
How to detect deepfake AI videos is now a skill with direct financial consequences. In 2024, a single deepfake video call cost engineering firm Arup $25 million after a finance employee wired funds to fraudsters posing as company executives, with no verification challenge made at any point during the call. The synthetic media that enabled that loss is scaling fast. According to Sumsub's Identity Fraud Report 2025, AI-driven sophisticated fraud combining synthetic identities, social engineering, and deepfakes rose 180% year over year.

This guide works through every layer of deepfake AI video detection signs that hold up in practice, then explains why passive artifact analysis weakens as generative models improve.
- The specific visual artifacts that expose a synthetic face, framed as practical ways to spot a deepfake AI video during review.
- The audio tells that separate a cloned voice from a genuine one, and the combined cues that identify deepfake AI videos with greater reliability.
- The behavioral challenges that surface a live deepfake on a video call, the clearest deepfake AI video red flags available without software.
- The detection tools available in 2026 and a clear action protocol for individuals and security teams who encounter a suspected deepfake.
Synthetic executives are already authorizing transfers that real verification would have stopped cold. Adaptive Security trains employees to recognize deepfake video and voice cues before a fraudulent call reaches a payment approval.
What Is a Deepfake Video and How the Technology Works
A deepfake video is AI-synthesized media in which a real person's face, voice, or body movements are replaced or fabricated using generative models trained on that person's actual likeness, making them appear to say or do things they never did. Understanding the mechanism is the foundation for how to detect deepfake AI videos, because each generation method leaves distinct artifacts. The technology relies on generative adversarial networks (GANs), which pit two neural networks against each other until synthetic output becomes hard to distinguish from genuine footage, and increasingly on diffusion models that iteratively refine visual output to photorealistic quality.
Deepfakes differ from cheapfakes, which are manipulated videos produced through basic editing such as speed adjustment, splicing, or selective cropping. Deepfakes require AI model training on a specific individual's image and voice data, which is what makes them both more convincing and more dangerous.
How Generative AI Turns Public Data Into a Synthetic Identity
The creation pipeline starts with data collection. A few minutes of public footage, a LinkedIn profile video, an earnings call recording, or a keynote provides enough training material for face-swap encoders to map a target's facial geometry and voice patterns onto a synthetic actor. Voice-cloning tools replicate a speaker from seconds of audio, avatar tools generate full-body video from a single uploaded image, and text-to-video models such as OpenAI's Sora 2 and Google's Veo 3 produce temporally coherent, photorealistic video from a prompt alone. The barrier to entry has dropped from a funded production studio to a free-tier subscription. According to iProov's Threat Intelligence Report 2024, face-swap deepfakes alone increased 704% over the prior year as these tools proliferated.
Why the Scale of Deepfake Fraud Demands Attention
The attack surface created by these tools is no longer theoretical. According to Entrust's 2025 Identity Fraud Report, deepfake attempts occurred once every five minutes in 2024, and digital document forgery surpassed physical counterfeits as the leading fraud method for the first time. That volume is why learning how to spot a deepfake AI video has become a core competency for security teams rather than a niche forensic skill. The visual and behavioral artifacts that expose synthetic video are detectable, but only by employees trained to recognize them before a fraudulent call reaches an approval step.
New deepfake attempts arrive faster than any annual training cycle can answer. Adaptive Security delivers continuous deepfake and phishing simulation scenarios that keep recognition skills current as generation tools advance.
Visual Deepfake AI Video Detection Signs in the Face Itself

Knowing how to detect deepfake AI videos starts with the face. Generative adversarial networks and diffusion models reconstruct faces pixel by pixel, and that reconstruction leaves consistent physical artifacts that trained observers can spot in real time. The seven categories below cover the visual deepfake AI video detection signs worth checking on any suspicious clip. Each one is rooted in a specific limitation of how synthetic faces are rendered.
1. Unnatural Blinking and Eye Movement
Deepfake models are predominantly trained on still images scraped from the web, which contain no temporal blink data. Early GAN architectures produced faces that rarely blinked. Modern models have improved, yet blink timing still skews irregular, with blinks that happen too infrequently, too symmetrically, or cut short mid-close. Watch for eyelids that snap rather than roll, and pupils that track without the micro-saccades present in natural gaze.
