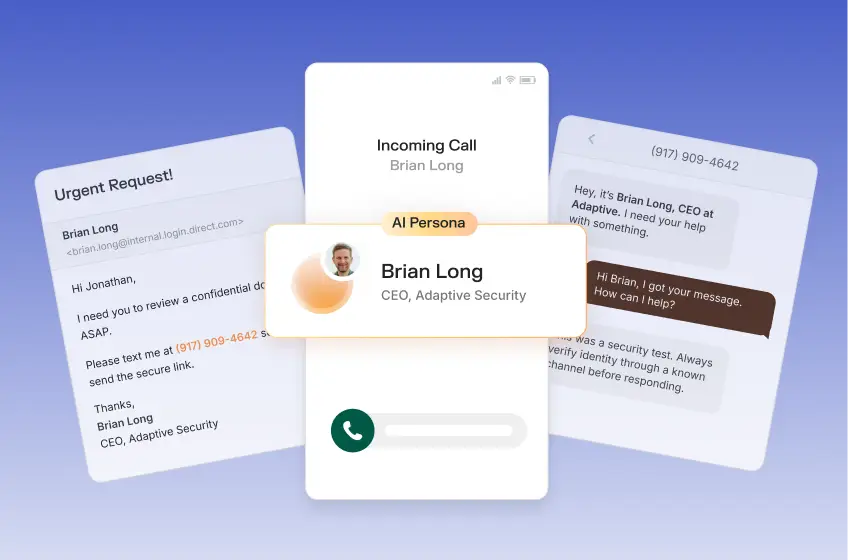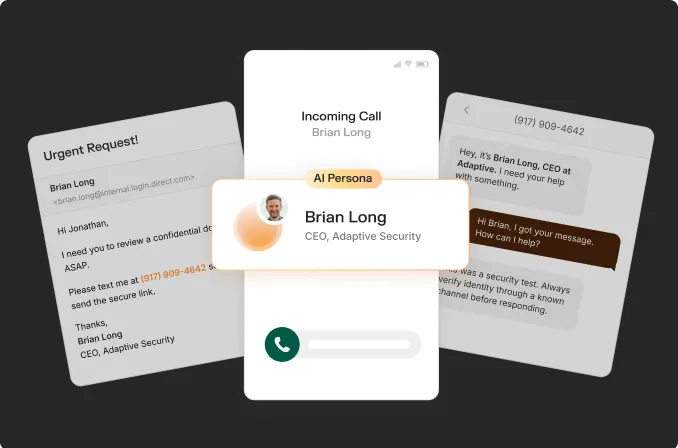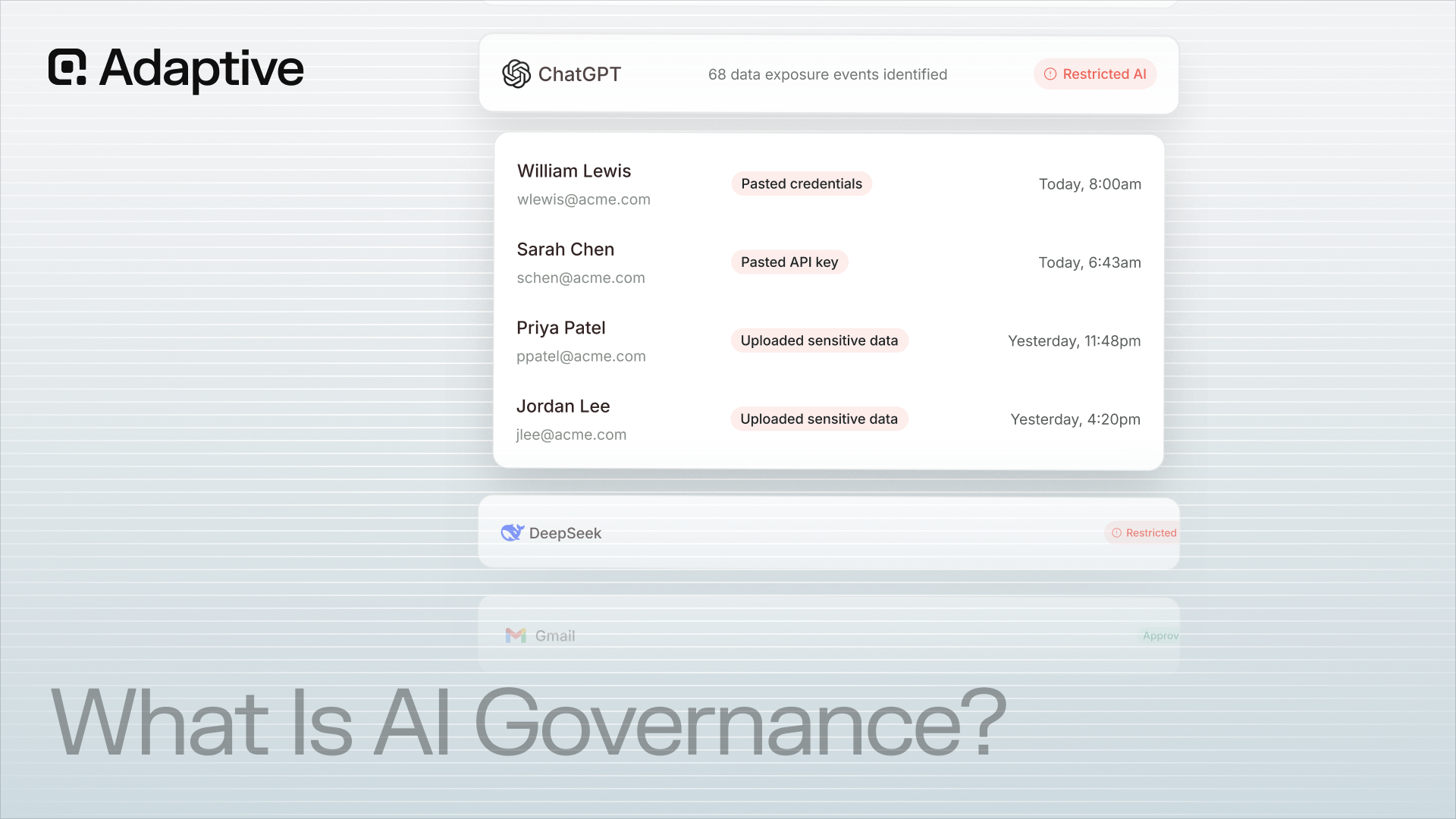

Deepfake detection tools promise to identify AI-generated media before it fuels fraud, disinformation, and targeted social engineering. The gap between vendor benchmarks and real-world accuracy determines whether an organization detects a deepfake attack before it lands or becomes its next victim.
This article provides a structured evaluation framework for security leaders assessing detection tools against their organization's actual threat profile. It covers how forensic analysis platforms and AI-based classifiers work, why accuracy claims collapse in deployment conditions, the technical variables that degrade performance, and the measurable gap between human evaluators and automated tools.
Published cross-paradigm research reveals that vendor-claimed accuracy rates of 92 to 98 percent drop to real-world accuracy of 56 to 79 percent when tools face diverse generation techniques, compressed imagery, and environmental noise, and fall further to 44 to 52 percent on images below 500 pixels in width.
A professional investigator with law enforcement and digital-forensics experience achieved 94 percent accuracy on the same tasks, outperforming the best automated classifiers by 15 percentage points.
Organizations seeking to better understand the deepfake landscape in 2026 are encouraged to watch the Adaptive Security free deepfake webinar.
What Deepfake Detection Tools Are and How They Work
Deepfake detection tools are software platforms that analyze images, video, or audio to determine whether content is authentic or synthetically generated by AI. These tools fall into three main categories: forensic analysis platforms, AI-based classifiers, and biological signal detectors.
Forensic analysis platforms examine low-level signal inconsistencies, compression artifacts, noise patterns, and metadata to expose manipulation traces. AI-based classifiers are trained to recognize the statistical fingerprints left by generative models like GANs and diffusion models, delivering binary verdicts in seconds with no specialist knowledge required.
A third approach, biological signal detection, targets physiological markers such as pulse patterns and eye blinking that generative models consistently fail to replicate convincingly.

How Do Forensic Analysis Tools Detect Deepfakes?
Forensic analysis platforms operate on the principle that any manipulation of digital media leaves detectable traces in the underlying signal structure. These tools apply Error Level Analysis (ELA) to reveal regions saved at different compression levels, noise decomposition to expose synthetic uniformity where natural randomness should exist, and metadata inspection to surface inconsistencies in creation timestamps or device information.
Unlike AI classifiers, forensic tools do not return a binary real-or-fake verdict. They produce visual overlays, heatmaps, and analytical layers that a trained investigator must interpret and cross-reference.
A 2026 cross-paradigm evaluation published on arXiv examined widely used image-forensics tools, including InVID & WeVerify, FotoForensics, and Forensically. The researchers found that these tools can successfully identify many manipulated images, but their effectiveness varies depending on the type of manipulation and the condition of the media being analyzed.
The study also highlighted an important limitation: ordinary processing steps such as JPEG recompression, resizing, or platform-induced modifications can produce forensic signals that resemble evidence of manipulation, making expert interpretation essential when assessing authenticity.
