experience. This model locks detection quality to the SDK version approved during procurement, and upgrading often requires re-certifying the host application, which creates a version-lag problem cyberattackers exploit by targeting known blind spots in older models.
- Browser-based platforms run detection entirely in the user's browser using WebAssembly or JavaScript inference engines, eliminating server-side processing costs and preserving privacy. Detection accuracy takes a measurable hit because browser-based neural networks run quantized versions of full models.
A 2025 comparative study of five detection tools published in the TEM Journal found that commercial solutions achieved up to 98 percent accuracy, while open-source alternatives delivered significantly lower performance. Gaps widened further when tools were constrained to lightweight deployment environments.
Why Structured Evaluation of Deepfake Detection Tools is Non-Negotiable
No deepfake detection tool achieves universal accuracy across all media types, generative architectures, and real-world conditions. Detection models are trained on specific datasets, and a 2025 survey in Discover Computing confirmed that performance degrades sharply when tools encounter deepfakes generated by architectures they were not trained on, a phenomenon researchers call cross-domain generalization failure. An engine that scores 95 percent on FaceSwap-generated content may drop to 60 percent on videos produced by newer diffusion-based generators.
Detection failures carry operational, financial, and reputational consequences that compound quickly. A false negative, labeling a deepfake as real, means a synthetic CFO video call instructing a wire transfer reaches an employee without any warning flag. A false positive, flagging authentic executive communications as synthetic, erodes trust in the deepfake detection tools themselves and creates friction that causes employees to ignore alerts over time.
Without a structured method to evaluate deepfake detection tools, procurement decisions default to vendor claims that cannot be validated against the organization's actual threat profile. A bank facing deepfake video fraud during client onboarding needs fundamentally different detection characteristics than a media company verifying user-generated content at scale. The evaluation rubric must be built before the vendor conversation starts.
Specialist Vendors Compared to Platform Providers
The market for deepfake detection tools splits between two provider types, and choosing between them shapes procurement strategy, total cost of ownership, and detection coverage. This decision is one of the first any team learning how to evaluate deepfake detection tools must resolve.
Specialist vendors dedicate their entire research and engineering effort to detection. They release model updates frequently, publish benchmarks transparently, and compete on accuracy scores. Their tools integrate into existing security stacks but rarely offer adjacent capabilities. Procurement teams choose specialists when detection fidelity is the overriding priority, particularly in forensic, legal, and high-stakes financial contexts where a single missed deepfake carries catastrophic downside.

Platform providers embed deepfake detection as one capability within a broader cybersecurity awareness training platform or threat protection suite. The detection engine may not match a specialist's accuracy on narrow benchmarks, but the platform delivers context that isolated tools cannot: phishing simulation data, employee risk scores, and integrated remediation workflows. For organizations defending the human layer, this matters because detection alone does not stop cyberattacks. Employees who recognize deepfake patterns stop them, and platform providers connect detection to cybersecurity awareness training, creating a feedback loop where exposure data informs skill-building.
The procurement decision hinges on whether deepfake detection is a standalone capability requirement or part of a broader human risk management strategy. Structured evaluation forces that question to the surface before the contract is signed. Building a threat-specific testing regimen then requires clear benchmarks, repeatable protocols, and an understanding of which detection characteristics matter most for an organization's risk profile.
Benchmark scores reveal nothing about detection accuracy against the generators a specific threat profile faces. Adaptive Security connects deepfake exposure data to role-based training so detection gaps become coaching opportunities.
Key Performance Metrics for Evaluating Deepfake Detection Tools
No single metric tells the full story of a detection tool's effectiveness, which is why anyone working out how to evaluate deepfake detection tools must read several metrics together. Accuracy alone misleads when datasets skew heavily toward genuine samples, and precision and recall trade off against each other in ways that directly affect operational outcomes. Flagging too many false positives erodes analyst trust, while missing real deepfakes defeats the purpose entirely. The most rigorous evaluations combine classification metrics, adversarial robustness testing, confidence calibration, and multimodal alignment scores to surface vulnerabilities that any one number hides.
What Core Classification Metrics Reveal About Deepfake Detection Tools
Detection tools are fundamentally classifiers that label content as genuine or synthetic. Each metric exposes a different facet of reliability, and prioritizing the wrong one for an operational context leads to brittle deployment decisions.
For security operations, F1-score and AUC typically carry the most weight because detection datasets are inherently imbalanced. Deepfakes represent a small fraction of total content in most production environments.
How the Deception Success Rate Exposes Adversarial Vulnerability
Standard metrics measure performance against static test sets, but the Deception Success Rate (DSR) measures something more dangerous: how often adversarial samples escape detection. These are deepfakes deliberately engineered to evade classifiers, where cyberattackers add imperceptible noise, compress video, or alter frame rates specifically to bypass detector logic.
A tool with 98 percent accuracy on the DFDC benchmark may collapse to a 62 percent DSR when facing gradient-based adversarial perturbations, which renders it operationally useless against a motivated adversary. Evaluating DSR requires testing against perturbation methods including FGSM, PGD, and compression-based evasion, techniques documented extensively in adversarial robustness research. A detector that has not been stress-tested against these methods has not been tested at all.
Why Confidence Score Calibration Determines Operational Trust
A detection tool that outputs "97 percent confidence, deepfake" for a sample that is actually genuine erodes analyst trust faster than a tool that hedges correctly. Calibration measures how closely a model's reported confidence correlates with its actual prediction accuracy, so a well-calibrated detector's 80 percent confidence predictions are correct roughly 80 percent of the time.
Poorly calibrated tools produce overconfident wrong answers that cause incident response teams to chase phantoms or, worse, dismiss real cyber threats. Reliability diagrams and Expected Calibration Error (ECE) quantify this gap, and an ECE above 0.05 warrants serious scrutiny before deployment. The downstream cost is not theoretical, because every false positive that reaches an analyst consumes time that could have been spent on an actual intrusion.
How Multimodal Alignment Metrics Catch Audio-Visual Deepfakes
Deepfake videos often fail at synchronizing audio with visual elements. Mismatched lip movements, unnatural blink patterns, and temporal misalignment between speech and facial motion are telltale signals that single-modality detectors miss.
CLIPScore measures cosine similarity between CLIP embeddings of the audio and visual streams, flagging semantic inconsistency across modalities. AV-Align evaluates temporal correlation between audio and video frames, detecting frame-level manipulation where lip movements drift from spoken phonemes. Together, these metrics anchor any credible multimodal detection evaluation. The Arup fraud succeeded precisely because the cyberattackers exploited a gap where audio-visual consistency checking was absent from the victim's verification workflow.