2. Inconsistent Light Reflections in the Irises
Real eyes obey physics, so both irises reflect the same light sources with consistent shape and intensity. AI-generated faces frequently break this rule. Research from the University of Hull, presented at the 2024 Royal Astronomical Society National Astronomy Meeting, found that deepfake images show measurably inconsistent reflections between the left and right eye. Mismatched corneal highlights, meaning different shapes, positions, or brightness between both eyes, are reliable to identify deepfake AI video signals.
3. Lip-Sync Errors
Mouth movements are computationally expensive to render accurately against a continuous audio track. In lower-quality deepfakes, the lips visibly lag behind or anticipate spoken words, producing a dubbed-film effect. Look for moments where the jaw closes before a consonant resolves, or where mouth shape during vowels does not match the phoneme being spoken. Deepfakes exploit the authority of a known voice, so even a slight desync on a video call should prompt verification through a second trusted channel.
4. Abnormal Facial Expressions and Skin Texture
AI models average thousands of training frames, producing skin that appears uniformly smooth and slightly waxy. Pores, fine lines, and natural asymmetry are flattened out. Micro-expressions, the involuntary sub-second emotional flickers that precede full expressions, are absent or delayed. The jawline and hairline are the highest-error zones, so look for edges that soften, shift, or shimmer as the head moves.
5. Lighting and Shadow Inconsistencies
A real face in a real environment casts shadows that match the ambient light source. Deepfakes composite a synthetic face onto a background, and the two lighting models rarely align. Watch for faces that appear brighter than their surroundings, shadows that fall in different directions on the face versus the background, or specular highlights on the forehead that do not match the room's apparent light position.
6. Blurred or Warped Edges
GAN architectures struggle at the boundary between synthesized face and real background. Hair strands, ear edges, and collar lines frequently show a soft halo or warping artifact, especially during lateral head turns. These edge failures become most visible in motion. A static frame may look clean, while a half-second head rotation often reveals the face briefly separating from the background.
7. Distorted Background Detail and Garbled On-Screen Text
AI video generators render the focal subject first and deprioritize peripheral detail. Text visible in the background, on whiteboards, screens, or signage, frequently appears blurred, looping, or semantically nonsensical. Environmental objects near the frame edges may distort or morph between frames. If something readable in the background cannot be read clearly, treat it as a flag.
Video resolution and clip length add a final layer of context. Early AI generators capped convincing output below 1080p and struggled to maintain coherence beyond 30 seconds. That ceiling is shrinking, since models such as Sora 2 and Veo 3 now produce high-resolution, multi-minute outputs. Unusually low resolution combined with a short clip duration still warrants additional scrutiny.
Artifact spotting alone fails the moment a cyberattacker upgrades to a newer generation model. Adaptive Security builds detection instinct through repeated deepfake video exposure rather than a checklist that expires with each release.
Audio Cues That Reveal an AI-Generated or Deepfaked Video
Learning how to detect deepfake AI videos often starts with the ears rather than the eyes. AI-synthesized voices carry consistent tells rooted in how language models generate audio, including flat emotional tone, unnatural pacing, and abrupt tonal shifts that human speakers never produce. Audio-visual mismatch, where voice and lip movement fall out of sync, remains one of the most reliable combined deepfake AI video detection signs even as each channel improves independently.

1. Listen for Unnatural Prosody and Emotional Flatness
Human speech carries rhythm, stress, and emotional color that shift constantly with context. AI-generated voice applies prosody algorithmically, producing speech that sounds grammatically correct but emotionally hollow, with stress patterns that do not match the weight of what is being said. In a deepfake vishing call impersonating an executive, urgency or authority often sounds recited rather than felt.
2. Identify Robotic Cadence, Pauses, and Pitch Breaks
AI voice models generate audio by predicting sequences of phonemes. When the model transitions between training data segments, the voice stitches together inconsistently, producing micro-pauses of 100 to 200 milliseconds, sudden pitch shifts, or timbre changes that create an audible seam. These breaks are most pronounced mid-sentence, where a model pulls from one audio cluster and then another. The danger is compounded by how little source audio a cyberattacker needs, since a single earnings-call clip can supply enough material to weaponize an executive's voice.