How Do AI-Based Classifiers Detect Deepfakes?
AI-based classifiers take the opposite approach. These deep learning models are trained on massive datasets of real and synthetic images to learn the statistical fingerprints that distinguish authentic content from AI-generated output.
They detect GAN-specific artifacts, checkerboard patterns, anomalies in low-frequency regions, and diffusion model signatures that are imperceptible to human viewers but mathematically distinct from natural image statistics.
These classifiers operate as black boxes. A user uploads an image and receives a binary prediction accompanied by a confidence score, typically within seconds. The underlying model architectures and training data are rarely disclosed, meaning the tools provide no interpretable evidence to support their predictions.
The same 2026 evaluation found that AI classifiers achieve strong real-image detection rates above 91% but miss a substantial proportion of deepfakes. All three tested classifiers failed entirely on images generated by commercial hybrid platforms like HeyGen.
Can Forensic Detection Tools Generalize to Fully AI-Generated Deepfakes?
This question matters because forensic tools were originally designed to detect traditional image tampering: splicing, copy-move forgery, and inpainting. Those techniques leave localized inconsistencies where manipulated regions originate from different source images.
Fully AI-generated deepfakes synthesize entirely new pixel data with globally consistent noise distributions and compression characteristics, eliminating the splicing boundaries forensic methods were built to exploit.
Synthetic images still produce artifacts visible through ELA and noise analysis despite lacking traditional manipulation boundaries. The limitation is forensic depth: no tool in the study could identify which specific generation technique or architecture produced a given deepfake. They can flag suspicious content but cannot explain how it was made.
Where Biological Signal Detection Fits in the Detection Landscape
Biological signal detection occupies a distinct position, targeting features deeply rooted in human physiology that even the most advanced generative models struggle to replicate. Remote photoplethysmography (rPPG) extracts heart rate signals from subtle skin color variations caused by blood flow.
Synthetic faces typically reproduce these patterns as static or unnaturally uniform. Eye blinking frequency analysis exploits the fact that generative models routinely fail to reproduce natural blinking rhythms, with deepfake videos often showing either unnaturally regular blinking or none at all.
A 2025 review published in the Journal of Imaging concluded that physiological detection techniques can provide a valuable complement to traditional forensic analysis. By examining involuntary signals such as blinking behavior, pupil responses, and remote photoplethysmography patterns, these methods exploit characteristics that many current deepfake-generation pipelines reproduce less reliably than facial appearance or speech content.
The trade-off is practical: biological detection methods require high-resolution input and degrade significantly under partial occlusion, poor lighting, or heavy compression. They complement artifact-based methods rather than replacing them, adding a physiological verification layer when image quality permits.
Why Neither Paradigm Is Universally Superior
The 2026 cross-paradigm evaluation revealed a structural complementarity that no single tool resolves. Forensic analysis platforms offer high sensitivity at the cost of frequent false positives. One forensic tool in the study correctly identified only 37.8% of real images, performing worse than random chance.
AI classifiers invert the pattern: strong specificity with real detection rates above 91%, but substantially lower recall for synthetic content. One classifier detected just 48% of deepfakes.
The same 2026 evaluation concluded that "no single tool delivers reliable detection across all generative methods and image categories." The evaluation showed that forensic-analysis platforms and AI-based classifiers exhibited fundamentally different failure modes, suggesting that effective detection may require combining multiple approaches rather than relying on a single technology.
The Accuracy Gap Between Lab Benchmarks and Real-World Performance
Vendors routinely publish deepfake detection accuracy claims between 92% and 98%. The first cross-paradigm evaluation of publicly accessible tools tells a starkly different story.
When trained law enforcement investigators tested six detection tools across 250 images spanning multiple generation techniques, the best-performing automated classifier reached just 79% accuracy while the weakest landed at 56%.
The gap exists because lab benchmarks train and test on the same narrow datasets under clean conditions. Real-world deployments face diverse generative architectures, compressed low-resolution images, and environmental noise absent from academic evaluations.
Forensic analysis tools compensate with high recall. InVID & WeVerify caught 83% of fakes but catastrophically mislabeled 62.2% of authentic images as manipulated. AI classifiers showed the inverse pattern with 91%+ real detection rates but missed more than half of actual deepfakes. No single paradigm delivers the combination of high sensitivity and high specificity that operational environments require.
How Do Lab Benchmarks and Real-World Deepfake Detection Compare?
Three factors drive the performance collapse.
First, training datasets rarely reflect deployment conditions. A model trained on high-resolution celebrity portraits from FFHQ fails when handed compressed surveillance footage or social media screenshots.
Second, overfitting to specific generation techniques produces brittle detectors: all three AI classifiers failed completely on HeyGen, a commercial hybrid generation platform, because its synthetic signatures fell outside their learned decision boundaries.
Third, environmental variables like JPEG recompression, resizing artifacts, and lighting variation trigger false positives in forensic tools and degrade classifier confidence. The researchers noted that AI classifiers perform best on images above 500px, but 60% of deepfakes in their dataset fell below that threshold, pushing detection rates down to 44 to 52%.
Why Accuracy Alone Is a Misleading Metric
Accuracy collapses true positives, true negatives, false positives, and false negatives into a single number that conceals more than it reveals. A tool can achieve high accuracy simply by labeling everything real in a dataset where most images are authentic and still miss every deepfake.
Precision measures what fraction of flagged images are actually fake. Recall measures what fraction of actual fakes the tool catches. F1-score, the harmonic mean of the two, provides the most balanced single-number assessment of operational usefulness.
In the 2026 evaluation by Rettinger et al., the trade-off between recall and specificity proved decisive. InVID & WeVerify achieved high recall, detecting 83% of fake images, but its real-image detection rate fell to just 37.8% because benign JPEG recompression and resizing artifacts were frequently interpreted as evidence of manipulation.
DecopyAI exhibited the opposite failure mode, correctly identifying 93% of authentic images while detecting only 48% of fakes. The researchers concluded that neither forensic analysis nor AI classification alone provides the combination of high recall and high specificity required for reliable investigative workflows.
How Confidence Scoring Produces Dangerous Certainty
Rettinger et al. found that confidence scores produced by several AI-based deepfake classifiers were often poorly calibrated. DecopyAI, for example, assigned an average confidence of 94.02% to its false-positive classifications, exceeding the 88.29% average confidence it assigned to correct deepfake detections.
The problem was even more pronounced for certain image-generation systems. On HeyGen-generated images, which all three evaluated classifiers failed to detect reliably, while BitMind averaged 24.70%.
These findings suggest that confidence scores should not be interpreted as reliable indicators of correctness and should be evaluated alongside independent verification methods and human review.
False Positives vs. False Negatives: Which Risk Carries Greater Weight?
The operational risk profile depends entirely on the use case. A false positive, flagging authentic content as deepfake, carries acute reputational and legal risk in journalism, evidentiary, and content moderation contexts where wrongly discrediting real media can destroy trust and trigger liability.
A false negative, missing an actual deepfake, is catastrophic in financial fraud detection. The $25 million Arup CFO deepfake wire fraud originated with synthetic video that no automated system flagged. In national security applications, a single missed detection can have cascading consequences.
Forensic tools and AI classifiers distribute these risks asymmetrically. Forensic platforms generate high false positive rates because their algorithms interpret routine image processing as manipulation, making them poorly suited for high-volume screening where most inputs are authentic.
AI classifiers produce the opposite vulnerability: high false negative rates on specific generator families mean a determined adversary using a tool like HeyGen can bypass detection with near-certainty.
Organizations evaluating detection tools must decide which failure mode their operational context can least afford and select, or combine, tools accordingly. The data makes clear that no single tool currently handles both risks adequately. What automated tools miss, trained employees equipped with rigorous phishing simulations and deepfake awareness training remain positioned to catch.

Technical Factors That Degrade Detection Performance
Detection tools fail in the field not because their underlying algorithms are broken, but because real-world inputs systematically strip away the signals those algorithms were trained to find.
Rettinger et al.'s 2026 evaluation found that low-resolution imagery remains a major blind spot for AI-based deepfake detection.
Because nearly 60% of the study's deepfake samples fell within this resolution range, the authors identified image size as a critical factor affecting operational detection reliability.
Video compression codecs then erase the frequency-domain artifacts that forensic detectors rely on. Variable lighting, complex backgrounds, and camera angles introduce noise patterns tools misclassify as manipulation evidence.
Together, these technical variables explain the majority of the gap between controlled benchmark scores and the far lower accuracy security teams experience when evaluating real-world content.
How Does Input Resolution Affect Detection Accuracy?
Input resolution emerged as one of the strongest predictors of deepfake-detection performance in the 2026 evaluation by Rettinger et al. When the researchers analyzed results by image dimensions, they found that classifier effectiveness declined substantially on images below 500 pixels in width.
FaceOnLive maintained very strong performance on higher-resolution images but experienced a marked drop on smaller samples, while DecopyAI's accuracy fell significantly within the 501–1,000 pixel range despite relatively strong aggregate results.
