How deepfake detection tools work in practice differs sharply from how they perform in controlled benchmarks. That gap carries costly consequences for security leaders who depend on detection technology to stop AI-generated fraud, disinformation, and impersonation.
This article examines the AI architectures powering modern detection, from convolutional neural networks and vision transformers to multimodal fusion systems that combine visual, audio, and metadata analysis.
It covers the visual artifacts and biological signals detectors analyze, the acoustic features that reveal synthetic voices, and the digital forensics and open-source intelligence (OSINT) methods that complement automated detection.
Explore how Adaptive Security's deepfake security awareness training prepares employees to identify and verify synthetic media before a live cyberattack reaches the decision point.
What Are Deepfakes and How AI Creates Them
A deepfake is synthetic media, audio, video, or imagery, in which artificial intelligence replaces or manipulates a person's face, voice, or body to produce fabricated content nearly indistinguishable from authentic recordings.
The term was coined in late 2017 by a Reddit user of the same name who shared AI-generated face-swap imagery, and it has since expanded to encompass a broad toolkit of generative techniques now deployed in fraud, political disinformation, and enterprise-targeted social engineering.
Unlike cheapfakes, low-effort manipulations such as slowed footage or mislabeled context, and traditional CGI requiring expensive studios and manual artistry, deepfakes are algorithmically generated at scale by neural networks trained on publicly available data, making them cheap to produce, rapidly improvable, and uniquely difficult for both humans and automated systems to detect.

How Generative Adversarial Networks (GANs) Create Deepfakes
Generative adversarial networks operate through a competitive architecture: two neural networks, a generator and a discriminator, are trained against each other in an escalating loop.
The generator produces synthetic images or audio from random noise, while the discriminator attempts to distinguish those outputs from real samples. Each time the discriminator catches a fake, the generator adjusts its parameters and tries again.
Over thousands or millions of iterations, the generator learns to produce outputs the discriminator can no longer reliably separate from authentic data. This adversarial dynamic is what gives GANs their ability to generate faces that never existed, swap identities seamlessly, and synthesize voiceprints with uncanny fidelity.
How Autoencoders and VAEs Reconstruct Faces
Autoencoders and variational autoencoders (VAEs) take a different approach: rather than competing, they compress and reconstruct. An encoder network squeezes an input image, such as a frame of a person's face, into a low-dimensional latent representation that captures essential features like eye position, jaw shape, and lighting conditions. A decoder network then rebuilds the image from that compressed representation.
The power of this architecture lies in decoder swapping: train one encoder on a wide diversity of faces, then pair it with a decoder trained exclusively on a specific target face. Any input face gets reconstructed with the target's facial features, enabling face-swap deepfakes without requiring paired training data. This encoder-decoder architecture underpins early deepfake tools like DeepFaceLab and remains foundational to modern face replacement pipelines.
Face-Swap Deepfakes
Face-swap deepfakes are the most common and historically the first type to gain public attention. Tools like FaceSwap and DeepFaceLab use autoencoder-based pipelines to map one person's facial expressions, head movements, and lighting onto another person's face, creating videos where the subject appears to be someone else entirely.