3. Check Whether Background Audio Matches the Setting
A deepfake video set in a boardroom should carry ambient audio consistent with that environment, such as mild room tone, HVAC hum, and slight reverb. If the background audio sounds like a recording booth, a call-center floor, or an entirely different acoustic space than the visual setting, the audio track was likely generated or sourced separately and layered in. This mismatch is a reliable indicator that the video was assembled rather than recorded.
4. Treat Audio Alone as an Unreliable Signal
The most dangerous aspect of AI voice cloning is how effectively it defeats human perception. According to ScienceDirect's Computers in Human Behavior Reports 2024 meta-analysis of 56 studies and 86,155 participants, overall human deepfake detection accuracy averaged 55.54% across modalities, barely above chance. No matter how convincing a voice sounds, any high-value request delivered by phone or video should trigger second-channel verification before action.
Audio-visual synchronization failures, where voice audio leads or lags lip movement by a fraction of a second, remain the most consistent combined detection signal. Individual audio channels are improving faster than the underlying sync technology, which makes temporal mismatch the tell that outlasts the others.
Cloned voices carrying manufactured urgency are engineered to override caution in seconds. Adaptive Security rehearses employees through deepfake voice scenarios so a second-channel check becomes reflex rather than afterthought.
Behavioral Deepfake AI Video Red Flags During a Live Call
Detecting a deepfake AI video in real time means exploiting the computational boundaries of live rendering engines. Every challenge issued forces the model to process geometry it was not trained to handle cleanly, which surfaces the clearest deepfake AI video red flags available without software. None of the five techniques below require special tools, making them executable by any employee on any conferencing platform. Apply at least one challenge before approving any financial or access request received over video.
According to Gartner's CISO role-based survey 2026, 41% of organizations encountered a deepfake combined with social engineering on an audio call, confirming that live-channel verification is no longer optional.
1. Ask the Person to Turn Their Head Slowly Side to Side
Standard face-swap models are trained on frontal geometry. When a subject rotates past roughly 45 degrees, live deepfake tools typically produce edge blurring, texture smearing, or a warping artifact around the jaw and ear line. Ask the caller to turn slowly and watch the hairline and neck boundary, since those regions destabilize first. A clean rotation is a positive signal, while a smeared or flickering edge is grounds for termination and re-verification.
2. Ask Them to Wave a Hand Across Their Face

Hand occlusion is one of the most reliable stress tests for live deepfake detection. Most real-time face-swap tools cannot maintain facial coherence when a foreground object crosses the face plane. The model must reconstruct the obscured region frame by frame, producing visible distortion or a freeze-recover artifact at normal video resolution. Ask the caller to wave a hand slowly in front of their face and observe skin-tone continuity and the facial boundary during and immediately after the occlusion.
3. Ask Them to Share Their Screen
A deepfake operator running a virtual-camera pipeline routes the synthesized feed through software into a conferencing app, and that operator cannot simultaneously share a real desktop without exposing the toolchain in use. Operators tend to refuse the request, claim a technical issue, or share a pre-captured static screen. Any hesitation or refusal on a high-stakes call is a hard stop, so end the call and re-initiate contact through a verified, out-of-band channel.
4. Use a Pre-Agreed Codeword or Personal Secret Question
Technology-based checks fail if the cyberattacker has time to prepare countermeasures. A pre-agreed codeword, known only to the real person and a small trusted group, cannot be spoofed by any AI system operating on public data. Kaspersky's deepfake protection guidance recommends establishing a family or team codeword for exactly this scenario, where a synthetic caller cannot possess private shared knowledge. Finance teams and executive assistants should establish rotating codewords for any wire transfer or credential-sharing request made over video.
5. Change the Call Platform Mid-Call
Instruct the caller to rejoin through a new video link sent from a verified mobile number on a separate channel, whether SMS or a direct phone call. A legitimate colleague can do this in under two minutes. A deepfake operator running a prepared virtual-camera session on a specific platform faces a setup reset that takes far longer and risks breaking the synthetic feed. The friction is asymmetric, meaning trivial for real people and operationally disruptive for cyberattackers.
The cost of skipping these steps is concrete. In 2024, a finance employee at Arup approved a $25 million wire transfer after attending a deepfake video call where no behavioral challenge was issued, and every participant on that call was synthetic. A parallel 2019 case saw a UK energy firm authorize roughly €220,000 in fraudulent transfers after a cloned-voice call from a synthetic company director, again with no identity challenge made. These techniques matter most for finance and executive teams who routinely receive video-based approval requests, where a single unchallenged call can move millions in minutes.