What Perceptual Quality Metrics add to Detection Evaluation
PSNR (Peak Signal-to-Noise Ratio) and SSIM (Structural Similarity Index Measure) quantify how closely a synthetic output resembles its source, and higher values correlate with harder-to-detect deepfakes. MOS (Mean Opinion Score), collected from human raters on a 1 to 5 scale, remains the gold standard for perceptual quality assessment.
These metrics serve a dual purpose, because they benchmark generator quality, which in turn establishes how challenging the detection task actually is. A detector evaluated only against low-PSNR, low-SSIM forgeries will report inflated performance that collapses against state-of-the-art generators producing near-perceptually-lossless output. The evaluation is only as honest as the forgery quality it was tested against.
Which ISO/IEC Standards Govern Detection Tool Assessment
Four ISO/IEC standards define the evaluation framework for deepfake detection tools. ISO/IEC 19795-1 governs biometric performance testing, the foundational methodology for measuring false accept and false reject rates that underpin detection metrics. ISO/IEC 30107-1 and 30107-3 define the presentation attack detection framework and testing methodologies, directly applicable to deepfake media evaluated as biometric presentation attacks. ISO/IEC TR 24029-1 provides the technical framework for assessing neural network robustness, covering the adversarial resilience testing that DSR measurements require. ISO/IEC TS 4213 specifies AI system performance evaluation methodologies, ensuring assessment consistency across vendors and deployment contexts.
What Benchmark Datasets a Detection Evaluation Should Reference
Any credible method to evaluate deepfake detection tools must report results on the established benchmark triad. Meta's DFDC (Deepfake Detection Challenge) provides over 100,000 video clips across diverse generation methods, sourced from 3,426 paid actors. Celeb-DF targets high-visual-quality celebrity deepfakes that stress-test real-world detection performance. FaceForensics++ covers multiple manipulation types including face swapping, reenactment, and neural talking heads.
Cross-dataset generalization reveals the real picture. Training on one dataset and testing on another exposes whether a model has learned deepfake artifacts or merely memorized dataset-specific compression patterns that disappear with a different encoder. A detector that excels only on the dataset it was trained on has not learned to detect deepfakes; it has learned to detect that dataset.
A high benchmark score can collapse against samples a dedicated cyberattacker engineers. Adaptive Security pairs automated screening with deepfake simulations that test the human layer those metrics never measure.
Why Laboratory Benchmarks do not Predict Real-World Detection Accuracy
Deepfake detection tools that score above 95 percent in controlled benchmarks routinely drop to 50 percent or lower once deployed against content sourced from social media platforms, messaging apps, and video conferencing tools. Detection tools consistently lose a substantial fraction of their accuracy when transitioning from laboratory conditions to real-world deployment. NIST's GenAI Forensics evaluation program reached the same conclusion: laboratory conditions systematically fail to represent the variability of operational environments. This performance collapse renders vendor-reported benchmark scores functionally meaningless for any security team trying to evaluate deepfake detection tools for procurement.
How Video Compression Degradation Destroys Detection Accuracy
Every major platform applies aggressive compression that strips the forensic artifacts detectors depend on. YouTube re-encodes uploads using VP9 or AV1 codecs, WhatsApp compresses images and videos before delivery, TikTok applies proprietary compression tuned for short-form mobile content, and Zoom dynamically adjusts bitrate based on available bandwidth. Each of these processes introduces quantization artifacts, removes high-frequency signal components, and normalizes pixel-level statistical patterns, which are the exact forensic traces detection algorithms were trained to identify.
Research on social media compression effects (arXiv:2508.08765) confirmed that the varying compression levels social media platforms employ create significant challenges for model generalization and reliability, with prior detection methods degrading substantially in accuracy under compression alone. The practical consequence is stark: a deepfake that passes through WhatsApp before reaching an organization has already been scrubbed of the signal most detectors rely upon.
Resolution Thresholds That Break Detection Performance
Detection performance degrades sharply below specific resolution limits, a vulnerability made worse because most deepfakes encountered in the wild arrive as compressed, downsampled images. A 2026 cross-paradigm evaluation of six publicly accessible detection tools found that all three AI classifiers performed worst on images below 500 pixels on their longest dimension. Detection rates dropped to 44 to 52 percent in this resolution range, despite it containing 60 percent of all deepfakes in the dataset.
Above 500 pixels, FaceOnLive achieved near-perfect detection, while DecopyAI dropped to just 31 percent in the 501 to 1,000 pixel range. The human evaluator in the same study remained stable at 92 to 100 percent across all resolution bins. Humans rely on semantic cues, anatomical inconsistencies, lighting irregularities, and object-level implausibility, that are substantially more resilient to spatial downsampling than the pixel-level statistical features classifiers depend on. Any tool that cannot maintain acceptable detection rates below 500 by 500 pixels is not fit for operational deployment.
Demographic and Cultural Bias as Systematic Error
Detection accuracy is not uniform across populations. The CVPR 2025 AI-Face dataset paper documented that detectors trained predominantly on lighter-skinned, younger faces consistently underperform on darker-skinned and older subjects because the training data overrepresents the former group. These are not marginal effects, and an organization with a globally distributed workforce or customer base cannot assume a detector tested on homogeneous datasets will perform equitably across its actual population.
"Demographic imbalances in training datasets create detection systems that are differentially reliable depending on who is being depicted, which introduces systematic error into any operational deployment," said Dr. Li Lin, computer vision researcher and lead author of the AI-Face: A Million-Scale Demographically Annotated AI-Generated Face Dataset benchmark study presented at CVPR 2025. Any credible attempt to evaluate deepfake detection tools must therefore demand fairness metrics broken down by skin tone, gender, and age.
Why Generation Technique Determines Detector Success or Failure
Not all deepfake generators leave the same fingerprint, and detection tools exhibit starkly generator-dependent performance. GAN-based methods like StyleGAN3 produce artifacts fundamentally different from diffusion-based models like MidJourney or DDPM, while face-swap techniques like SimSwap create yet another signature. The 2026 cross-paradigm evaluation found that all three tested AI classifiers failed entirely on HeyGen, a commercial hybrid platform, correctly detecting zero out of ten images.