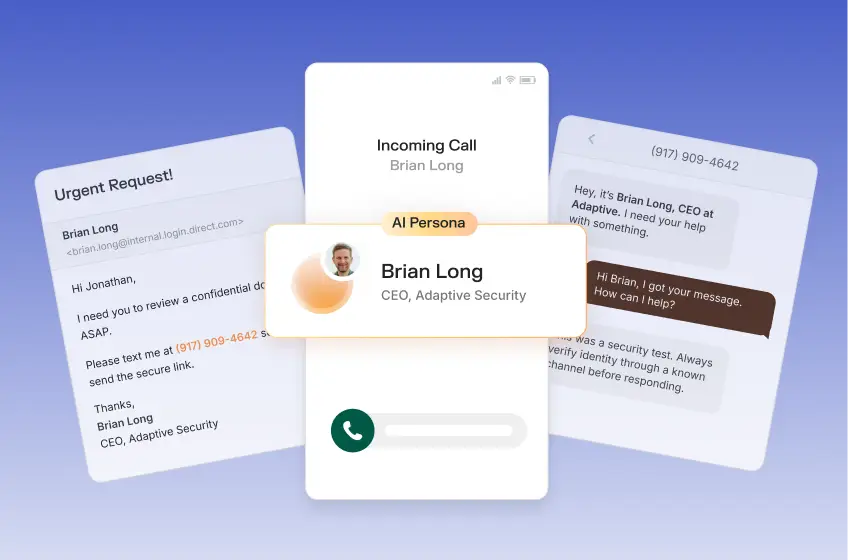
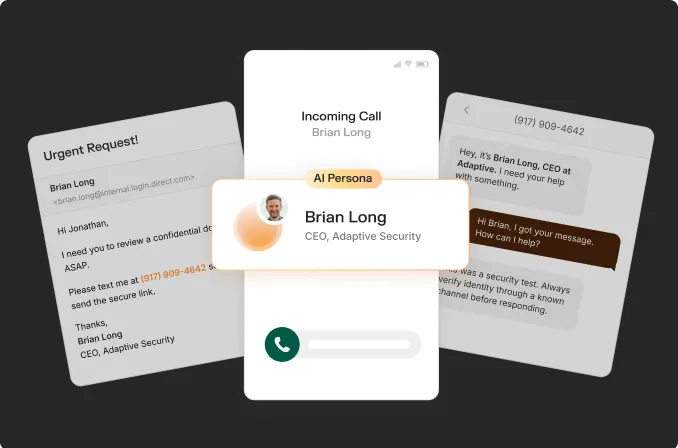
The process requires hundreds to thousands of source images of the target face, which cyberattackers routinely harvest from social media, conference recordings, and corporate websites through open-source intelligence (OSINT) gathering.
"One should think of everything one puts out on the internet freely as potential training data for somebody to do something with," said Halsey Burgund, a fellow in the MIT Open Documentary Lab. In a corporate context, a finance employee might see a CFO on a video call approving an urgent wire transfer, when every participant on that call was a synthetic fabrication.
Organizations counter this exposure by running deepfake phishing simulations that let employees experience these cyberattacks in a controlled environment before facing one in the wild.
Lip-Sync Deepfakes
Lip-sync deepfakes modify only the mouth and jaw region of a video, aligning lip movements to a new audio track while leaving the rest of the face and background untouched.
The most prominent implementation, Wav2Lip, uses a pretrained lip-sync discriminator that forces generated mouth shapes to match the phonemes of an input audio clip with pixel-level precision.
This technique is especially dangerous in enterprise settings because it weaponizes genuine video footage, a real earnings call or internal town hall, by overlaying fabricated audio that puts words in an executive's mouth.
Because the background, lighting, and majority of the face remain authentic, these forgeries bypass many of the visual detection instincts that security awareness training teaches employees to recognize. The gap between authentic and synthetic becomes nearly invisible to the untrained eye.
Voice Cloning Deepfakes
Voice cloning uses neural networks trained on as little as three seconds of audio to generate synthetic speech that replicates a person's tone, cadence, accent, and emotional inflection.
Models like ElevenLabs convert text into cloned speech that can say anything the cyberattacker types, enabling real-time vishing cyberattacks where a criminal calls an employee sounding exactly like a CEO demanding an urgent funds transfer.
Full-Body Reenactment and Puppeteering
Full-body reenactment, also called puppeteering, maps a source person's entire body movements, gestures, and posture onto a target body in real time.
Unlike face-only swaps, this technique transfers head position, arm movements, torso orientation, and even gait, creating the illusion that the target person is physically present and performing the actions themselves.
The technology draws on pose estimation models that detect skeletal keypoints in a source video and motion transfer networks that warp the target body to match.