One unchallenged video call moved $25 million out of a global engineering firm in a single afternoon. Adaptive Security drills finance and executive teams on live-call verification challenges before a synthetic caller ever dials in.
Deepfake Detection Tools and Software Available in 2026
Knowing how to detect deepfake AI videos requires accepting that no single tool provides a reliable, universal answer. Passive detection tools analyze artifacts already embedded in existing video, while active authentication methods embed provenance signals at the moment of content creation. The U.S. Department of Homeland Security's 2025 report on adversarial generative AI frames these as fundamentally different problem-solving approaches. Passive tools are reactive by design, while active methods shift verification upstream, before a video ever reaches a target. Most enterprise deployments need both layers, because neither works reliably in isolation.
What Passive Detection Tools Actually Do
Passive tools scan video after creation, looking for generative artifacts the human eye misses. Deepware Scanner offers free consumer-facing upload analysis, which suits individual spot-checks but not real-time organizational workflows. Sensity AI operates as an enterprise platform with multi-modal detection across video, voice, and image, while Hive Moderation provides API-based media classification that development teams integrate directly into content pipelines. Intel's FakeCatcher takes a physiological approach, detecting blood-flow patterns through remote photoplethysmography signals that synthetic faces cannot replicate. The University at Buffalo's DeepFake-o-meter runs submitted clips through multiple detection algorithms at once, giving comparative accuracy scores rather than a single verdict.
The Accuracy Problem Passive Tools Cannot Escape
AI-based detectors typically achieve 70 to 80% accuracy under controlled test conditions, yet performance degrades sharply against newer generative models and standard post-processing pipelines. A deepfake run through a basic compression workflow, the kind of step a cyberattacker takes routinely, produces enough encoding noise to suppress the artifacts passive models look for. The vulnerability is structural, since passive detectors are trained on yesterday's generation methods and each new model release requires retraining to hold any meaningful accuracy.
Active Authentication Through Provenance Over Artifact Analysis
Active authentication sidesteps artifact hunting by asking whether content was certified at the point of creation. Google's SynthID creates a provenance signal using embedded patterns that persist through standard compression and re-encoding. Because the signal is structural rather than perceptual, it survives the post-processing that defeats passive detectors. Its limitation is equally structural, since it only works on content Google's own models generate, leaving the majority of adversarially produced deepfakes outside its scope. Blockchain-based provenance frameworks aim to extend the active model to any content creator, though adoption across video production pipelines remains early.
Choosing the Right Approach for Enterprise Defense
Passive tools remain the only option for verifying content that arrives without provenance metadata, which describes the overwhelming majority of deepfake cyberattacks organizations face today. Adaptive Security's phishing simulation platform addresses this gap from a different angle, exposing employees to realistic deepfake video scenarios in a controlled environment so detection skill is built through practice rather than through software accuracy rates that degrade with each generation of generative AI. Software flags high-probability fakes, and trained employees verify anything that reaches them through high-risk channels.
Detection software degrades the moment a new generative model ships, leaving a gap only people can close. Adaptive Security pairs tooling awareness with hands-on deepfake practice so the final human judgment call holds.
How Watermarks, Metadata, and Blockchain Authenticate Real Video
Active authentication methods supporting how to detect deepfake AI videos verify what a piece of content is rather than analyzing what it looks like. Unlike passive detection tools that scan for compression artifacts or blinking anomalies, active authentication embeds verifiable provenance data at the point of creation, building a chain of custody from camera to viewer. These methods are more reliable in principle than visual analysis, yet their effectiveness depends entirely on whether the original creator chose to implement them.
What Digital Watermarks Are and How They Work
Digital watermarks are imperceptible signals embedded directly into video pixels at the moment of creation. Google DeepMind's SynthID embeds patterns into individual pixels of AI-generated content that survive standard editing and compression, remaining detectable even after the video is re-exported or reformatted. Because the signal is invisible to the human eye and statistically woven into the pixel structure rather than stored as a separate file, stripping it without visible degradation is extremely difficult.