The findings suggest that benchmark scores alone may not accurately reflect real-world performance. Organizations evaluating deepfake-detection tools should test them against the image-resolution profiles most commonly encountered in their own environments rather than relying exclusively on vendor-reported performance metrics.
Why Does Video Compression Degrade Deepfake Detection?
Video codecs achieve dramatic file-size reduction by discarding precisely the high-frequency information that forensic detectors depend on. H.264 (AVC) and H.265 (HEVC) apply quantization matrices that smooth pixel-block transitions, suppress subtle texture variations, and normalize the very spatial inconsistencies that Error Level Analysis, noise decomposition, and frequency-domain transforms are designed to surface.
A 2026 study published in Expert Systems with Applications found that video compression significantly reduces the effectiveness of deepfake-detection systems by degrading the visual features and manipulation traces on which many detection methods rely.
The researchers observed that detection performance declined as compression increased, highlighting the challenges of identifying deepfakes in the compressed videos commonly shared through social media, messaging platforms, and online streaming services.
The problem compounds with each lossy pass. A deepfake video recorded from a Zoom call has already been compressed once, then screen-captured and recompressed, then attached to an email where the mail server applies its own compression.
By the time a detection tool analyzes it, the forensic signal has been degraded through multiple codec generations. Tools validated only against uncompressed benchmark footage cannot be expected to generalize to multi-pass compressed inputs.
Security programs that simulate deepfake threats must account for whether their detection tools have been tested under realistic compression conditions, something platforms like Adaptive Security's phishing simulations address by recreating the full delivery pipeline employees actually encounter.
How Do Lighting, Background, and Camera Angle Affect Detection?
Environmental variables degrade detection because they introduce visual noise that classifiers were never trained to interpret. Low-light footage generates sensor noise patterns that mimic the texture inconsistencies forensic tools flag as manipulation.
Harsh directional lighting creates shadow contours and specular highlights that confuse models trained on evenly lit, forward-facing portraits. Background complexity matters independently. A deepfake face composited into a busy office scene with reflective monitors, multiple depth planes, and moving elements produces boundary artifacts nearly impossible to isolate, whereas the same face against a plain backdrop triggers fewer false positives.
Camera angle introduces geometric relationships outside the training distribution. Most detection models learn from frontal and near-frontal faces, so profile views, overhead surveillance angles, and wide-angle lens distortion produce feature ratios the classifier has never encountered, causing confidence scores to become unreliable even on authentic images.
These three variables, lighting, environment, and angle, are virtually absent from curated benchmark datasets yet define nearly every real-world image a detection tool will process, which is why lab accuracy figures rarely survive first contact with operational inputs.
How Does Frame Selection Strategy Change Video Detection Outcomes?
Video deepfake detection forces a decision that static-image tools never confront: a single video contains thousands of frames, but analyzing every frame is computationally wasteful and often counterproductive.
The strategy used to select which frames get analyzed directly determines detection success. Temporal sampling at fixed intervals risks skipping the exact frames where a face-swap glitch or reenactment artifact briefly surfaces before the generator's temporal smoothing erases it.
Quality-based selection that prioritizes the sharpest, best-lit frames often systematically excludes the very moments of distortion that make manipulation detectable, since generative models produce their most visible errors during motion blur, rapid head turns, and occlusion events, precisely the frames a quality filter discards.
Dense sampling across all frames improves recall but hits diminishing returns once temporal redundancy sets in, while sparse sampling reduces compute cost at the expense of missing transient artifacts. No single frame selection strategy generalizes across generator architectures, compression levels, and video lengths.
Detection tools that hard-code one approach will systematically underperform on real-world footage that does not match the selection heuristic's assumptions. When every technical variable from resolution to codec to lighting conspires against reliable detection, security programs built on detection alone leave the human layer exposed to the very deepfake attacks they were designed to stop.
How Detection Tools Fail: Bias, Blind Spots, and Adversarial Pressure
Commercial deepfake detection tools produce a dangerous illusion of safety when they fail, which happens more often than vendor benchmarks suggest.
The AADD-2025 challenge at ACM Multimedia demonstrated that state-of-the-art deepfake detectors remain vulnerable to carefully crafted adversarial perturbations. Participants successfully generated modified deepfake images that evaded multiple detection systems while maintaining high visual similarity to the original content, highlighting the ongoing challenge of building robust forensic classifiers against adversarial manipulation
An attacker who tests synthetic media against the same detection tools an organization deploys before launching a campaign can identify and exploit these failure modes with surgical precision, turning the detector into a liability.
What Demographic and Cultural Biases Exist in Deepfake Detection?
The CVPR 2025 AI-Face benchmark, built from a million-scale demographically annotated dataset, found that deepfake-detection performance varies across demographic groups, including skin tone, age, and gender. Evaluations of commercial and open-source detectors revealed measurable fairness disparities, highlighting that detection accuracy is not uniform across all populations and that demographic factors can influence classification outcomes.
The underlying cause is straightforward: training datasets remain heavily skewed toward lighter-skinned, male, and younger faces.
A 2026 study published in the Journal of Cybersecurity and Privacy found that deepfake-detection performance can vary across demographic groups, including differences associated with skin tone, gender, and age. The authors attribute these disparities primarily to limitations in training data representation and model generalization, highlighting fairness as an ongoing challenge for deepfake-detection systems.
"Current detection techniques often overlook fairness concerns, with significant disparities observed across different attributes, such as gender and race," the FairForensics research team wrote in their 2025 Neural Networks paper. The findings suggest that organizations should evaluate deepfake-detection tools across diverse demographic groups, as uneven performance may result in different levels of protection for different populations.
Which Generative Architectures Defeat Detection Tools Most Frequently?
Not all deepfake generators present equal difficulty for detection tools, and the gap between architectures is widening. Diffusion models, which now power most consumer-grade and commercial deepfake tools including HeyGen, produce synthetic faces that commercial classifiers fail against at dramatically higher rates than older GAN-based outputs.
Detectors have moderately improved against legacy architectures like StyleGAN. Their performance against diffusion model outputs remains critically weak.
StarGAN and other multi-domain translation architectures present a distinct problem: they produce faces that blend attributes across identity boundaries without performing a full face swap.
Most detectors are trained to spot identity-swap artifacts, not within-identity manipulations, making StarGAN outputs a near-total detection failure mode across multiple commercial tools. HeyGen, widely used for real-time avatar generation in video calls, compounds the problem by operating on compressed video streams where detection-relevant high-frequency signals degrade.
The practical implication is that an attacker using a modern diffusion-based pipeline to generate a deepfake video call faces detection odds far lower than any lab benchmark would suggest.
How Do Adversarial Attacks Change the Evaluation Equation?
Attackers do not passively hope their deepfakes evade detection. They actively test and refine them. An adversarial attack means running a deepfake through a known detection tool, observing the classification result, and applying mathematically calculated pixel-level perturbations that flip the verdict from "fake" to "real" while leaving the image visually identical to a human observer.
The RAID dataset, introduced in June 2025, was developed specifically to evaluate the robustness of deepfake detectors against adversarial attacks. Using both white-box and black-box attack methods, results demonstrated that carefully crafted perturbations significantly degraded the performance of multiple detection systems, highlighting persistent vulnerabilities in current deepfake-detection technology.
This changes what organizations must demand from detection vendors. A tool evaluated only on a static benchmark dataset without adversarial testing has an unknown, and likely catastrophic, failure rate against any attacker who understands the detector's architecture.
If a vendor cannot demonstrate that their model holds up under gray-box or black-box adversarial conditions, security teams are buying a detection layer that a motivated adversary can bypass in hours. Organizations evaluating these tools should require evidence of adversarial robustness testing in the vendor's methodology, not just accuracy scores on publicly available datasets.
Audio, Video, and Image Detection: Strengths, Weaknesses, and Multimodal Approaches
Organizations evaluating deepfake detection tools quickly discover a hard truth: no single detector performs equally well across images, video, and audio. Image-based detectors achieve high accuracy on still-frame face swaps by analyzing pixel-level artifacts and GAN fingerprints. But they miss the temporal inconsistencies, unnatural blinking patterns, and audio-visual desynchronization that only reveal themselves across multiple frames.
Video detectors capture those temporal cues, yet they depend heavily on a visual reference frame. This makes them blind to audio-only attacks like vishing and voice cloning that now account for a growing share of fraud incidents. Audio detectors operate in an entirely separate signal domain, analyzing spectro-temporal features that visual tools cannot access, but they offer no protection against silent video deepfakes.
The performance gap across modalities is structural: each detector type was architected for a different forensic surface. Stitching them together through multimodal fusion, analyzing audio and visual streams jointly, consistently outperforms any single-mode approach on video content because it catches inconsistencies that span both channels.
How Does Detection Performance Compare Across Audio, Video, and Image Modalities?
Image-based deepfake detection tools analyze individual frames for GAN-generated artifacts, face warping anomalies, and unnatural texture patterns. These detectors often achieve more than 95% accuracy on benchmark datasets such as FaceForensics++, and many recent models exceed 99% under controlled test conditions.