While computationally heavier than face-swap or lip-sync techniques, advances in model efficiency are rapidly lowering the barrier. When an employee sees a manager's entire physical presence on screen, skepticism collapses almost entirely, and that collapse is what opens the door to losses no email filter can stop.
The AI and Machine Learning Engine Behind Deepfake Detection
Understanding how deepfake detection tools work at the architectural level requires examining the machine learning models trained on massive datasets containing both authentic and manipulated media.
These models learn distinguishing features that human eyes consistently miss. A 2026 cross-dataset evaluation across CNN and Transformer architectures published in Machine Vision and Applications confirmed that spatiotemporal Transformers like TimeSformer achieved 78.4% accuracy and 0.801 AUC on unseen manipulation types, far outperforming CNN-only baselines that plateaued near 65%.
The detection gap between architectures widens most dramatically when models encounter deepfake generation techniques they were never trained on, which is precisely the scenario security teams face in production.
How Convolutional Neural Networks Detect Spatial Artifacts in Individual Frames
Convolutional Neural Networks (CNNs) remain the workhorse for identifying spatial artifacts within individual frames. They process images through successive layers of filters that detect increasingly complex patterns: edges in early layers, textures in middle layers, and semantically meaningful structures like facial features in deeper layers.
In deepfake detection, CNNs learn to spot inconsistent blending boundaries where a synthetic face meets the original background, asymmetrical facial features, unnatural skin texture smoothing, and pixel-level anomalies introduced during face-swapping.
Architectures like ResNet-50 and XceptionNet excel because their hierarchical design captures artifacts at multiple spatial scales. CNNs process each video frame independently, however, with no mechanism to flag the flickering inconsistencies, irregular blinking cadences, or unnatural eye movement patterns that emerge only across consecutive frames. That limitation is where recurrent architectures enter.
How RNNs and LSTMs Catch Temporal Inconsistencies Across Video Frames
Recurrent Neural Networks (RNNs) and Long Short-Term Memory networks (LSTMs) address the critical blind spot of frame-by-frame analysis: time. A deepfake video might look flawless in any single frame yet reveal itself through unnatural motion dynamics, a slight stutter in head movement, lips that fail to sync with audio, or eyes that drift mechanically rather than following natural saccade patterns.
The CNN-LSTM hybrid architecture has become a standard pattern. A CNN backbone extracts spatial features from each frame, and the LSTM layer models how those features change across the sequence, learning what authentic temporal transitions look like and flagging sequences that deviate.
Attention-based temporal models have further improved on this design, replacing recurrent processing with parallelizable attention mechanisms that handle high-resolution video at scale while matching or exceeding CNN-LSTM detection accuracy.
Why Vision Transformers and Video Transformers Outperform CNNs on Cross-Dataset Generalization
The most significant architectural leap in deepfake detection has been the shift from CNNs to transformer-based models. Unlike CNNs, which process images through local receptive fields that expand only gradually across layers, Vision Transformers (ViTs) divide each frame into patches and apply self-attention globally from the first layer.
The model connects a manipulation artifact near the jawline with an inconsistency in the hairline even when they are far apart spatially.
Video Transformers extend this capability into the temporal dimension. TimeSformer applies divided space-time attention, learning joint spatial and temporal representations that capture both what looks wrong and when motion patterns break natural continuity.
Transformer-based architectures consistently outperform CNNs on cross-dataset generalization, where models trained on one set of deepfake generation techniques must detect manipulations created by entirely different methods. This cross-dataset scenario is the one that matters in production, because cyberattackers do not use the same generators researchers train on.
How Ensemble Approaches Combine Multiple Architectures for Higher Accuracy
No single model architecture catches everything. CNNs excel at pixel-level blending artifacts, LSTMs detect unnatural motion cadences, and transformers capture long-range spatial-temporal dependencies. Ensemble approaches combine predictions from multiple model types, averaging confidence scores or using a meta-classifier trained on each detector's outputs, to produce a verdict consistently more accurate than any single model alone.