How Metadata Provenance Exposes Manipulated Video
Every video file carries metadata such as EXIF data, creation timestamps, GPS coordinates, and device identifiers, which document where and when it was captured and on what hardware. Investigators verify this metadata against the claimed source, so a video purportedly filmed on a phone at a specific location should carry device and location signatures consistent with that claim. Absent or stripped metadata is itself a red flag, since authentic footage rarely has no provenance record. A file with no EXIF data, an implausible timestamp, or a device ID that does not match the claimed camera demands immediate scrutiny.
How Blockchain Provenance Creates a Tamper-Evident Trail
The Coalition for Content Provenance and Authenticity (C2PA), an open technical standard led by companies including Adobe, BBC, Google, Intel, and Microsoft, uses cryptographic hashing to record every edit made to a piece of content on a distributed ledger. Each modification generates a new hash entry tied to the previous one, creating an audit trail that cannot be altered without breaking the chain. Reuters has piloted C2PA-compatible workflows to authenticate photojournalism and video. If any frame is swapped, a face composited in, or audio replaced, the hash mismatch immediately signals tampering.
What Forensic Frame-by-Frame Analysis Adds
Forensic analysts use error level analysis to identify regions of a frame that were edited or re-compressed at different quality levels. When a face is composited into a background, the spliced region retains a different compression signature than the surrounding pixels, and error level analysis surfaces that contrast as visible brightness differences. Luminance gradient analysis maps the rate of light and color change at boundaries between face and background. Deepfake composites frequently show unnaturally sharp or unnaturally smooth transitions at the hairline and jaw edge compared to genuine footage, where lighting naturally blurs those boundaries.
The Core Limitation of Authentication Methods
Authentication infrastructure only works when the original creator embedded provenance data at the point of capture, and most platforms, devices, and individuals have not implemented these standards. The 2024 GAO Science and Tech Spotlight on combating deepfakes identifies authentication infrastructure as the longer-term structural solution, while detection tools remain a partial countermeasure in the interim. That gap means training people to recognize the visual and behavioral signs of manipulation is the only defense that scales across every device, channel, and employee who could be targeted today.
Provenance standards only protect content that was certified at capture, which excludes nearly every deepfake an enterprise will face. Adaptive Security closes that exposure by training the human verification layer that works regardless of metadata.
Why Deepfakes Are Getting Harder to Detect Over Time
Learning how to detect deepfake AI videos is increasingly like aiming at a moving target. Deepfake generation models are now explicitly trained against detection systems in an adversarial feedback loop, so each improvement in detection methods directly accelerates the sophistication of generation models. The U.S. Department of Homeland Security's 2025 report on adversarial generative AI documents this dynamic. The gap is structural rather than temporary, and it compounds with every training cycle.
How Deepfake Generation Outpaced Detection
The first generation of deepfakes relied on generative adversarial networks, which left predictable frequency-domain artifacts that trained classifiers could detect. Diffusion-based synthesis models, now used by tools such as Sora 2 and Veo 3, sidestep those artifacts by generating video through iterative noise reduction rather than adversarial competition, producing outputs that pass human visual inspection. Post-processing compounds the problem, since running synthetic video through standard compression codecs strips many of the artifact signatures detection tools depend on. According to arXiv's Deepfake-Eval-2024 Benchmark 2025, open-source detector accuracy fell by 50% on video and 48% on audio when measured against real-world deepfakes circulating in 2024.
Why Humans Cannot Fill the Gap
Human judgment is not a reliable fallback. According to iProov's Threat Intelligence Report 2024, only 0.1% of participants correctly identified every real and fake item in a comprehensive test, and participants were 36% less likely to correctly identify a synthetic video than a synthetic image. Artifact-spotting skill erodes in direct proportion to model quality, which gives any purely visual detection strategy a built-in expiration date.
What This Means for Organizational Defense
Organizations cannot train employees to win an artifact-detection race they are structurally guaranteed to lose. The durable defense lies in behavioral cues and procedural controls, meaning recognition of when pressure, urgency, and authority are being weaponized, followed by verification protocols applied regardless of how convincing the source appears. Adaptive Security's phishing simulation scenarios include deepfake video cases that train employees to respond to the psychological mechanics of a cyberattack rather than its visual flaws. That behavioral foundation holds even as generation quality advances.
The detection race favors the cyberattacker by design, and visual artifact training expires with every model release. Adaptive Security grounds defense in behavioral verification habits that survive each new generation of synthetic media.