On diffusion model outputs, FaceOnLive achieved 100 percent detection on scene images while DecopyAI managed only 45 percent on facial diffusion images. The same study revealed that DecopyAI excelled at StyleGAN3 with 100 percent detection but failed on StarGAN2 at just 10 percent. These results confirm that no single AI classifier provides reliable coverage across the full spectrum of contemporary generation methods, and a tool's performance on one architecture tells a security team nothing about its performance on another.
When Confidence Scores Create a False Sense of Security
The confidence scores most detection tools display alongside their verdicts are dangerously unreliable indicators of prediction accuracy. The 2026 evaluation found that DecopyAI assigned an average confidence of 94.02 percent to false positives, higher than its true positive average of 88.29 percent, meaning the tool was more confident when wrongly flagging real images than when correctly identifying deepfakes.
On false negatives, all three classifiers expressed near-complete certainty that synthetic images were authentic, with deepfake probability scores as low as 0.05 percent for HeyGen images that were entirely generated. A security analyst receiving these outputs would have no basis to suspect tool failure. Current AI classifier confidence scores reinforce correct predictions but provide no warning when the tool is wrong.
False Positives Compared to False Negatives: Two Very Different Consequences
The operational asymmetry between error types is severe. A false positive, where legitimate media is flagged as synthetic, can trigger an internal investigation, damage an executive's reputation, or cause a security team to dismiss a genuine cyber threat communication as a detection error. Forensic analysis tools are especially prone here, and the 2026 evaluation documented InVID and WeVerify correctly detecting 83 percent of deepfakes while misclassifying 62 percent of authentic images as manipulated.
A false negative, where a deepfake passes as genuine, carries the direct consequence of a security breach. The 2026 evaluation also found that when human judgment and automated tool predictions agreed, the joint decision was correct 97 percent of the time, but when they disagreed, the human was correct in 80 to 89 percent of cases. Security teams that evaluate deepfake detection tools should scrutinize false negative rates under operational conditions as the metric that matters most.
NIST's Synthetic Surrogate and Adversarial Testing Approach
NIST's GenAI Forensics evaluation program, launched to address the known shortcomings of static benchmark testing, employs two methodological innovations security teams should understand. First, the program uses synthetically generated reference images as surrogates, controlled synthetic media created specifically to test detector generalization across unseen generation pipelines, rather than relying on fixed benchmark datasets vendors can optimize against. Second, the program deliberately applies adversarial perturbation techniques against detection systems, introducing perturbations designed to bypass detection rather than presenting easy AI-generated images.
This adversarial methodology mirrors what real cyberattackers do: probe detection systems for blind spots and exploit them systematically. For organizations evaluating tools today, the NIST methodology offers a practical framework. Test deepfake detection tools against content generated by the specific architectures the threat model anticipates, at the resolutions and compression levels the organization's communication platforms impose, and under adversarial conditions, rather than against the curated benchmark datasets vendors cite in marketing materials. Security teams that pair automated detection with deepfake phishing simulations build a human-layer safeguard that covers the gaps no detector can close alone.
Benchmark scores collapse the moment a deepfake passes through WhatsApp, Zoom, or a low-resolution upload. Adaptive Security builds the human recognition layer that stays reliable even when automated detection degrades.
Forensic Analysis Tools, AI Classifiers, and Human Judgment: Comparing Deepfake Detection Approaches
Organizations that evaluate deepfake detection tools must choose among three fundamentally different approaches, each with distinct trade-offs in accuracy, transparency, and operational fit. Forensic analysis tools examine pixel-level artifacts and compression signatures to flag anomalies, AI classifiers use trained neural networks to deliver binary predictions at scale, and human judgment, though slower, consistently outperforms both. The core split is diagnostic, because forensic tools achieve high recall but flag authentic images as manipulated at rates exceeding chance, while AI classifiers identify real images reliably yet miss nearly half of all deepfakes. No single approach is sufficient alone, and the evidence demands hybrid workflows that combine automated screening with expert review.
How the Three Detection Approaches Compare
The table below summarizes the cross-paradigm comparison across the six dimensions that matter most for operational deployment, drawing on the first unified evaluation of publicly accessible deepfake detection tools conducted by professional investigators with law enforcement experience.
How Forensic Analysis Tools Perform
Forensic tools operate by exposing statistical inconsistencies invisible to the naked eye. InVID and WeVerify, FotoForensics, and Forensically analyze error level analysis (ELA) residuals, noise distribution patterns, and JPEG compression signatures that break when an image is manipulated or synthetically generated. Their core strength is explainability, because every output, whether a heatmap, a clone detection overlay, or a quantization table, can be traced, reasoned about, and presented as evidence. This transparency makes forensic tools indispensable in investigative and legal contexts where the reasoning behind a determination matters as much as the verdict.
The weakness is specificity. These platforms detect manipulation by finding anomalies, but routine post-processing produces the same statistical fingerprints as malicious editing, so cropping, resizing, and brightness adjustment all trigger anomaly detectors designed to catch tampering. InVID and WeVerify correctly identified only 37.8 percent of authentic images, performing worse than chance because its layered algorithms converged on benign compression artifacts as evidence of manipulation.
Forensically partially mitigates this through granular sensitivity controls, achieving 70.3 percent real detection, though different slider settings on the same image frequently produce contradictory results. Forensic tools also offer no protection against compression-wiped artifacts, since a deepfake re-saved at low quality often loses the statistical traces these platforms depend on entirely.
How AI-Based Classifiers Perform
AI classifiers, including DecopyAI, FaceOnLive, Bitmind, Intel FakeCatcher, and Bio-ID, approach detection as a learned classification task. Trained on large datasets of real and synthetic images, these models extract features from pixel data and return a binary prediction with a confidence score in seconds. Their strength is speed and accessibility, because any user can drag an image into a browser window and receive a result in two to three clicks with no specialized forensic training required. FaceOnLive processes images at 2.5 times the speed of DecopyAI, making it the best candidate for high-volume triage workflows.
The trade-off is opacity. Not one of the evaluated classifiers provides a textual explanation, a heatmap, or an annotated output, so practitioners receive only a verdict and a percentage, and the confidence scores are poorly calibrated for errors. All three classifiers failed entirely on HeyGen outputs, where the commercial hybrid generation platform triggered near-complete certainty from every classifier that those images were authentic.