The problem is that benchmarks age rapidly. Researchers have found that models trained on one generation of deepfake data frequently experience significant performance degradation when evaluated on newer datasets or previously unseen generation techniques, raising concerns about how well benchmark performance translates to real-world environments..
A 2025 review published in Discover Applied Sciences found that many deepfake-detection systems struggle to generalize across datasets and generation techniques. The authors noted that detectors trained on older benchmark datasets often experience significant performance degradation when evaluated against newer diffusion-based synthetic media, highlighting the challenge of keeping detection systems aligned with rapidly evolving generation models.
The review also emphasized that many detection approaches remain modality-specific, meaning image-only detectors cannot assess audio-based manipulation techniques such as voice cloning or audio-visual inconsistencies.
Video detectors add the temporal dimension that image-only tools lack. They track frame-to-frame inconsistencies: irregular blinking frequency, unnatural head movement trajectories, and lip-sync mismatches between spoken audio and mouth shapes.
These temporal features provide a richer forensic signal, though the computational complexity makes real-time analysis difficult. Most commercial video detectors still process visual information only, ignoring the audio track, and when the attack is a voice-only deepfake delivered over a phone call, a video detector is irrelevant.
Audio deepfake detection operates on fundamentally different principles. Instead of pixels and frames, audio detectors analyze Mel-spectrograms, prosodic patterns, and high-frequency artifacts introduced by neural vocoders.
Leading models can identify synthetic speech from GAN-based and diffusion-based voice cloning engines by detecting anomalies in the frequency spectrum that human ears cannot perceive.
Audio quality degradation, background noise, VoIP compression artifacts, and microphone variability introduce false negatives that visual detectors never encounter. Audio detectors also have no access to visual information, meaning they cannot exploit the richest forensic signal in video content: the mismatch between what a viewer sees and what they hear.
What Makes Biological Signal Detection Different From Artifact-Based Methods?
Biological signal detection exploits physiological signals that are present in genuine human faces but traditionally assumed absent from synthetic ones. Techniques like remote photoplethysmography (rPPG) measure subtle skin color variations caused by blood flow, essentially reading a pulse signal from video footage.
Detectors like Intel's FakeCatcher analyze these signals across facial regions, building PPG maps that reveal whether blood flow patterns match those of a living human.
Artifact-based methods take a different path: they scan for GAN fingerprints, blending boundary inconsistencies, unnatural lighting, and warping residuals left by the face-swapping process.
Each approach excels under different conditions and fails under others. Artifact-based detectors perform well against older generation methods where blending seams and resolution mismatches were obvious, but as generation quality improves, these artifacts diminish.
A 2025 study from Fraunhofer HHI, published in Frontiers in Imaging, found that high-quality modern deepfakes can retain valid remote photoplethysmography (rPPG) signals inherited from the source video used to generate them.
DeepFaceLive-generated deepfakes exhibited a median heart-rate correlation of r = 0.89 with their corresponding driver videos, leading the researchers to conclude that the longstanding assumption that deepfakes lack valid physiological signals is no longer reliable for current-generation synthetic media.
The frontier of biological detection has shifted to local blood flow distribution. The same Fraunhofer study found that while global pulse signals transfer from driver to fake, the spatial distribution of blood flow across facial regions does not replicate realistically.
Preliminary experiments using localized rPPG feature maps achieved an AUROC score of 87.4%, suggesting that spatial plausibility analysis, not simple pulse detection, is where biological methods retain an advantage.
Artifact-based methods, meanwhile, are increasingly incorporating transformer architectures that learn to detect generation-model-specific imperfections invisible to earlier CNN-based approaches.
Which Detection Modality Matches the Organizational Threat Profile?
Matching detection modality to threat profile starts with an honest inventory of how the organization is most likely to be attacked. Financial services organizations with high-volume call center operations face a different adversary than media companies verifying user-generated content. Both differ from enterprises defending against CEO impersonation on video calls.
Organizations with primarily voice-based exposure, phone banking fraud, executive vishing, help desk social engineering, should invest in audio-specific detection from vendors whose models are tuned for telephony environments.
Audio detectors trained on studio-quality speech datasets underperform in the noisy, compressed reality of actual phone calls. Organizations that consume or publish video content — media platforms, corporate communications teams, legal evidence handlers, need video detection with multimodal audio-visual fusion, because the strongest forensic signal lives at the intersection of what the target sees and hears.
If exposure is broad, phishing simulations, conference call verification, social media monitoring, a multi-modal platform that spans image, video, and audio detection provides the widest coverage, but expect to manage higher false-positive rates as the detection surface expands. No single detection modality is sufficient for every attack vector.
The organizations best protected against deepfake threats are those that map their specific exposure surface, channels, personas, and content types, and deploy detection where it aligns, rather than buying a single tool and assuming coverage.
Where detection technology identifies the synthetic, phishing simulations that span voice, video, and SMS train employees to recognize and resist it before damage occurs.
Human Evaluators Versus Automated Detection Tools
One of the most notable findings from the 2026 cross-paradigm evaluation by Rettinger et al. was the performance gap between human evaluators and publicly accessible automated detection tools.

How Do Human Evaluators and Automated Tools Compare on Accuracy?
The 2026 evaluation compared six publicly accessible deepfake-detection tools against human evaluators with professional law-enforcement and digital-forensics experience across a dataset of 250 images.
The human evaluator achieved 94% overall accuracy, outperforming the highest-scoring automated system, FaceOnLive, which achieved 79%. DecopyAI achieved approximately 63%.
Performance differences became even more pronounced for certain generation methods. The study documented that the evaluated AI classifiers struggled substantially with HeyGen-generated content, while the human evaluator continued to identify many of those images successfully.
The findings suggest that automated detection systems and human expertise provide complementary capabilities rather than interchangeable ones. They also highlight an important operational challenge: how organizations should resolve cases in which automated detection results conflict with human judgment.
What Does Cohen's Kappa Reveal About Human-AI Agreement?
Cohen's Kappa measures agreement between human and machine classifications beyond what would be expected by chance alone. In the 2026 evaluation, FaceOnLive achieved a Kappa score of 0.54, indicating moderate agreement with the human evaluator but falling short of the threshold typically associated with substantial agreement. DecopyAI and BitMind achieved lower agreement levels.
The results revealed that human and automated assessments diverged on a meaningful number of images. In cases where the human evaluator and a classifier disagreed, the human was correct substantially more often than the automated system.
Conversely, when both human and machine reached the same conclusion, the resulting classification was correct approximately 97% of the time. These findings suggest that agreement between human expertise and automated detection may serve as a useful confidence indicator, while disagreement may warrant additional scrutiny or review.
How Do Usability and Processing Speed Compare Across Tools?
The System Usability Scale (SUS) scores for the three publicly accessible AI classifiers were exceptionally high: BitMind scored 97.5, DecopyAI 92.5, and FaceOnLive 85.0. All three tools required only a few steps from image upload to result, suggesting that investigators could use them effectively with minimal training.
Processing speed revealed a different pattern. FaceOnLive was the fastest system evaluated and showed the most consistent processing times across image categories. By comparison, the human evaluator required an average of 43.02 seconds per image.
Even the slowest automated tool operated several times faster than expert manual review, highlighting the scalability advantages of automated screening for large image collections.
The study illustrates a central trade-off in deepfake detection: automated tools provide speed and throughput, while human evaluators deliver higher accuracy. The findings suggest that hybrid workflows combining automated triage with targeted human review may offer a practical balance between operational efficiency and detection performance.
Which Tools Provide the Most Transparent and Actionable Feedback?
The 2026 evaluation found significant explainability limitations among publicly accessible AI deepfake classifiers. FaceOnLive scored 4 out of 8 on the study's feedback-quality criteria, while DecopyAI and BitMind each scored 3 out of 8. Although the tools provided verdicts and confidence scores, none offered detailed explanations of the features or image regions that drove their classifications.
The forensic-analysis platforms evaluated in the study, FotoForensics, Forensically, and InVID & WeVerify, presented the opposite profile. Rather than issuing binary classifications, they exposed analytical evidence through techniques such as Error Level Analysis, compression-artifact inspection, noise analysis, and clone detection.
These outputs provide greater transparency but require substantial expertise to interpret and can generate false positives when benign image processing artifacts resemble signs of manipulation.
The findings highlight a persistent trade-off between usability and explainability. AI classifiers deliver rapid, accessible verdicts but provide limited insight into their reasoning, while forensic tools offer richer analytical context at the cost of complexity and speed.
The study suggests that neither approach fully satisfies the simultaneous requirements of accessibility, transparency, and accuracy that many investigative environments demand.
Real-Time Detection Versus Batch Processing: Requirements and Trade-Offs
When evaluating how to select a deepfake detection tool, the single most consequential architectural decision is whether the system operates in real time on live video streams or in batch mode on recorded files.
Real-time detection intercepts deepfake content during active video calls before a fraudulent transaction completes. Batch processing analyzes stored media files asynchronously, trading speed for forensic depth.
Real-time voice and fraud-detection systems operate under strict latency constraints, often requiring end-to-end processing within sub-second time budgets (commonly in the 200–500 ms range) to avoid disrupting conversational flow.