In practice, production-grade detection systems frequently run a CNN for frame-level artifact analysis, an LSTM for temporal coherence scoring, and a transformer for global consistency checks, then fuse the outputs into a single confidence score. The trade-off is computational cost: each additional model adds inference time, but the accuracy gains justify the overhead for high-stakes verification scenarios.
How Multimodal Detection Systems Fuse Audio, Visual, and Metadata Signals
The most sophisticated detection systems do not rely on video frames alone. Multimodal detection fuses visual signals with audio analysis, metadata examination, and sometimes physiological signals into a unified confidence score.
Three fusion strategies dominate. Early fusion concatenates raw features from each modality before feeding them into a single model, forcing the network to learn cross-modal relationships from the ground up.
Late fusion processes each modality through its own specialized detector and combines independent confidence scores at the decision stage. Hybrid fusion blends both approaches, allowing intermediate feature sharing while preserving modality-specific processing paths.
A video might pass visual inspection yet fail audio analysis because a voice clone's prosody patterns do not match the speaker's known baseline. By fusing signals that no single modality captures alone, multimodal systems close the detection gaps cyberattackers exploit.
Underpinning these architectural decisions is a growing demand for explainable AI. Detection tools cannot simply output a "fake" score and expect that to hold up in a forensic investigation, a courtroom, or a corporate incident review.
An INTERPOL report on synthetic media forensics emphasized that explainable AI is 'emerging as a crucial factor' in digital forensics applications. The report noted that AI detection tools must provide clear, accurate, and understandable explanations for their outputs, and that a lack of explainability may hinder admissibility in legal proceedings.
In practice, this means detection models must surface where and why they flagged content through mechanisms such as heatmaps, temporal segment analysis, and human-readable rationales that non-technical stakeholders can evaluate.
Without interpretability, even a highly accurate detector is a black box that cannot be trusted for consequential decisions. The same detection principles that power these forensic architectures also drive the deepfake phishing simulations used to train employees to recognize AI-manipulated media before a live cyberattack reaches their inbox.
Visual Detection Methods: Artifacts, Biological Signals, and Image Analysis
How deepfake detection tools work at the visual level involves analyzing video frame by frame for artifacts the human eye routinely overlooks, then cross-referencing those findings against biological signals that only a living person produces. Detection engines combine multiple visual analysis techniques to separate synthetic faces from real ones. No single artifact category catches every generation method used by modern deepfake engines, so effective detection requires layering these approaches.
1. Examine Facial Boundary Discontinuities
The seam where a synthetic face meets the original head is the most reliable starting point. Face-swapping algorithms must blend two distinct facial regions together, and the compositing process nearly always leaves detectable traces.
Detection tools scan for resolution mismatches, alpha blending artifacts along the jawline and hairline, and unnatural color transitions where the swapped face meets the original head. These boundaries often exhibit subtle flickering between frames where the blending algorithm struggles to maintain consistency.
Detection models trained on boundary anomalies look specifically for the rectangular or oval mask edges that face-swapping pipelines use to isolate the facial region, along with discrepancies in compression artifacts between the face and surrounding areas.
2. Analyze Blinking Pattern Anomalies
Generative adversarial networks (GANs) and early autoencoder-based deepfake models produce faces with irregular blinking, or no blinking at all. This happens because security awareness training datasets overwhelmingly contain photographs of people with eyes open.
A 2020 study published in IEEE Access by Jung, Kim, and Kim introduced DeepVision, a deepfake detector that analyzes eye blinking patterns, measuring blink frequency, period, and duration using the Eye Aspect Ratio, finding that deepfake videos exhibit significantly lower blink rates than real humans. The detector achieved 87.5% accuracy in initial testing.