This generator-specific blindness exposes a structural weakness, because AI classifiers learn architecture-specific artifacts and generalize poorly to unfamiliar generation pipelines. The speed advantage is real, but the absence of interpretable evidence makes standalone classifier output unsuitable for decisions carrying legal or financial consequences.
Which Approach is Right for an Organization
The evidence points away from picking one paradigm and toward combining them. Forensic tools catch what classifiers miss, particularly tampered images and deepfakes from generator families outside the classifier's training distribution, while AI classifiers screen out the authentic images forensic tools routinely mislabel, reducing the false-positive burden on human reviewers. Human judgment resolves the ambiguous cases where both tool categories disagree, since neither automated approach alone matches the accuracy of expert human judgment working alongside tools.
Michael Rettinger and colleagues, authors of the 2026 cross-paradigm evaluation, characterize the two automated approaches as presenting an inverse relationship between usability and transparency. AI classifiers score between 85 and 97.5 on the System Usability Scale but operate as black boxes, while forensic platforms offer full analytical transparency but demand substantial expertise and time.
Organizations that evaluate deepfake detection tools should therefore assess workflow fit before feature lists. A financial crimes unit handling dozens of images per investigation will prioritize forensic depth, while a content moderation team screening thousands of uploads per hour will need classifier speed with forensic escalation paths. Neither paradigm alone satisfies both requirements, which is why practitioners should insist on platforms that expose automated screening results alongside interpretable evidence.
Human judgment outperforms every automated tool, and the data from the 2026 cross-paradigm evaluation proves it. Adaptive Security delivers realistic deepfake exercises that sharpen the perceptual judgment classifiers cannot replicate.
Fundamental Limitations and Blind Spots of Current Deepfake Detection Tools
Organizations that deploy deepfake detection tools without accounting for their irreducible limitations face a dangerous asymmetry, because detection failures stay invisible until the damage is done. University at Buffalo researchers documented algorithms misclassifying Black men as fake 39.1 percent of the time versus just 15.6 percent for white women, a disparity that creates both operational liability and an equity crisis. Detectors trained on legacy GAN-generated datasets routinely fail against diffusion-based media from tools like Midjourney and HeyGen, which produce fundamentally different artifact patterns older models were never taught to recognize. Anyone learning how to evaluate deepfake detection tools must treat these blind spots as procurement criteria, not footnotes.
Why Real-Time Detection Remains the Hardest Problem
Most commercial detection tools are optimized for static or pre-recorded media where deep analysis runs without time pressure. Frame-by-frame artifact inspection, frequency-domain analysis, and temporal consistency checks all require computation that live video streams cannot accommodate. Latency constraints below 200 milliseconds leave no room for expensive forensic analysis, forcing detectors to operate on simplified heuristics. A live-streamed deepfake impersonation during a video conference will almost certainly bypass any tool not purpose-built for real-time inference.
The Multi-Modal gap That Leaves Coordinated Attacks Undetected
Deepfake detection operates in silos, where video detectors analyze visual frames and audio detectors analyze speech waveforms, while almost none analyze both simultaneously. That silo is precisely how sophisticated cyberattacks operate, using a synchronized fake voice and face feed that reinforces the illusion across modalities. When both streams are manipulated in coordination, a video-only detector might flag visual anomalies while an audio-only detector clears the speech, leaving no unified verdict. The Arup fraud in 2024 exploited this gap with coordinated audio and video deepfakes on a single conference call.
What Makes Audio Deepfake Detection Fundamentally Different
Audio detection introduces challenges with no parallel in the visual domain. Language coverage remains sparse, so detectors trained predominantly on English-language speech corpora perform markedly worse on low-resource languages. Accent variability compounds the problem, with non-native and regional accents triggering higher false positive rates. Most critically, codec compression from platforms like Zoom, Teams, and phone networks strips away the high-frequency spectral features audio detectors rely on. A synthetic voice passing through a VoIP codec looks different to a detector than the same voice in a clean WAV file, degrading accuracy in unpredictable ways.
How Diffusion Models Evade Detectors Trained on Legacy Data
The transition from GAN-based generation to diffusion models, used by Midjourney, DALL-E, Stable Diffusion, and HeyGen, has created a generation gap in detection. GANs leave characteristic spatial artifacts including periodic patterns, grid-like textures, and spectral signatures that detectors learned to isolate, while diffusion models generate content through an entirely different denoising process that produces smoother, more natural artifact distributions. A 2024 ACM workshop paper demonstrated that conditional diffusion models can systematically evade detectors through invisible perturbations that preserve visual quality while dismantling the forensic traces detectors depend on.
The Arms Race That Guarantees no Detector Stays Ahead
Deepfake generation and detection co-evolve in a permanent adversarial cycle, where every detection paper published becomes a blueprint for the next generation of generators to defeat. Detector accuracy measured against today's generation methods tells a security team nothing about performance against tomorrow's. Without continuous retraining on fresh cyberattack data, any detector's accuracy decays on a timeline measured in months rather than years, so organizations that treat detection as a one-time deployment rather than an ongoing operational commitment are buying a snapshot of a moving target.
Demographic Bias and the Uneven Consequences of Detection Errors
False positives and false negatives are not distributed equally across populations. When a detection tool flags legitimate content as fake, authentic executive communications get blocked, employee-created media faces unwarranted scrutiny, and organizations risk reputational harm and legal exposure for algorithmic discrimination. False negatives carry even heavier consequences, since an undetected deepfake impersonating a CFO during a merger negotiation or a CEO on an earnings call can trigger fraud, market manipulation, or credential compromise before anyone realizes the failure occurred.

"A detection algorithm's accuracy should be statistically independent from factors like race, but obviously many existing algorithms, including our own, inherit a bias," said Siwei Lyu, PhD, co-director of the UB Center for Information Integrity. The 39.1 percent false positive rate for Black men is not just a fairness metric; it is a direct operational risk for any organization with a diverse workforce, and a reminder that detection tools demand multi-layered human verification protocols rather than blind algorithmic trust.
Every detection tool limitation becomes an opening for cyberattackers to map. Adaptive Security closes the human-layer gaps that real-time, multimodal, and demographic failures leave open.
How to Practically Test and Evaluate Deepfake Detection Tools Before Procurement
The most reliable way to evaluate deepfake detection tools is to validate vendor claims against an organization's own data before any contract is signed. Build a representative test dataset drawn from standard academic benchmarks and augmented with organization-specific media, then run every candidate tool against that dataset while measuring precision, recall, F1, and AUC-ROC simultaneously. Set confidence thresholds that define when results route to human review, and structure the RFP to require documented false positive rates, demographic fairness metrics, and model update cadence commitments. Lab benchmarks rarely translate directly to production conditions.