How to Respond After Encountering a Suspected Deepfake
A correct response to a suspected deepfake depends on whether the content is live or recorded, and applying how to detect deepfake AI videos under pressure means having a protocol ready before the moment arrives. The core principle is identical in both cases: stop, verify through a separate channel, and authorize no action until identity is confirmed. For live calls, pause or exit using a neutral pretext, then contact the apparent caller through a known, pre-saved number. For recorded or distributed video, use detection tools and cross-reference against credible sources before sharing or acting.

1. Exit the Live Call and Verify Through a Separate Channel
The Arup case remains the clearest illustration of what happens without this protocol. Any warning sign should end the call. Unusual urgency, an unexpected financial request, or slight audio and visual artifacts are each sufficient reason to exit under a neutral excuse such as a connection problem, then contact the apparent sender directly on a known, saved number.
2. Analyze Recorded or Distributed Video Before Acting
For suspicious pre-recorded video, run a reverse image or video search through tools such as Google Lens or TinEye to locate the original source and determine whether it was manipulated. Browser extensions that break video into frames and surface metadata help expose details deepfake tools cannot replicate convincingly. Cross-reference every factual claim in the video against at least two credible sources before drawing a conclusion or sharing the content further.
3. Report the Incident and Preserve Evidence
Report suspected deepfake fraud to the FBI Internet Crime Complaint Center and notify the platform where the content appeared. Document everything first, since platforms often remove content quickly and evidence disappears with it. Screenshots, metadata, URLs, and timestamps must be preserved before requesting takedown. Notify the impersonated individual or organization directly so they can alert their own networks.
4. Build Organizational Defenses Before the Next Attempt
Organizations cannot rely on individual judgment alone when cyberattackers invest in multi-channel, high-production deepfake scenarios. Finance and executive teams need pre-agreed verification codewords, meaning a shared phrase confirmed through a separate trusted channel that authorizes any wire transfer or credential handoff regardless of how convincing the video or voice appears. Including deepfake scenarios in cybersecurity awareness training gives employees a rehearsed response protocol so recognition of the cyberattack pattern becomes automatic before a real attempt arrives.
A reporting policy in a binder does nothing the moment a synthetic CFO appears on a live call. Adaptive Security converts response protocols into trained reflex through repeated deepfake scenario practice across every channel.
Why Deepfake Detection Belongs Inside Cybersecurity Awareness Training
Deepfakes have moved from a media curiosity to an active delivery mechanism for business email compromise, executive impersonation fraud, and wire transfer scams, and most existing programs are not built to address them. According to Verizon's Data Breach Investigations Report 2026, 62% of confirmed incidents involve a human element, and deepfakes amplify that exposure by adding visual and auditory authenticity to cyberattacks that email filters cannot touch. Embedding how to detect deepfake AI videos inside a structured cybersecurity awareness training program turns an awareness gap into a trained, repeatable response.
How Deepfake Detection Connects to Phishing Awareness

Teaching employees to recognize deepfake audio and video cues follows the same behavioral logic as phishing awareness work. Both disciplines aim to interrupt a social engineering cyberattack before a wire transfer is approved, credentials are surrendered, or confidential data is disclosed. According to Verizon's 2026 Data Breach Investigations Report, stolen credentials were involved in 13% of all breaches, the kind of access a single convincing impersonation can hand over. The detection skill transfers directly across channels, and the underlying training framework is identical.
Why Email-Only Programs Leave Teams Exposed
A cybersecurity awareness training program built around email phishing simulation alone trains employees for one channel while leaving voice, video, and SMS uncovered. According to Verizon's Data Breach Investigations Report 2026, mobile-centric social engineering such as voice phishing and SMS scams now succeeds at a rate 40% higher than traditional email phishing, confirming that multi-channel cyberattack capability is scaling faster than single-channel programs can respond. A finance employee who aces every email phishing test still has no rehearsed response to a deepfake executive video call.