The approach represents an early demonstration of biological signal exploitation in deepfake detection; modern generators have since advanced to replicate natural blink patterns more convincingly.
Detection algorithms now measure multiple eye-movement parameters simultaneously: blink rate per minute, completeness of eyelid closure, and gaze convergence. Real human eyes converge on a focal point when looking at a subject.
Deepfake eyes often exhibit divergent gaze, what Intel Labs senior staff research scientist Ilke Demir described as "googly eyes," because the generation model does not accurately simulate binocular vision geometry.
3. Check Lighting and Shadow Consistency
Deepfake compositing frequently fails physics-accurate illumination because the generative model has no true understanding of three-dimensional scene geometry.
Detection tools analyze whether light sources cast consistent shadows across the face and whether the direction, intensity, and color temperature of illumination on the facial region matches the rest of the frame.
A swapped face illuminated from the left while the neck and shoulders show shadowing from above presents a reliable forensic indicator at the computational level.
Specular highlights on the eyes, skin, and teeth provide particularly rich signals. Real corneas reflect light in ways that obey the scene's geometric constraints.
Synthetic faces often place catchlights in both eyes identically or omit them entirely, and deepfake renderers rarely model subsurface scattering accurately, producing faces that look subtly plastic under forensic analysis.
4. Identify Skin Texture Irregularities
Real human skin has pores, fine hair, micro-texture variations, and asymmetrical features distributed across facial regions. Deepfake generators tend to produce unnaturally smooth skin with a homogeneous texture that lacks these microscopic irregularities.
Detection tools apply frequency-domain analysis to identify regions where natural skin texture has been smoothed away by the generation process.
On a real face, the skin around the nose, forehead, and cheeks exhibits distinct textural signatures due to varying pore density, oil production, and sun exposure. Synthetic faces often apply uniform texture across all regions or introduce repeating texture patterns. Detection algorithms flag frames where texture variance falls below the statistical norms established by large datasets of authentic facial imagery.
5. Detect Facial Movement and Micro-Expression Absence
Human faces are never perfectly still. Even at rest, micro-expressions, fleeting involuntary muscle movements lasting a fraction of a second, ripple across facial features. Deepfake faces often exhibit unnatural rigidity between major expressions, as if the face freezes when not actively emoting.
The temporal dimension matters here: a single frame might look flawless, but across 60 frames per second, the absence of subtle nostril flares, lip micro-adjustments, and involuntary eye darts becomes statistically detectable.
Detection models trained on temporal sequences learn to recognize the characteristic stiffness signature of synthetic faces, where the transition between expressions follows interpolated paths rather than the complex, asymmetric muscle activation patterns of real facial anatomy.
6. Verify Biological Signals with Photoplethysmography (PPG)
The most advanced visual detection approach shifts from hunting artifacts to verifying authentic biological signals. Intel's FakeCatcher represents the leading commercial implementation of this strategy, using photoplethysmography (PPG) to detect subtle changes in facial skin color caused by blood flow. When the heart pumps, veins shift color in ways imperceptible to the naked eye but measurable at the pixel level across multiple video frames.
Intel's system collects blood flow signals from across the entire face, translates them into spatiotemporal maps, and uses deep learning to classify the video as real or fake in milliseconds. "We ask what is real about authentic videos? What is real about us? What is the watermark of being human?" said Ilke Demir, senior staff research scientist at Intel Labs.
FakeCatcher achieves a 96% accuracy rate in controlled testing and runs on 3rd Gen Intel Xeon Scalable processors capable of handling up to 72 simultaneous detection streams.
7. Account for Video Quality Factors That Degrade Detection
No visual detection method works reliably across all video conditions. Low resolution smooths away the high-frequency artifacts that pixel-level analysis depends on.
The BBC's independent testing of FakeCatcher confirmed that pixelated video makes blood flow signals far harder to isolate, causing the system to misclassify several genuine videos as fake.