1. Build a Representative Test Dataset
Start with the three standard academic benchmarks: FaceForensics++, Celeb-DF, and the Deepfake Detection Challenge (DFDC) dataset. These form the backbone of published detection research and let an organization compare vendor claims against peer-reviewed baselines, though they are insufficient on their own. A 2026 systematic review in the journal AI found that transformer-based architectures suffered 11.33 percent cross-dataset performance degradation compared to in-dataset results, while CNN-based models degraded by more than 15 percent.
Augment the academic set with media that reflects the actual threat model. If the organization is targeted by diffusion-generated imagery, include outputs from Midjourney, DALL-E 3, and Stable Diffusion. If executive impersonation is the primary concern, add synthetic video of the leadership team generated with off-the-shelf face-swap and voice-cloning tools. Include compressed video pulled from common collaboration platforms such as Zoom, Teams, and Webex, because compression artifacts degrade detection accuracy in ways pristine academic datasets do not capture. Aim for at least 30 percent organization-specific media in the test corpus.
2. Benchmark Tools Across all key Metrics Simultaneously
Run every candidate tool against the full dataset and measure four metrics on the same pass: precision, recall, F1 score, and AUC-ROC. A vendor quoting 98 percent accuracy is meaningless if the dataset is 95 percent real, since a tool that labels everything authentic would hit 95 percent accuracy while catching zero deepfakes. Demand the confusion matrix of true positives, true negatives, false positives, and false negatives.
Dr. Hany Farid, Professor at UC Berkeley's School of Information and a leading digital forensics researcher, has written extensively on why detection tools fail when moved from curated benchmarks to real-world conditions, because the generation landscape shifts faster than most academic evaluation cycles can accommodate. Measure inference latency under load as well, because a tool that takes 12 seconds per video frame is operationally useless for real-time video call verification.
3. Set Confidence Thresholds and Design Escalation Procedures
Every detection tool outputs a confidence score rather than a binary verdict, so define three zones before deployment: high-confidence fake for auto-block or auto-flag, high-confidence authentic for auto-pass, and the gray zone in between where the escalation procedure lives. Determine what confidence band triggers human review, setting it wide for high-stakes cases such as 30 to 70 percent confidence for financial transactions requiring executive approval via video, and tightening it for lower-stakes content moderation.
Document who reviews gray-zone results, how quickly they must respond, and what evidence the reviewer needs to make a determination. The reviewer should see the tool's explainability output of which facial regions, audio segments, or temporal artifacts triggered the classification, because a score alone is not enough.
4. Structure a Formal RFP to Evaluate Deepfake Detection Tools
The RFP must require vendors to disclose documented false positive and false negative rates on DFDC, Celeb-DF, and FaceForensics++ benchmarks specifically, rather than on a proprietary in-house dataset. Mandate demographic fairness reporting with performance broken down by gender, skin tone, and age group.
Include technical integration specifications: API latency requirements, supported video formats and resolutions, containerization support via Docker and Kubernetes, and on-premises, cloud, or air-gapped deployment options. Require a minimum 95 percent AUC-ROC on the organization's augmented test set as a hard pass/fail criterion. Ask for the model's training data provenance and most recent update date. Specify support expectations in the contract: guaranteed response times for escalations, model retraining cadence, and access to the vendor's research team for adversarial testing.
5. Ask Vendors the Essential Questions
Ask what training data was used and how recently the model was updated, because a model trained in 2023 on FaceForensics++ alone will miss diffusion-based deepfakes entirely. Ask for the documented false positive and false negative rates on each standard benchmark, and ask how the tool performs across demographic groups, requesting the actual numbers rather than an assurance of fairness.
Ask what feedback and explainability the tool surfaces to the analyst, because a black-box fake-or-real output is unacceptable for any security workflow. Ask how the tool is packaged and what deployment options exist, including whether it supports API-only, SDK, or on-premises appliance form factors.
6. Compare Open-Source and Commercial Deepfake Detection Tools
Open-source detectors, such as those built on EfficientNet or Xception backbones trained on FaceForensics++, offer no licensing cost and full model transparency, but they rarely include ongoing updates, explainability dashboards, or production-grade inference APIs. Commercial tools provide service-level agreements, dedicated support, and regular model retraining, though their models are often opaque black boxes. Total cost of ownership for open-source includes the engineering time to containerize, deploy, monitor, retrain, and integrate with existing security workflows, which frequently outweighs commercial licensing within a year for organizations without dedicated machine learning teams.
According to Sumsub's Identity Fraud Report 2025-2026, sophisticated deepfake fraud surged 180 percent year-over-year, with multi-step attacks rising from 10 percent to 28 percent of all identity fraud incidents, making the probability argument for investment straightforward. The generation landscape a detection tool faces today is not the one it will face in six months, so commercial vendors who commit to at least quarterly model retraining cycles close that gap while open-source maintainers rarely keep pace.
7. Evaluate Vendor Reputation, Update Cadence, and Research Contributions
Check whether the vendor publishes peer-reviewed research or contributes to public benchmarks, because a vendor with no published detection methodology and no presence at CVPR, ICCV, or NeurIPS workshops is likely repackaging open-source models with a user-interface wrapper. Ask for the last three model update changelogs, meaning technical release notes documenting training data additions, architecture changes, and benchmark performance deltas rather than marketing summaries.
Speak to reference customers in the same industry who run the tool in production rather than in a pilot, and ask the question that matters most: how many gray-zone escalations the tool generated last quarter and what percentage turned out to be real deepfakes after human review. A tool that flags everything as suspicious is as useless as one that flags nothing.
The only way to know if a detection tool works is to test it against the impersonation scenarios an organization actually faces. Adaptive Security generates targeted deepfake simulations that double as test media for the detection stack.
Deployment, Integration, and Total Cost of Ownership Considerations

Deploying deepfake detection tools in production means evaluating compute requirements, integration touchpoints with existing infrastructure, compliance obligations, and total cost across on-premises and API-based models. Map the infrastructure first to choose the right architecture, then establish data governance guardrails, build redundancy into the detection stack, and define a workflow that connects alerts to human review and remediation. Monitor for model drift continuously, because a detector that worked six months ago may fail against today's generation models.