Many deployments use GPU-accelerated inference to meet these performance requirements, particularly when running deep neural models, although optimized CPU and edge-based inference pipelines can also satisfy real-time constraints depending on model complexity and system architecture.
This constraint forces lighter model architectures and introduces measurable accuracy compromises compared to offline equivalents. Batch processing faces no such latency ceiling, allowing it to deploy larger, more computationally intensive models that achieve higher precision at the cost of producing results minutes or hours after the media was captured.
The choice is rarely either/or: organizations that authenticate live executive video calls and also forensically review submitted media will find that each mode addresses a fundamentally different threat surface.

Real-Time Detection: Latency Constraints and Infrastructure Demands
The fundamental tension in real-time deepfake detection is that accuracy scales with model size, but latency shrinks with model simplicity. The 2026 study in Human-Intelligent Systems Integration found that while VGG19 achieved 98.9% validation accuracy on deepfake image classification, its larger parameter count increased inference latency, energy consumption, and heat generation. The researchers mitigated this by offloading computation to a server-side REST API rather than running inference directly on the client device.
Infrastructure sizing is straightforward to estimate. Each concurrent video call under analysis requires dedicated GPU memory allocation. An NVIDIA A100 with 80 GB of HBM2e memory handles approximately four simultaneous 1080p streams with a detection model equivalent to VGG19 in complexity.
Latency constraints also force architectural compromises. Real-time systems typically run a single detection model per frame rather than an ensemble, skip computationally expensive preprocessing steps like multi-scale analysis, and operate at reduced input resolution. These trade-offs can drop detection accuracy by 5 to 15 percentage points compared to the same model running offline. These are not implementation failures; they are the unavoidable physics of real-time computation.
Batch Processing: Throughput, Accuracy, and Forensic Depth
Batch processing removes the clock from the equation and replaces it with a queue. A submitted video file enters a job scheduler, runs through whatever pipeline the security team has configured, and produces a detailed forensic report. There is no upper bound on processing time other than the organization's tolerance for delayed results.
This freedom unlocks accuracy gains that real-time systems structurally cannot match. Batch pipelines routinely ensemble three or more detection architectures, combining a CNN-based visual artifact detector with a physiological signal analyzer that checks for unnatural blink rates or micro-expression patterns.
Cross-referencing outputs across models catches edge cases that any single architecture would miss, pushing detection accuracy into the high-90s on benchmark datasets.
Storage architecture becomes the primary scaling constraint. Organizations that retain submitted media for 90 days for compliance or investigative purposes must plan for multi-terabyte object storage with versioning.
The compute side scales more forgivingly: a single GPU node can process a 24-hour backlog of submitted video files in roughly 3 to 4 hours of continuous runtime, meaning most organizations can operate batch detection on 1 to 2 GPUs regardless of monthly submission volume.
Which Architecture Is Right for the Organization?
The decision hinges on the threat model. If an organization has already experienced an executive impersonation attempt over video conference, real-time detection on live calls is non-negotiable.
Organizations whose primary deepfake exposure comes through submitted media, customer onboarding videos, insurance claim evidence, user-generated content moderation, can operate almost entirely in batch mode and benefit from the higher accuracy it enables. The infrastructure footprint is smaller, the per-file cost is lower, and the forensic audit trail is richer.
Most enterprises above 1,000 employees will eventually deploy both. Real-time detection protects the narrow surface of live executive and finance-team video calls, where throughput is low but risk per call is extreme. Batch processing covers everything else. Together they form a detection architecture that neither mode can deliver alone.
Detection tools are only one layer of defense. Even the most accurate real-time system cannot stop an employee from acting on a convincing deepfake if they have never encountered one before. Organizations that pair detection architecture with deepfake phishing simulation training give their teams the practiced instincts to pause and verify, regardless of what the screen shows.
Open-Source Versus Commercial Detection Tools: Trade-Offs and Total Cost of Ownership
Choosing between open-source and commercial deepfake detection tools shapes not just the budget but the team's entire operational rhythm. The primary distinction is not licensing cost but engineering burden. Open-source tools carry zero upfront fees yet demand continuous in-house AI expertise, while commercial platforms convert that same engineering overhead into predictable annual subscription costs that include managed model updates, support, and integration.
Open-source frameworks built on PyTorch or TensorFlow detection architectures offer unrestricted customization and full model transparency. A security team running them internally will spend a substantial portion of dedicated ML engineering hours on retraining pipelines, infrastructure patching, and dependency management rather than threat response.
Commercial tools absorb that operational weight through vendor-managed update cycles and SLAs, though relying on a vendor ties detection capability to a third party's roadmap and release cadence.
Both paths demand sustained investment to keep pace with generative AI. As new face-swap architectures and voice synthesis models ship, the cost of falling behind is measured in missed detections.
How Do Open-Source and Commercial Deepfake Detection Tools Compare Across Key Dimensions?
Upfront cost creates the most visible contrast. Open-source detection libraries cost nothing to download and deploy. Commercial platforms typically charge annual subscriptions ranging from tens of thousands to mid-six figures depending on scale, media types covered, and API volume.
That initial cost gap narrows quickly once organizations account for the engineering team required to keep open-source models current. A single ML engineer salary often exceeds the annual licensing cost of many commercial tools.
Customization flexibility tilts heavily toward open-source. Teams can modify model architectures, retrain on proprietary datasets, and fine-tune detection thresholds for their specific threat profile. Commercial tools constrain customization to configuration parameters and API settings, though the trade-off is that those configurations are tested against known attack patterns before reaching the environment.
Gartner defines deepfake detection as capabilities to detect, analyze, and perform forensics on fabricated, manipulated, AI-generated, or AI-manipulated multimedia, including images, audio, video, and live interactions, when the primary purpose is to deceive or disinform. These capabilities focus on assessing media authenticity and identifying tampering through forensic and analytical techniques applied to digital content.
Open-source tools provide raw detection capability without the integration scaffolding that makes those capabilities operational inside an enterprise security stack. Support quality follows the same pattern. Commercial SLAs guarantee response times and provide escalation paths, while open-source support lives in GitHub issues and community forums with no guaranteed resolution window.
What Is the True Total Cost of Ownership for Open-Source Detection Tools?
On a five-year TCO model, open-source deepfake detection is rarely free. The line items add up quickly: at least one full-time ML engineer to maintain detection pipelines, GPU compute infrastructure for model retraining, and storage for training datasets and inference logs.
When a new generation technique surfaces, such as a novel diffusion-based face swap, the team must source or generate training data, retrain the model, validate accuracy, and deploy the updated pipeline.
Each retraining cycle can consume two to four weeks of focused engineering effort. Across a year, that totals four to eight full retraining cycles, consuming a significant fraction of a senior engineer's total available hours.
This calculation changes for organizations that already maintain a strong internal ML team. Open-source then becomes a marginal cost on existing talent. For organizations without that bench, hiring and retaining deepfake-specific ML engineers in a competitive market shifts the TCO equation decisively toward commercial.
How Frequently Do Detection Models Need Retraining, and Do Commercial Vendors Deliver?
Detection models decay faster than most security teams expect. Every major generative AI release introduces artifacts that existing detectors were never trained to identify. A new Stable Diffusion variant, an improved voice synthesis model, or a novel face-swap GAN architecture can each degrade accuracy within weeks.
Realistic update cadences fall between biweekly and monthly for high-fidelity video detection, and monthly to quarterly for image and audio models. Any update cycle slower than quarterly allows detection accuracy against current-generation deepfakes to degrade measurably.
The best commercial vendors ship model updates on a two-to-four-week cycle and validate each release against a curated adversarial dataset containing the newest generation techniques. Not all deliver on this promise.
When evaluating a commercial tool, ask for the vendor's actual update frequency over the preceding twelve months, not their stated policy. Request the release notes. A vendor who shipped three model updates in the past year while new diffusion models appeared monthly cannot protect an organization against what attackers are deploying today.
How Does Gartner Categorize the Commercial Deepfake Detection Landscape?
Gartner structures the market around two use cases: episodic and industrial disinformation.
Episodic disinformation covers high-profile, one-off incidents. A deepfake video of a CEO announcing false financial results or a synthetic audio clip impersonating a public figure during an election cycle arrives unpredictably and demands forensic-grade analysis on isolated pieces of media.
Industrial disinformation describes the continuous, large-scale production of synthetic media. This includes thousands of fake identity documents, automated deepfake injection during video KYC onboarding, and persistent bot-driven disinformation campaigns targeting a brand across platforms.
This distinction matters for tool selection because the infrastructure requirements differ radically. Episodic detection tools prioritize forensic depth and explainability for a small number of high-stakes investigations. Industrial disinformation tools prioritize throughput, API latency, and integration with automated decision pipelines.
Deploying deepfake phishing simulations across the workforce teaches employees to recognize these attacks before they reach a detection tool at all. By the time a CFO is on a synthetic video call approving a wire transfer, no detection software in the world can undo the damage.
How to Run a Pilot Evaluation Before Procurement
Start by defining evaluation criteria that reflect the organization's actual threat surface, then build a test dataset matching those threats across generative techniques and demographics. Structure a blinded comparison using precision, recall, and F1 rather than headline accuracy. Pressure-test ambiguous results with defined escalation procedures before documenting every finding for a defensible procurement decision.