Poor lighting obscures the PPG signal entirely, heavy compression strips the subtle temporal data that blink analysis and micro-expression tracking rely on, and complex backgrounds introduce visual noise that confuses classifiers.
Detection tools compensate by running multiple analysis pipelines in parallel and weighting each method's output according to the video's quality profile. Security teams should be aware that a grainy, poorly lit deepfake may evade detection even when higher-quality versions of the same manipulation would be caught.
What makes detection fundamentally asymmetric is that generators only need to fool one method, while detectors must catch every variation. That reality is driving the shift toward multimodal approaches that combine visual analysis with audio forensics and metadata inspection.
Audio Analysis and Voice Deepfake Detection
AI-generated voices now pass casual listening tests. The artifacts that separate synthetic speech from genuine human audio live in acoustic dimensions the human ear cannot access: prosodic rhythm, pitch contour, and spectral frequency distribution. Understanding how deepfake detection tools work against audio requires examining each of these dimensions in turn.
1. Examine Cadence, Prosody, and Pitch Contour for Synthetic Patterns
Human speech follows biological rhythms that AI models consistently fail to replicate. Detection engines analyze cadence and prosody: the natural rise and fall of speech, pause placement between phrases, and micro-variations in syllable duration that signal genuine cognition.
Synthetic voices produce unnaturally uniform rhythm patterns. They either avoid pauses entirely or insert them at mathematically regular intervals, rather than at linguistically meaningful boundaries where a human speaker would breathe or think.
Pitch contour analysis compounds this signal: human speakers vary fundamental frequency dynamically across a sentence, with pitch rising for questions, falling for statements, and shifting subtly to convey emotion.
Text-to-speech models generate pitch contours from learned statistical averages, producing speech that sounds approximately correct on individual words but lacks the sentence-level variation that characterizes authentic communication. The result is a subtle flatness that spectrographic analysis renders unambiguous.
2. Identify Phoneme Fragmentation and Spectral Inconsistencies
Phoneme accuracy and coarticulation provide a second critical detection layer. Human speakers blend phonemes through coarticulation, where the tongue and vocal tract anticipate upcoming sounds while still producing the current one, creating fluid transitions.
Spectral consistency analysis operates at a level invisible to human hearing. When detection tools convert audio into spectrograms, synthetic speech reveals telltale artifacts: missing harmonic overtones in higher frequency bands, unnaturally sharp energy drop-offs at frequency boundaries, and periodically repeating spectral patterns that biological vocal tracts cannot physically produce.
These frequency-domain signatures persist even when synthetic speech sounds convincingly human, making them among the most reliable detection signals available.
3. Deploy Voice Biometrics to Establish Individual Speaker Baselines
Voice biometrics elevates detection from generic acoustic analysis to person-specific verification. The approach creates a voiceprint, a unique mathematical model of an individual's vocal characteristics, from clean recordings. For high-risk roles such as executives, finance directors, and IT administrators, organizations establish these baselines proactively.
When an incoming call or video conference audio purports to be from that individual, the detection engine compares the sample against the stored voiceprint. Deviations trigger alerts.
A synthetic clone of a CEO's voice might fool a human listener, but biometric comparison reveals mismatches in vocal tract length estimation, glottal pulse patterns, and the distribution of formant frequencies unique to each person's physical anatomy. These anatomical signatures are extremely difficult for current voice-cloning models to replicate accurately, provided a clean baseline exists.
4. Cross-Reference Audio with Visual Lip Movements
For video-based deepfakes, audio-visual sync analysis detects mismatches between spoken audio and visible lip movements. Even when synthetic voice and synthetic video are generated separately using the same script, subtle temporal misalignments appear: a lip closure arrives milliseconds after the corresponding plosive consonant, or mouth shapes correspond to a slightly different vowel than the one spoken.
Detection tools analyze these alignment patterns frame by frame, flagging discrepancies that indicate a lip-sync deepfake rather than an authentic recording. This modality becomes particularly important as real-time deepfake cyberattacks on live video calls become operationally feasible.