1. Assess Computational Requirements and Choose Deployment Architecture
Detection models are computationally intensive. On-premises deployment typically requires at least one high-end data-center GPU per concurrent video stream, with storage scaling to roughly 1 TB per 10,000 hours of processed media, while API-based cloud detection offloads compute to the vendor but introduces per-call latency. For organizations processing large monthly media volumes, on-premises deployment often reaches cost parity with API alternatives over time, while real-time use cases like video conferencing demand sub-500-millisecond latency that cloud APIs rarely guarantee at scale.
2. Map Integration Points Across Existing Security Infrastructure
Detection must feed into email gateways for attachment scanning, video conferencing platforms like Zoom and Microsoft Teams for real-time participant verification, SIEM and SOAR systems for alert correlation, and content management pipelines for inbound media screening. Each integration introduces its own API contract and authentication model, so plan for two to four weeks of engineering per major system. SIEM integration is the highest priority, because detection alerts that never reach the SOC are functionally useless, so verify the chosen tool supports syslog forwarding, REST API webhooks, and native connectors for the incumbent SIEM before procurement.
3. Address Data Privacy and Regulatory Compliance Before Sending Media to Third Parties
Sending organizational media to cloud-based detection APIs creates immediate privacy exposure. Under GDPR, video containing faces or voices of EU data subjects constitutes personal data requiring a lawful basis for third-party processing, and HIPAA-covered entities must execute a business associate agreement before protected health information touches any vendor infrastructure. Even outside regulated industries, internal governance policies often prohibit uploading executive communications to external services, so prioritize vendors offering on-premises or private cloud deployment and demand contractual data processing agreements that guarantee no training on customer data and immediate deletion post-inference.
4. Weigh Total Cost of Ownership Across Deployment Models
Total cost of ownership spans infrastructure, licensing, staffing, and analyst training costs (cybersecurity awareness training, or CAT) for the teams who triage alerts, so an honest model accounts for hardware, ongoing electricity and maintenance, per-call API charges, and at least one full-time analyst for triage. According to IBM's Cost of a Data Breach Report 2025, organizations with high levels of incident response planning and testing reduced average breach costs substantially, which reframes detection investment from cost center to risk transfer.
5. Build Failover and Redundancy Into the Detection Architecture
No single detection tool catches everything, so layer a primary engine with a secondary model from a different vendor using a fundamentally different detection approach, such as frequency-domain analysis paired with spatial artifact detection, and route borderline results through the secondary engine. All high-stakes media, including executive communications and financial transaction verifications, should pass through two independent detection passes. If dual-vendor redundancy exceeds budget, train two to three internal analysts on deepfake artifact identification with clear escalation criteria, because a detection architecture without a manual override path is a single point of failure.
6. Establish a Model Drift Monitoring Cadence
Detection models degrade as generation techniques evolve. The NIST AI Risk Management Framework recommends continuous monitoring of AI system performance against defined accuracy baselines, so run a curated benchmark dataset, updated quarterly with samples from emerging generation methods, against the deployed model and track precision, recall, and false positive rate. When accuracy drops below the defined threshold, trigger a model update or vendor escalation, and because most commercial vendors release model updates quarterly, budget for at least that cadence and verify update provenance before deployment.
7. Define the Operational Workflow From Detection Alert to Remediation
A detection alert opens the response process, not closes it. Build a documented workflow: automated detection flags suspicious media, the alert routes to SIEM with a severity score, an analyst triages within 15 minutes for high-severity and four hours for low-severity, and confirmed deepfakes escalate to incident response with pre-defined containment actions. Every step must generate an audit trail.
Post-incident, feed confirmed deepfake samples back into detection tooling and cybersecurity awareness training programs to harden both machine and human detection layers. Organizations that close this loop reduce response time far faster than those treating detection as a standalone tool, because each cycle of detection, triage, remediation, and feedback sharpens the entire security operation against an adversary that never stops retooling.
Redundancy, drift monitoring, and a human escalation path separate a resilient stack from a single point of failure. Adaptive Security supplies the trained human layer and feedback loop that keep detection effective after deployment.
Industry Requirements, Regulatory Landscape, and Investment Justification for Deepfake Detection Tools

Evaluation criteria for deepfake detection tools fracture sharply across industry verticals, because threat surfaces, regulatory exposure, and failure costs differ fundamentally from one sector to the next. The New York Department of Financial Services issued formal guidance in October 2024 requiring regulated institutions to address deepfake risks within their cybersecurity programs, and the Arup CFO impersonation wire fraud demonstrated that a single successful cyberattack can eclipse years of security spending. Selecting tools without reference to industry-specific requirements, the emerging regulatory landscape, and a defensible investment model introduces exposure procurement teams can no longer justify.
How Industry Verticals Evaluate Deepfake Detection Tools Differently
Financial services firms prioritize real-time detection accuracy for executive impersonation during video calls and voice-cloning verification tied to wire transfer authorization workflows, because a bank's primary exposure is not a viral fake video but a fraudulent transfer approved after a deepfake CFO call bypassed human verification. Media organizations invert this priority, since publication integrity demands content authenticity verification at scale, where a single deepfake clip aired as authentic destroys editorial credibility no retraction can repair.
Legal firms require something neither sector demands: chain-of-custody documentation and evidentiary admissibility, so detection methodology must survive Daubert or Frye challenges, making false positive rates, audit trails, and algorithmic transparency discoverable. Government agencies face nation-state deepfake threats, forged diplomatic communications, disinformation campaigns, and election-targeting synthetic media, and often require tools deployable in classified or air-gapped environments where cloud-dependent solutions cannot operate.
What Regulatory and Insurance Pressures are Driving Adoption
The regulatory landscape is hardening faster than most procurement cycles account for. The New York DFS guidance requires covered financial institutions to assess deepfake risks in annual risk assessments, deploy multi-factor authentication resistant to deepfake bypass, and deliver employee training on recognizing synthetic media cyberattacks. The California AI Transparency Act mandates that large AI providers offer free detection tools, and the EU AI Act imposes transparency obligations on deepfake-generating systems. Procurement specifications written in 2026 must anticipate these mandates, because a tool that cannot meet tomorrow's compliance requirements forces an expensive re-procurement within 18 months.