Where Compliance Frameworks Position Deepfake Awareness
NIST CSF and CMMC increasingly treat human risk as a formal control domain rather than a supplementary activity. Deepfake awareness maps directly into those frameworks under security awareness and training controls, the same controls that govern phishing education. Organizations building cybersecurity awareness training that includes multi-channel simulation across email, voice, and deepfake video satisfy this control domain more completely than those relying on annual click-through modules. According to Gartner's Deepfake Social Engineering Survey 2025, 62% of organizations experienced a deepfake attack in the prior 12 months, underscoring why single-channel coverage no longer matches the threat profile.
Email-only programs certify employees for a fraction of the channels cyberattackers now use against them. Adaptive Security delivers multi-channel deepfake and phishing simulation that maps cleanly to NIST CSF and CMMC human-risk controls.
See How Adaptive Security Trains Employees to Recognize and Respond to Deepfake Attacks

Deepfake-enabled fraud is accelerating faster than unaided human perception can adapt, and a policy document is not a training program. Mastering how to detect deepfake AI videos at an organizational scale requires repeated exposure to realistic scenarios rather than a one-time briefing, because the cues that matter shift with every new generative model.
When employees move through realistic deepfake scenarios inside Adaptive Security's cybersecurity awareness training, they build the verification instincts and second-channel habits that hold under pressure. Finance teams rehearse live-call challenges, executives practice codeword confirmation, and every role learns to treat manufactured urgency as the signal to slow down rather than comply.
That practice is what separates a contained incident from a seven-figure loss, and it is the layer software cannot supply on its own. Adaptive Security positions deepfake readiness as an outcome of trained behavior across email, voice, and video rather than a feature dependent on detection accuracy that erodes with each release.
Deepfake fraud is outpacing the instincts employees were never trained to build. Adaptive Security closes that gap with hands-on deepfake scenarios that show exactly where an organization's human risk exposure sits.
Frequently Asked Questions About Deepfake AI Video Detection
Can Ordinary People Learn How to Detect Deepfake AI Videos Without Specialized Tools?
People can catch some deepfakes using visual and behavioral cues, though reliability is inconsistent and shrinking as generation technology improves. According to Nature Communications' Human Detection of Political Speech Deepfakes 2024, audio produced by state-of-the-art text-to-speech proves measurably harder to discern than the same deepfake voiced by a human actor. Practical deepfake AI video detection signs that remain accessible without tools include unnatural blinking, blurred edges at the hairline, lip-sync mismatches, and audio that does not match the visual setting. Structured practice sharpens those instincts in a way unaided intuition does not.
How Can a Deepfake AI Video Be Spotted During a Live Call?
Spotting a deepfake on a live call requires real-time behavioral tests that exploit the computational limits of face-swap rendering. Asking the person to turn their head slowly side to side helps, since most live tools blur or warp at extreme angles. A hand waved in front of the face distorts the majority of real-time pipelines, and a screen-share request is one a virtual-camera operator typically cannot or will not provide. A pre-agreed codeword or a personal question only the real person could answer adds a final layer, a method Kaspersky specifically recommends for this scenario.
What Is the Most Reliable Sign That a Video Is a Deepfake?
No single artifact is fully reliable, yet audio-visual mismatch, where voice and lip movement fall out of temporal alignment, remains one of the most consistent combined deepfake AI video red flags across generation methods. Visual tells such as blurred or warped edges at the face-hair boundary, irregular blinking, and overly smooth waxy skin from AI frame-averaging are strong indicators in lower-quality deepfakes. The critical limitation is that as generation models improve, individual artifact cues erode faster than human perception adapts, which is why behavioral verification during live interaction is the more durable method for high-stakes scenarios.
How Accurate Are Deepfake Detection Tools, and Can They Be Fooled?
Detection tools typically reach 70 to 80% accuracy in controlled benchmark conditions, and that performance degrades sharply against newer generative models or post-processed video. Tools can be circumvented by running a deepfake through a standard compression pipeline, which strips the artifact signatures detectors rely on. According to the U.S. Government Accountability Office's Science and Tech Spotlight on Deepfakes 2024, detection models trained on known generation methods are consistently outpaced when new architectures emerge, which positions detection tools as a useful first filter rather than a definitive verdict.
Are Deepfakes Illegal, and What Should Be Done If One Is Found?