1. Define Evaluation Criteria Beyond Headline Accuracy Claims
Vendors lead with accuracy figures that collapse under real-world conditions. A tool claiming 98% detection accuracy on a curated benchmark can miss 40% of deepfakes generated by techniques the organization actually faces.
Evaluation criteria should be anchored to the organization's actual threat profile: which generative methods adversaries in the industry use, which executive personas they are most likely to clone, and which delivery channels employees encounter: video conference, messaging app, or email attachment.
Separate must-have criteria from nice-to-have. Throughput speed, API latency, file format support, and integration surface with the SIEM or case management platform all belong in the evaluation matrix alongside detection performance. If the tool cannot return a result within the window the SOC team needs to act, the accuracy figure is irrelevant.
2. Assemble a Representative Test Dataset
The single most common pilot failure is testing on data that looks nothing like what the tool will face in production. Build a dataset that includes multiple generative architectures, diffusion-based face swaps, GAN-generated synthetic faces, neural voice cloning.
A CVPR 2025 study by Lin et al. finds that deepfake detectors exhibit systematic performance disparities across demographic groups, particularly along skin tone, gender, and age categories. The results indicate that models trained on existing datasets can generalize unevenly, with lower accuracy observed for underrepresented demographic groups such as darker skin tones, reflecting underlying dataset imbalance and learned spurious correlations.
Robust evaluation should also include video data captured under varied lighting, compression levels, and resolution conditions representative of real-world communication platforms such as video conferencing and messaging systems.
The dataset needs an equal number of authentic and synthetic samples. Include edge cases: partially obscured faces, low-bitrate audio from mobile calls, and short clips under five seconds where forensic artifacts are minimal. Label every sample with ground truth, authentic or synthetic, generator type, demographic metadata, before the pilot begins.
3. Structure a Blinded Comparison and Measure the Right Metrics
Strip vendor branding from the tools under evaluation and assign each a coded identifier. Provide the same dataset to every tool under identical conditions and time constraints. No vendor gets to tune on the test data beforehand. This prevents the most common gaming tactic: optimizing a model against the evaluation set and reporting those numbers as general capability.
Headline accuracy misleads because it masks how the tool fails. A detector that labels every sample "authentic" achieves high accuracy on a dataset dominated by real videos while missing every deepfake. Measure precision, what percentage of flagged samples are actually deepfakes, and recall, what percentage of all deepfakes the tool catches.
The F1 score, which balances both, is the primary comparative metric. A tool with 92% F1 across diverse generators and demographic groups outperforms one with 99% accuracy on a narrow benchmark every time.
4. Build a Workflow for Ambiguous Detection Results
Every deepfake detector produces confidence scores, not binary verdicts. During the pilot, define what happens when a score falls in the gray zone, say, between 40% and 70% confidence.
Write an escalation procedure: who reviews the flagged media, what forensic checks they run, and how quickly they must respond. Track every ambiguous result through to resolution and measure how often human review overturns the tool's initial classification.
Manual review workflows expose hidden costs. If 15% of all analyzed media lands in the ambiguous zone and each review takes eight minutes, calculate the staffing impact before procurement. A tool with slightly lower F1 but fast, decisive classification will outperform a higher-F1 tool that generates an unmanageable manual review queue.
5. Ask Vendors the Questions That Reveal the Real Product
The demo tells what the tool can do. The following questions tell what it cannot. Demand specific answers, not marketing language, on each:
- Model update frequency: How often is the detection model retrained, and does retraining happen continuously or on a fixed release cycle? Attackers ship new generative techniques weekly; a model last updated in Q2 is already obsolete.
- Training data provenance: What datasets were used to train the detection model, and were any of those datasets scraped from public repositories without consent documentation?
- Demographic bias testing: Request the vendor's most recent bias audit across skin tone, gender, and age cohorts. If they cannot produce one, their tool will fail unevenly across the workforce and customer base.
- Adversarial testing results: Has the tool been tested against adversarially perturbed deepfakes, samples intentionally modified to evade detection? Ask for the degradation curve.
- Integration capabilities: Confirm API documentation, SIEM and SOAR connectors, supported file types, and whether the tool requires media to leave the environment or processes locally.
6. Document Findings for a Defensible Procurement Decision
Produce a structured evaluation report that maps every tool against a predefined criteria. Include raw counts, true positives, false positives, true negatives, false negatives, per tool, per generator type, and per demographic cohort.
Attach the confidence threshold analysis and the manual review burden calculation. This document serves two purposes: it justifies the procurement choice to finance and leadership, and it establishes a performance baseline security teams can test against after deployment to detect model drift.
A procurement decision backed by this methodology stands up to scrutiny because it measures what matters, not what the vendor's marketing slide claims. Before committing a budget, validate that the selected tool can sustain its performance against the generative techniques an organization will actually face, and that the team can operationalize the results without drowning in ambiguous alerts.
For organizations building a detection capability alongside employee readiness, multi-channel phishing simulations that include deepfake scenarios provide the behavioral rehearsal layer that technology alone cannot replace.
Integrating Detection Tools With Existing Security Infrastructure
Map every integration surface the organization actually uses, email gateways, SIEM platforms, video conferencing systems, and identity verification workflows, before evaluating a single tool. Verify that the vendor's API architecture supports real-time detection calls at the latency the security operations require, not just batch processing.
Layer metadata provenance verification through standards like C2PA alongside pixel-level analysis, then design alert routing playbooks that turn detection outputs into automated containment actions rather than analyst queue entries.
1. Map Integration Surface Before Evaluating Any Tool
The integration surprises that derail most deepfake detection deployments trace back to a single mistake: buyers evaluate detection accuracy in isolation without mapping how detection outputs will flow through their existing security stack. A tool that delivers 96% detection accuracy in a lab but cannot feed results into the SIEM is operationally worthless.
Start by inventorying every system where synthetic media enters the organization. This includes the email gateway where deepfake phishing attachments arrive, the video conferencing platform where executive impersonations occur during live calls, and the identity verification workflow where synthetic video could bypass biometric checks.
Each entry point requires a different integration architecture. Email gateways typically consume detection results via REST API calls that flag attachments before delivery. Video conferencing integrations need real-time streaming analysis at sub-second latency. Identity verification workflows add an additional layer of complexity because they must reconcile detection scores with existing authentication decisions.
The 2025 NSA joint Cybersecurity Information Sheet on Content Credentials frames provenance-based approaches as part of a broader multimedia integrity architecture. It emphasizes that Content Credentials provide cryptographically verifiable metadata about the origin and editing history of digital media, contributing to transparency and trust in generative AI environments. Within this broader ecosystem, provenance mechanisms are intended to complement other security and verification controls rather than operate as standalone solutions.
2. Verify API Architecture and Data Format Compatibility
Ask vendors to show their API documentation before signing. Many deepfake detection tools were built as standalone research projects, and their APIs reflect that origin: synchronous-only endpoints, no webhook support, and proprietary JSON schemas that require custom parsers to translate into SIEM-compatible formats.
What security teams need is a RESTful API with webhook-triggered callbacks, support for Common Event Format (CEF) or Log Event Extended Format (LEEF) output, and documented integration guides for at least Splunk, Microsoft Sentinel, or a specific SIEM platform.
Equally important: understand whether the tool processes media locally or requires cloud upload. Tools that require media to leave the environment for cloud-based analysis create data sovereignty and compliance complications, especially in regulated industries.
If cloud processing is required, confirm the vendor's data retention policy, geographic processing locations, and whether media is ever used for model training. These questions surface integration blockers that accuracy benchmarks conveniently ignore.
3. Layer Metadata Provenance Standards Alongside Pixel-Level Detection
Pixel-level deepfake detection, analyzing artifacts, facial inconsistencies, and synthetic generation fingerprints, is necessary but insufficient on its own.
A comprehensive integration framework also verifies metadata provenance: creation timestamps, device signatures, and C2PA Content Credentials that provide cryptographically signed records of a media file's origin and editing history.
The Coalition for Content Provenance and Authenticity (C2PA) specification, progressing toward ISO standard 22144, is backed by steering committee members including Adobe, Microsoft, Google, and OpenAI.
When a video file contains intact C2PA Content Credentials, its embedded cryptographically signed metadata can be used to verify available provenance information such as the capture device, creation context, and any recorded editing steps.
This provenance chain reflects the sequence of actions taken within C2PA-compliant tools and can provide a partial history of how the asset was produced and modified, subject to the completeness of the recorded credentials.
The absence of C2PA metadata does not automatically make the media suspicious. Legitimate content from devices that do not yet embed Content Credentials will lack provenance data. But when detection tools flag a file as potentially synthetic and no C2PA provenance exists, the combined signal is far more actionable than either metric alone.
Build alert routing logic to weight these signals together: a high pixel-level suspicion score plus absent provenance metadata triggers immediate quarantine, while a moderate score with verified C2PA credentials may route for human review instead.