Cyber insurers are reinforcing this urgency, as underwriters increasingly ask whether organizations deploy deepfake detection during application and renewal, and some now require detection capabilities as a condition of coverage for social engineering fraud riders. Organizations without demonstrable detection may face sub-limited coverage, higher retentions, or outright exclusions for deepfake-enabled losses. The ISO/IEC framework provides a procurement anchor, with standards such as ISO/IEC 42001 for AI management systems and ISO/IEC 30107-3 for biometric presentation attack detection giving buyers objective conformance criteria to specify in RFPs and vendor evaluations.
How to Build an Investment Case for Deepfake Detection Tools
Effective investment modeling starts with the cost of a single successful cyberattack, since even mid-market organizations face six- and seven-figure exposure through wire fraud, credential compromise, or ransomware triggered by deepfake social engineering. According to IBM's Cost of a Data Breach Report 2025, the global average breach cost reached $4.44 million, with social engineering attacks carrying above-average price tags due to extended detection and containment timelines.
The model weighs direct financial loss, incident response costs, regulatory penalties, insurance premium increases, and reputational harm against the annual cost of detection tools, staffing, and cybersecurity awareness training, and in most enterprise environments preventing a single deepfake-triggered wire transfer covers many years of detection tooling investment.
How to Justify the Investment to the Board
Boards approve budget based on risk reduction quantified in dollars rather than detection accuracy percentages, so the most effective case translates the deepfake threat into three numbers: the probability of an attempted cyberattack within 12 months, the expected financial loss from a successful cyberattack, and the cost of the detection program.
According to the World Economic Forum's 2026 Global Cybersecurity Outlook, 52 percent of highly resilient organizations indicate that board members receive regular cybersecurity updates. Board member personal liability tracks resilience level, with 30 percent of boards at high-resilience organizations holding liability for cyber breaches compared to only 9 percent at low-resilience organizations. Frame the investment as risk transfer with a known premium and a calculable payout rather than a technical security tool competing for the same budget line as next-generation firewalls.
A preventable deepfake loss explained to a board post-incident can end careers. Adaptive Security delivers the documented training and readiness that regulators, insurers, and boards now expect.
How Deepfake Detection Connects to Cybersecurity Awareness Training Programs
Automated deepfake detection tools and cybersecurity awareness training operate at fundamentally different layers of defense, which is precisely why each layer needs the other. Research published in the International Journal of Computer Trends and Technology found that 78 percent of commercially deployed facial recognition biometric systems were breached using GAN-generated synthetic media in controlled testing, confirming that even advanced detection tools fail regularly. When detection misses a synthetic voice or video, the only remaining safeguard is an employee who recognizes something wrong and pauses before acting.
Why Detection Tools and a Cybersecurity Awareness Training Platform Must Work Together
Detection tools scan for artifacts at the pixel level, including unnatural eye movement patterns, audio-visual synchronization errors, and spectral inconsistencies invisible to the human eye, and they flag and quarantine cyber threats before employees ever see them. Detection tools also carry blind spots, because they cannot inspect deepfakes arriving through unmonitored channels such as a WhatsApp call to an executive's personal phone, a LinkedIn video message, or a voice note on an unsanctioned messaging app. Vectra AI, a threat detection vendor, reported deepfake-enabled vishing surging over 1,600 percent in Q1 2025 compared to the end of 2024 based on its own platform telemetry.
A cybersecurity awareness training platform fills these gaps at the human layer, where employees learn to recognize behavioral red flags no detection tool can assess: a CFO requesting an urgent wire transfer late at night, a vendor insisting on a payment routing change mid-contract, or a colleague asking for credential resets through an unfamiliar channel. Detection tools reduce the volume of cyber threats that reach employees, and trained employees catch what slips through, so neither layer is sufficient by itself.
Building a Feedback Loop From Detection Failures to Cybersecurity Awareness Training
Every deepfake that bypasses automated detection is a cybersecurity awareness training opportunity, so organizations should treat detection failure data, meaning the synthetic media that evaded scanning, as a curriculum update trigger. When detection logs show a specific impersonation pattern succeeding, security awareness teams can update phishing simulation templates and deepfake awareness modules to mirror the exact technique that worked.
This feedback loop transforms detection intelligence into behavioral readiness. A detection tool might flag that a cyberattacker used AI-generated audio of the CEO's voice with a cloned caller ID from the main switchboard. That intelligence feeds directly into the next round of deepfake vishing simulations, so finance and accounting employees rehearse that exact scenario before facing it live. Without this loop, detection data stays trapped in security operations while awareness training content drifts toward generic threats nobody actually faces.
Role-Specific Training for Distinct Deepfake Threat Profiles
Not every employee faces the same deepfake threat profile. Finance teams sit at the center of wire transfer fraud and invoice manipulation schemes, executives are targeted for impersonation as their likenesses are cloned to authorize transactions or extract data from subordinates, and IT staff and system administrators face credential-focused deepfakes where a cyberattacker impersonates a help desk technician to trigger password resets or MFA bypasses. The Arup deepfake video call attack in 2024 illustrates how executive impersonation translates directly into financial loss.
Generic training that treats all employees as facing the same risk wastes attention and leaves critical gaps. Role-specific content ensures a treasury analyst practices recognizing synthetic voice requests for payment rerouting, while an HR director rehearses identifying deepfake video calls requesting employee data disclosures, so each role builds the precise recognition muscle its threat profile demands.
Unifying Detection Data and Human Performance Metrics
Organizations that run deepfake detection tools, phishing simulations, and cybersecurity awareness training in separate silos cannot answer the only question that matters: how resilient the organization is against an AI-powered social engineering cyberattack right now. A unified human risk scoring framework solves this by incorporating detection tool data alongside simulation click rates, training completion, and reporting speed into a single risk score per employee.
When an employee's detection tool shows repeated deepfake video threats targeting their department and their simulation performance shows they clicked on two of the last five deepfake test scenarios, the risk framework flags them for immediate microlearning intervention without waiting for a quarterly CAT cycle. The board sees one number rather than three disconnected dashboards, and the security team gets automated remediation triggers instead of manual correlation work.
What closes the gap is not better detection alone but detection that feeds continuously into human readiness, so when the next synthetic face or voice slips through, someone on the other end already knows what it looks like.
Intelligence trapped in security operations never reaches employees facing the next synthetic CFO call. Adaptive Security unifies detection intelligence, phishing and deepfake simulation results, and training into one human risk score with automated remediation.