Whether a deepfake is illegal depends on its content and intent. In the United States, no single federal law covers all deepfakes, though numerous state laws and federal statutes address specific harms, including the TAKE IT DOWN Act of 2025 for nonconsensual intimate imagery and existing fraud statutes for impersonation and wire fraud. If a suspected deepfake appears, preserve the content with screenshots and metadata before it can be removed, report fraud-related cases to the FBI Internet Crime Complaint Center, notify the impersonated party through a verified channel, and report the content to the hosting platform. For organizations, knowing the response protocol in advance is the difference between a contained incident and a seven-figure wire transfer.
Key Takeaways
- How to detect deepfake AI videos now sits among the core competencies for any finance or executive function, because synthetic media has become a primary delivery mechanism for impersonation and wire fraud.
- The strongest visual deepfake AI video detection signs include irregular blinking, mismatched iris reflections, lip-sync errors, waxy skin texture, lighting inconsistencies, warped edges, and garbled background text.
- Audio cues that help identify deepfake AI videos include flat emotional prosody, robotic cadence with audible seams, mismatched background acoustics, and audio-visual sync failure as the most durable combined tell.
- Behavioral challenges deliver the clearest live deepfake AI video red flags, including head turns, hand occlusion, screen-share requests, pre-agreed codewords, and mid-call platform changes.
- The reliable way to spot a deepfake AI video over time is procedural, since detection tools and visual artifact skills both degrade as generation models advance, while behavioral verification habits hold.
- A multi-channel cybersecurity awareness training program that covers email, voice, and deepfake video maps directly to NIST CSF and CMMC human-risk controls and closes gaps that email-only coverage leaves open.
Trained employees stop the payment approvals that synthetic executives are already clearing elsewhere. Adaptive Security turns deepfake recognition and verification into rehearsed reflex through realistic, multi-channel cybersecurity awareness training.
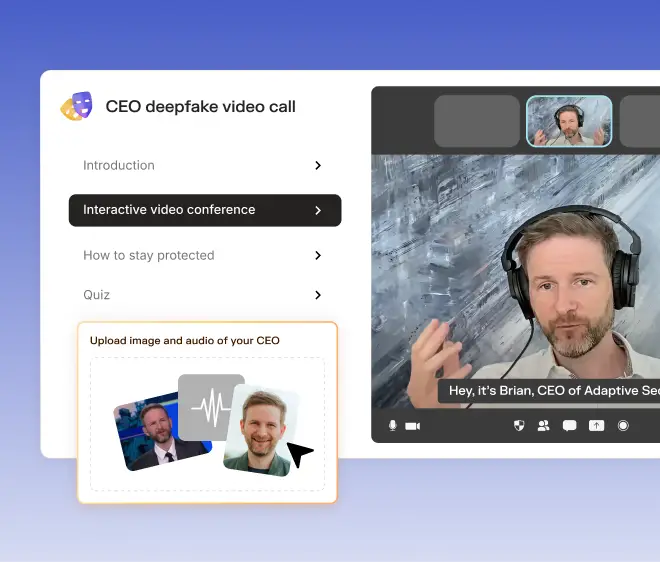

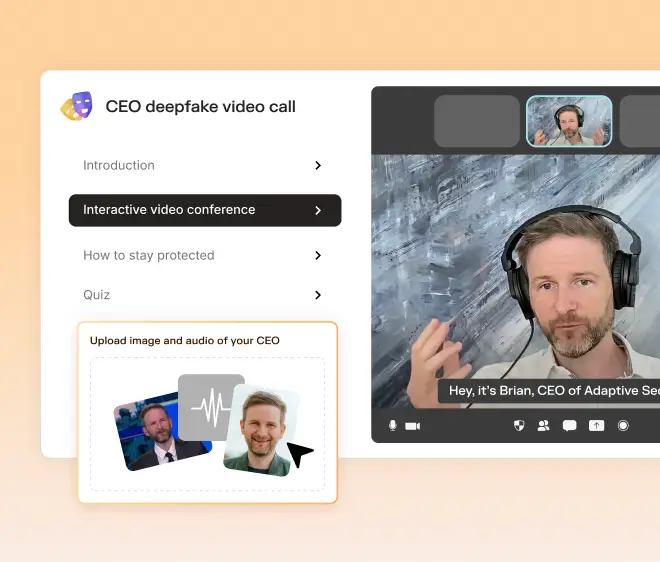
As experts in cybersecurity insights and AI threat analysis, the Adaptive Security Team is sharing its expertise with organizations.
Contents