4. Design Alert Routing and Automated Response Playbooks
Detection outputs that land in a dashboard no one watches represent wasted investment. Map alert routing before deployment: high-confidence deepfake detections on inbound emails should trigger automatic quarantine in the email gateway and generate a SIEM alert with severity scoring. Video conferencing detections should fire an API call that drops the suspicious participant from the active call and logs the incident for post-session review.
The goal is to feed detection results into automated response playbooks, not just analyst queues.
For identity verification workflows, a deepfake detection score above a defined threshold should automatically escalate to a secondary authentication factor, a live operator challenge, a hardware token confirmation, or an out-of-band voice verification. This transforms detection from a forensic tool into an active defense layer.
Deloitte's 2025 Technology, Media & Telecommunications analysis argues that deepfake disruption will require a layered defense approach similar to the evolution of cybersecurity, where no single control is sufficient.
The report suggests that media organizations and platforms will likely need to combine multiple detection tools with content provenance and authenticity mechanisms as part of emerging trust frameworks for generative AI systems.
5. Ask These Questions Before Purchase
Integration complexity surprises buyers because vendor demos showcase detection accuracy while glossing over the operational plumbing.
Ask these questions explicitly: Does the API support webhook callbacks for real-time alerting, or is it polling-only? What SIEM formats the tool supports natively, and will the vendor provide the parser configuration? Does detection processing happen locally, in the cloud, or both, and if cloud, where geographically? Does the platform consume or validate C2PA Content Credentials alongside their own detection models? What is the guaranteed API latency at peak concurrent analysis load? Can detection outputs trigger automated actions in our email gateway or video conferencing platform, or does every alert require manual triage?
A vendor that cannot answer these questions with documented evidence has not built their tool for enterprise integration. The answers to these questions determine whether deepfake detection becomes a genuine security control or another shelfware license.
Regulatory and Legal Considerations Shaping Deepfake Detection Tool Selection
Organizations evaluating deepfake detection tools cannot treat the decision as purely technical. The regulatory landscape around synthetic media is hardening rapidly. The tool selected today must satisfy legal obligations that already apply to operations.
According to a January 2026 analysis by Jones Walker, the EU AI Act's transparency provisions for synthetic media take effect in August 2026. From that date, providers of covered generative AI systems must ensure that AI-generated or AI-manipulated content is appropriately marked and detectable as artificially generated, including through machine-readable mechanisms where technically feasible. The analysis situates these requirements within a broader, fragmented regulatory environment governing deepfakes and synthetic media.
Detection tools that cannot validate those markings leave organizations exposed to compliance risk and the underlying fraud those markings were designed to prevent. A patchwork of U.S. state-level deepfake laws, many enacted in 2024 and 2025, imposes criminal and civil liability for the creation and distribution of deceptive synthetic media, creating a compliance obligation for platforms and enterprises handling user-generated or third-party content.
How Does the EU AI Act Shape Deepfake Detection Requirements?
The EU AI Act (Regulation 2024/1689) places transparency obligations on providers of generative AI systems. Article 50 requires that outputs of systems generating synthetic audio, image, video, or text be marked in a machine-readable format and detectable as artificially generated or manipulated.
The UK Information Commissioner's Office 2025 Tech Horizons report highlights these requirements as part of broader regulatory expectations around synthetic media identification. The report specifically notes the growing role of provenance standards and watermarking in meeting those obligations.
For detection tool selection, this creates a practical requirement: the chosen solution must ingest and validate C2PA provenance metadata and watermark-based signals.
Detection tools that rely solely on artifact analysis, looking for visual glitches or audio inconsistencies, miss the compliance dimension entirely. The Act creates a de facto standard where unmarked content flowing into EU-facing systems triggers heightened scrutiny. Organizations deploying detection tools without watermark-validation capability are functionally operating blind to the regulatory signal the law was designed to create.
In a 2025 Computer Law & Security Review study, Dr. Felipe Romero-Moreno examines how emerging regulatory frameworks for deepfakes increasingly emphasize shifting responsibility toward AI system providers and content creators through transparency and provenance requirements.
The study highlights that this regulatory direction relies on technical infrastructures, such as provenance and detection systems, to make synthetic media identifiable and verifiable within broader governance frameworks.
Can Detection Tool Outputs Serve as Admissible Evidence?
Detection tool outputs can support legal proceedings, but admissibility depends almost entirely on the documentation trail behind the result. A detection score without an auditable chain, model version, confidence threshold, input hash, timestamp, and analyst interpretation, is unlikely to survive a Daubert or Frye evidentiary challenge. Courts increasingly expect forensic tools to produce reproducible results with documented error rates.
Organizations handling deepfake evidence for internal investigations, insurance claims, or law enforcement referrals need tools that log every detection event with cryptographic integrity. Some purpose-built platforms now embed C2PA-compliant verification logs directly into their output, creating a defensible record of what was analyzed, when, and with what result. That documentation chain is exactly what evidentiary standards demand.
What Industry-Specific Detection Requirements Should Buyers Prioritize?
Detection requirements diverge sharply by sector. Banking and KYC operations face the most acute exposure: synthetic identity fraud and deepfake video injection attacks during remote onboarding require detection tools integrated directly into identity verification workflows, not standalone forensic analysis suites.
Journalism and media organizations need real-time or near-real-time detection capable of flagging synthetic content during breaking news cycles, where speed of verification determines whether a deepfake propagates unchecked.
Law enforcement and insurance claims investigation demand tool outputs defensible under cross-examination, which elevates audit trail integrity and expert-witness-ready reporting above raw detection accuracy.
Vendor liability developments are pushing detection tool makers toward greater transparency about model limitations, with several states considering legislation that would require disclosure of false positive and false negative rates, making accuracy benchmarking a legal issue as much as a technical one.
Building a Multi-Layered Detection Strategy
Architecting a detection strategy means deploying heterogeneous tools with complementary failure profiles in sequence, starting with forensic analysis platforms that cast a wide net and following with AI classifiers that filter out false positives.
An effective pipeline uses forensic tools for high-recall screening of all inbound media, then routes flagged content through AI classifiers for specificity before escalating only unresolved borderline cases to human analysts. The goal is not finding a single perfect detector. None exists. The goal is building a system where each tool's blind spots are covered by the next.
1. Deploy Tools With Complementary Failure Profiles
A 2026 cross-paradigm evaluation of deepfake detection tools (arXiv:2603.04456v1) finds that forensic analysis systems and AI classifier-based detectors exhibit complementary error profiles.
Forensic tools tend to achieve higher recall for manipulated media but at the cost of lower specificity on authentic content, while classifier-based systems show stronger identification of authentic content but reduced sensitivity to certain deepfakes.
The study suggests that combining these approaches can improve overall robustness by balancing false positives and false negatives, though neither approach fully eliminates detection errors.
2. Sequence Tools Into a Tiered Pipeline
The operational architecture follows three tiers. Tier 1 runs forensic analysis across all inbound media, including error level analysis, noise decomposition, and compression artifact detection. This produces a high volume of flagged items, many of which are benign content that triggered a false positive due to JPEG recompression or resizing artifacts.
Tier 2 routes every flagged item through one or more AI classifiers. Because these classifiers excel at recognizing authentic images, they eliminate the majority of false positives that forensic tools generate. Tier 3 is the human analyst review layer. Only content where forensic tools and AI classifiers disagree, or where multiple classifiers return conflicting results, reaches a person.
This pipeline produces a dramatic reduction in manual review volume. The security operations team reviews only the discordant minority, where human judgment has consistently outperformed automated tools.
3. Measure Return on Investment Across Three Dimensions
ROI for a multi-layered detection strategy is measured in avoided fraud losses, reduced manual review costs, and compliance cost avoidance. On fraud losses, the calculus is direct. Organizations handling high volumes of identity-sensitive transactions can justify detection infrastructure by preventing one such incident per year.
The 2026 cross-paradigm evaluation of deepfake detection tools (arXiv:2603.04456v1) suggests that layered detection pipelines can improve operational efficiency by reducing the volume of media requiring human review.
Because forensic and classifier-based systems exhibit complementary error profiles, combining them allows systems to filter out a portion of clearly classified cases while escalating only ambiguous or discordant outputs for analyst inspection. While the study does not quantify exact time savings or cost reductions, this tiered structure implies a reduction in manual review load compared to single-stage detection approaches.
Compliance cost avoidance is the third and often largest dimension. Regulatory frameworks including GDPR, PCI DSS, and emerging AI-specific legislation increasingly require organizations to demonstrate reasonable detection capabilities for synthetic media threats.
A documented, multi-layered detection architecture with audit trails showing which tools processed which content provides defensible evidence of due diligence that can reduce penalties and streamline audit cycles.
4. Train Security Operations Teams for Sustained Capability
Detection tools produce outputs that require skilled interpretation. The 2026 evaluation highlights that AI classifier confidence scores in deepfake detection are often poorly calibrated under real-world conditions.
The study finds that classifier outputs can exhibit misalignment between predicted confidence and actual correctness, including cases of overconfident incorrect predictions, particularly under distribution shift.
This miscalibration limits the reliability of using confidence thresholds alone for operational decision-making in detection pipelines. Teams that treat confidence scores as calibrated probabilities will be misled. Training must cover three competencies.