Build a Human Layer of Defense Against Deepfake Threats

Organizations that catch a synthetic CFO before a wire transfer clears share one trait: an employee recognized the deception when automated screening did not. That outcome is the goal of any program built around deepfake detection tools, because even rigorously benchmarked systems leave gaps through channels they do not monitor, including unsanctioned messaging apps, personal devices, and live phone calls. The team member who pauses and verifies is the control that closes those gaps.
Adaptive Security builds that recognition capability through a multi-channel cybersecurity awareness training platform that trains employees across email, voice, SMS, and video to spot deepfake indicators in real time. Detection intelligence from the security stack feeds directly into role-specific scenarios, so the exact impersonation techniques that evade automated screening become the next phishing simulation a finance or HR team rehearses.
The result is an organization where detection tools and trained people reinforce each other, every near-miss sharpens the curriculum, and a single human risk score tells leadership how resilient the workforce is against AI-powered social engineering right now. A cybersecurity awareness training program anchored in real detection data turns each employee into an active contributor to detection rather than a passive vulnerability.
No deepfake detection tool alone has ever stopped a determined cyberattacker, because they already favor channels outside technical controls. Adaptive Security builds organization-wide human resilience that closes the gaps automated tools cannot reach.
Frequently Asked Questions About how to Evaluate Deepfake Detection Tools
What Accuracy Rate Should Organizations Consider as a Minimum Threshold When Evaluating Deepfake Detection Tools?
Organizations should require a minimum accuracy of 90 percent measured against in-the-wild benchmark datasets rather than curated academic datasets alone. The Deepfake-Eval-2024 benchmark established this threshold after finding that state-of-the-art models lost up to 50 percent of their AUC performance when moving from academic datasets to real-world media collected from social platforms.
Commercial tools have reported accuracy figures up to 98 percent on the Celeb-DF dataset, according to a 2025 comparative study published in the TEM Journal. Security leaders must demand that vendors report precision and recall separately and disclose performance on independent in-the-wild benchmarks, because a detector with high overall accuracy but low recall will miss genuine deepfakes at an operationally unacceptable rate.
Can Deepfake Detection Tools Identify AI-Generated Audio in Real-Time Phone Calls or Live Video Streams?
Most deepfake detection tools cannot reliably identify AI-generated audio or video in real time during live phone calls or video streams. The overwhelming majority of detection systems are optimized for static or pre-recorded media where they can perform multi-second or multi-frame analysis without latency constraints. A 2026 survey of detection approaches confirmed that real-time detection remains a largely unsolved challenge, with most tools designed for asynchronous analysis rather than live interception.
Specialized audio detection vendors have begun targeting this gap, but such capabilities remain rare, and no widely deployed solution currently provides real-time multimodal detection across both audio and video streams simultaneously. Organizations should treat real-time detection claims with skepticism and validate them through operational testing under live conditions.
How do Open-Source Deepfake Detection Tools Compare to Commercial Solutions in Accuracy and Ongoing Support?
Commercial deepfake detection tools consistently outperform open-source alternatives on both accuracy and operational support. A 2025 comparative study published in the TEM Journal evaluated five tools and found that commercial solutions achieved up to 98 percent accuracy, significantly surpassing the open-source tools tested on the same dataset. The Deepfake-Eval-2024 benchmark reinforced this pattern, with open-source models seeing AUC drop by 50 percent for video and 48 percent for audio when tested against in-the-wild deepfakes.
Beyond accuracy, commercial vendors provide dedicated support, service-level agreements, and regular model update cadences that open-source projects cannot match. Open-source tools offer research transparency and cost advantages but demand in-house machine learning expertise for deployment and ongoing maintenance.
What are the Most Common Reasons Deepfake Detection Tools Fail in Real-World Operational Environments?
Deepfake detection tools fail in real-world operational environments for four primary reasons.
- Platform-specific video compression applied by YouTube, WhatsApp, TikTok, and Zoom strips away the pixel-level forensic artifacts detectors rely on.
- Input resolution degradation below detection thresholds causes models trained on high-resolution media to fail on lower-resolution operational content.
- Tools trained on older GAN-based methods perform poorly against newer diffusion-based content from Midjourney, DALL-E, and Stable Diffusion, which produce fundamentally different artifact patterns.
- Demographic bias in training data creates systematic accuracy disparities across skin tone, age, and accent.
An industry analysis of detection tool failures documented that state-of-the-art detection systems experienced a 45 to 50 percent accuracy drop when moving from laboratory benchmarks to real-world deployment, with some tools falling to just 65 percent accuracy in operational conditions.
How Often Should Organizations Re-Evaluate Deepfake Detection Tools After Initial Deployment?
Organizations should conduct formal benchmark evaluations quarterly and maintain continuous monitoring for model drift between scheduled assessments. The NIST AI Risk Management Framework recommends establishing minimum performance thresholds and regularly reviewing them as both generation and detection technologies evolve.
Deepfake generation methods advance rapidly, with new diffusion-based systems, voice cloning models, and face-swap techniques emerging on a quarterly cadence, each producing artifact signatures that may evade detectors trained on earlier techniques. Annual benchmarks alone are insufficient given the documented speed at which detection model effectiveness decays against evolving generation methods.
Key Takeaways on How to Evaluate Deepfake Detection Tools
- Learning how to evaluate deepfake detection tools starts before any vendor call, because a structured rubric tied to an organization's threat profile prevents procurement from defaulting to marketing claims.
- No single metric proves a tool works, so any effort to evaluate deepfake detection tools must weigh F1-score, AUC, calibration, and adversarial robustness together rather than trusting headline accuracy.
- Laboratory benchmarks do not predict production performance, which is why deepfake detection tools must be tested against compressed, low-resolution, and demographically diverse media that mirrors real conditions.
- Forensic tools, AI classifiers, and trained humans each cover what the others miss, so the strongest deployments combine all three rather than relying on one paradigm.
- The most accurate detector is a trained employee, so cybersecurity awareness training is the layer that catches the deepfakes automated tools let through.
- Detection intelligence should feed a cybersecurity awareness training program in a continuous loop, turning every detection failure into a role-specific coaching scenario.
- Regulatory and insurance pressure now makes documented detection and training a procurement requirement rather than an option for regulated industries.
Even the best-benchmarked deepfake tools leave channels unmonitored, and that is where losses originate. Adaptive Security turns every employee into an active defense across email, voice, SMS, and video.

As experts in cybersecurity insights and AI threat analysis, the Adaptive Security Team is sharing its expertise with organizations.
Contents