First, confidence threshold calibration. Analysts learn to set tool-specific thresholds based on empirical failure patterns in their own environment, not vendor defaults. A classifier that expresses near-certainty on known failure categories like HeyGen-generated content, where all three classifiers in the 2026 study failed entirely, must be treated with calibrated skepticism.
Second, forensic tool interpretation. Error level analysis maps, noise visualizations, and compression artifact indicators require training to read correctly. Analysts must understand that high-saturation foreground elements against contrasting backgrounds routinely trigger false positives in fixed-threshold detectors. Third, borderline case escalation. Teams need clear decision trees for when to escalate.
Discordance, particularly when forensic tools flag content that AI classifiers dismiss, demands escalation to senior analysts who consistently outperform automated tools by recognizing semantic and perceptual inconsistencies the tools miss.
The ability to escalate borderline cases to senior analysts, reinforced through repeated practice, becomes the organization's most durable defense against synthetic media attacks.
How Security Awareness Training Strengthens Deepfake Defense
The gap between tool capability and human judgment is not marginal. Detection models are trained on known generator architectures and fracture when encountering novel generation techniques, compressed media, or channels where detection tools are simply not deployed, such as live video calls and voice channels. The 2026 Verizon Data Breach Investigations Report confirms that the human element was a factor in 62% of breaches, with social engineering remaining the dominant attack vector.
Deepfake-enabled attacks represent the next evolution of these tactics. They deploy the same psychological manipulation amplified by synthetic media that bypasses the visual and auditory trust signals people have relied on for decades.
Why Detection Tools Alone Are Insufficient
Automated deepfake detection faces three structural limitations that make sole reliance on tools dangerous. First, detection models are trained on known generator architectures and generalize poorly to unfamiliar ones.
The 2026 evaluation finds strong generator-dependent variability in deepfake detection performance. The study shows that classifier effectiveness can vary dramatically across different synthetic image generators, with models performing well on outputs from certain GAN architectures while failing to generalize to others, even within the same broader GAN family.
This indicates that many detection systems learn generator-specific artifacts rather than robust, generator-agnostic representations of synthetic content.
Second, real-world media arrives compressed, resized, and re-encoded, degrading the pixel-level statistical features that classifiers depend on. Third, detection tools operate on static files.
They are absent from the live video calls, voice channels, and real-time messaging platforms where deepfake attacks increasingly occur.
What Employees Can Learn to Recognize
Training can transform employees from passive targets into active detectors by teaching them to identify perceptual cues that automated tools overlook. The most reliable indicators include unnatural eye movement patterns, mismatched iris color, asymmetric specular reflections, and irregular blinking rhythms that generative models consistently render incorrectly.
Audio-visual desynchronization, where mouth movements lag slightly behind speech or facial expressions fail to match vocal tone, is another signal that requires no technical expertise to spot.
Contextual anomalies are often the most actionable red flags. A CFO requesting an urgent wire transfer via video call at an unusual hour, or a colleague whose communication style suddenly shifts, should trigger immediate verification.
These are not technical forensic skills but pattern-recognition habits that effective security awareness training builds through repeated exposure to realistic deepfake scenarios.

The Complementary Relationship Between Tools and Training
Deepfake detection tools deliver their full value when embedded in a strong security awareness culture.
Detection tools catch high-confidence synthetic content at scale, while trained employees identify the edge cases that fall through automated filters.
Employees who have practiced recognizing deepfake indicators in controlled simulations are far more likely to report suspicious content that tools miss, and reporting is the bridge between detection and response.
Organizations that invest in both layers create a self-reinforcing cycle. Tools flag threats, employees report tool-missed content, security teams analyze both streams, and the entire system improves.
Frequently Asked Questions About Evaluating Deepfake Detection Tools
What Is the Difference Between Liveness Detection and Deepfake Detection, and Do Organizations Need Both?
Liveness detection and deepfake detection serve fundamentally different security functions. Liveness detection verifies that a biometric sample comes from a live person physically present at capture. It defends against presentation attacks such as printed photos, video replays, and 3D masks.
Deepfake detection analyzes media content to determine whether AI generated or manipulated it, regardless of how the content is presented. Most organizations need both because they address different attack vectors. Liveness protects biometric authentication workflows, while deepfake detection guards against AI-generated content entering through email, messaging platforms, video conferencing, and social media.
Paravision's analysis of evolving fraud threats argues that modern identity systems must combine liveness detection and deepfake detection as complementary safeguards. Liveness detection targets physical presentation attacks such as photos, masks, and display-based spoofing, while deepfake detection addresses digitally manipulated or AI-generated facial content.
Together, these mechanisms form a layered approach to mitigating fraud across both physical and digital attack surfaces in identity verification systems.
Can Deepfake Detection Tools Reliably Detect Audio, Video, and Image Deepfakes Equally Well?
No single deepfake detection tool performs equally well across audio, video, and image modalities. Each modality presents distinct detection challenges. Image classifiers analyze spatial artifacts and pixel-level inconsistencies.
Video detectors must additionally evaluate temporal coherence across frames. Audio detectors rely on spectral analysis and voice biometric patterns that are fundamentally different from visual signals.
A 2025 study in Computer Law & Security Review analyzes deepfake detection within a broader legal and technical framework and finds that no single detection approach is sufficient across all contexts. It highlights that different classes of tools, including AI-based classifiers, forensic analysis methods, and provenance-based systems, exhibit varying strengths and limitations depending on the type of synthetic media and deployment scenario.
The study therefore argues for context-dependent selection of mitigation strategies, aligning detection tools with specific threat models and risk environments rather than relying on universal solutions.
For video content, multimodal approaches that analyze audio and visual streams together consistently outperform single-mode analysis, but no vendor offers equal-strength detection across all three modalities.
What Role Does Metadata Verification Play Alongside Pixel-Level Analysis in Evaluating Detection Tools?
Metadata verification and pixel-level analysis address different layers of media authenticity and must be deployed together. Metadata verification examines file-level information such as creation timestamps, device signatures, geolocation tags, and C2PA provenance credentials that cryptographically attest to an asset's origin and edit history.
Pixel-level analysis, by contrast, examines the visual content itself for generative artifacts, noise pattern inconsistencies, and biological signal anomalies.
The NIST AI 100-4 Report on Reducing Risks Posed by Synthetic Content (published November 2024) distinguishes between provenance-based techniques, such as metadata tracking and cryptographically signed content credentials, and content-based synthetic detection methods that analyze signals within the media itself.
It notes that these approaches are complementary and are often most effective when used together, as each has limitations when applied in isolation across diverse types of synthetic content.
A comprehensive evaluation framework requires both. Metadata verification catches well-formed deepfakes that pass visual inspection, while pixel-level forensic analysis flags synthetically generated content that carries fabricated or stripped metadata.
How Should Organizations Handle Ambiguous Detection Results With Confidence Thresholds and Escalation Procedures?
Organizations should establish tiered confidence thresholds paired with predefined escalation paths before deploying any deepfake detection tool. Set a high-confidence threshold above which detections trigger automated blocking or quarantine. Define a middle band where results are routed to trained human reviewers.
These security analysts cross-reference detection outputs against contextual indicators such as communication patterns, source reputation, and organizational context. Results below a minimum confidence floor should be dismissed to avoid alert fatigue. Each threshold must be calibrated to the organization's risk tolerance.
A financial institution processing wire transfer confirmations will set more conservative thresholds than a marketing team screening user-generated content. Document these procedures during the pilot evaluation phase and validate them against a representative test dataset that includes known ambiguous cases.
How Do Adversarial Attacks Targeting Deepfake Detectors Affect the Evaluation Criteria Organizations Should Apply?
Adversarial attacks systematically degrade deepfake detector performance by exploiting weaknesses in how detection models classify content.
Attackers test their deepfakes against known detection tools before launching, applying perturbations such as subtle pixel-level modifications, compression passes, or noise injection that cause classifiers to misclassify fake content as authentic.
A 2025 study on adversarial attacks against video-based deepfake detection models finds that gradient-based adversarial perturbations, such as FGSM attacks, can significantly reduce detection accuracy across multiple model architectures.
The evaluation shows that even small input modifications can degrade classifier performance, highlighting a systemic vulnerability in current deepfake detection systems. The study also notes that robustness can be partially improved through adversarial training and defensive preprocessing techniques.
Organizations must require vendors to disclose adversarial robustness testing results, model update cadences, and whether their training data includes adversarially perturbed samples. Detection tools that have not been evaluated against adversarial pressure will underperform against determined attackers, making human-layer training an essential complementary defense.
See How Adaptive Security Reduces Deepfake Risk Across the Organization
Deepfake detection tools alone cannot stop every attack. Adversaries test their deepfakes against detection tools before launching them, and novel generation techniques routinely evade automated screening. Combining deepfake awareness training with multi-channel phishing simulations builds a human detection layer that catches what automated tools miss.
Take a self-guided tour of the platform to see how Adaptive Security combines deepfake awareness training with multi-channel phishing simulations.

As experts in cybersecurity insights and AI threat analysis, the Adaptive Security Team is sharing its expertise with organizations.
Contents