5. Account for Compression Artifacts and Cross-Language Performance Gaps
Two practical limitations degrade detection accuracy in real-world deployments. Video compression strips high-frequency spectral detail when audio passes through lossy codecs like MP3, AAC, or the compression built into platforms like Zoom and Microsoft Teams.
This is precisely the frequency range where many synthetic speech artifacts reside, causing detection tools trained on uncompressed audio to lose accuracy when applied to real-world recordings.
Most audio deepfake detection models are trained predominantly on English-language datasets. The MLAAD dataset (Müller et al., 2024–2026) was created specifically to address this gap, covering 38 languages and over 90 TTS systems across multiple architectures in its most recent versions, making it one of the most linguistically diverse anti-spoofing resources available.
Detection systems exhibit higher false-positive rates for speakers with non-Western accents and for languages underrepresented in cybersecurity training data, creating accuracy disparities that security teams must account for when deploying detection in multilingual organizations.
As synthetic speech generation tools expand their language coverage, detection systems must follow, and currently they lag behind. The same detection urgency applies to synthetic video, where face-swapping and lip-sync technologies present an equally formidable verification challenge.
Digital Forensics, Metadata, Watermarking, and OSINT Investigation
Understanding how deepfake detection tools work requires recognizing two distinct categories of non-machine-learning approaches. Proactive methods embed verifiable signals when media is generated. Reactive methods examine files already in circulation for forensic traces of manipulation.
Google DeepMind's SynthID and the C2PA standard represent the proactive front. SynthID embeds digital watermarks directly into AI-generated images, audio, video, and text, invisible to human senses yet resistant to cropping, compression, and frame-rate changes.
The C2PA standard, backed by Adobe, Microsoft, Intel, and the BBC, cryptographically signs media at origin, creating a tamper-evident chain of custody any compatible viewer can verify downstream.
Digital forensics and OSINT investigation work backward from a suspicious file, examining metadata, compression artifacts, geolocation inconsistencies, and source history to reconstruct whether manipulation occurred. Neither approach is sufficient alone: provenance infrastructure remains years from universal adoption, and post-hoc detection grows harder as generation quality improves. A layered strategy is the only defensible posture.
Digital Forensics and Metadata Analysis
Every digital media file carries invisible forensic fingerprints that betray its origin and modification history. Creation timestamps, device fingerprints, software version strings, and compression history can reveal whether media passed through a known deepfake generation pipeline.
When a video file claims iPhone 15 origin but its metadata references encoding libraries from open-source face-swap frameworks, the contradiction is immediate and actionable.
Metadata analysis becomes especially powerful at tracing editing toolchains. Adobe Photoshop and Final Cut Pro embed identifiable markers into exported files. Deepfake generation frameworks leave their own traces: specific compression artifacts, frame-rate inconsistencies, and telltale structural patterns in the file container.
Metadata can be stripped during social media uploads, and platforms routinely compress and re-encode files, discarding the original forensic evidence. This fragility means metadata analysis must never be relied upon in isolation.
Watermarking and Content Provenance
Proactive watermarking embeds an imperceptible signal into media at creation, enabling downstream verification without fragile metadata or AI classifiers. SynthID's watermark lives within the content itself, not in a metadata wrapper, and it survives transformations that strip traditional file headers.
Meta's Video Seal, developed by the FAIR team and released as open source, similarly embeds hidden provenance markers into video frames, enabling detection after re-encoding or partial editing.
The C2PA provides the open standard making these efforts interoperable, cryptographically signing capture data, edit history, and origin information into a verifiable chain that spans from camera to publication.
The critical limitation is that proactive approaches only work when generation platforms adopt them. Open-source models and malicious actors produce media with no embedded signal. Reactive detection remains essential for the foreseeable future.
OSINT Investigation Methods
Open-source intelligence (OSINT) techniques allow investigators to verify suspicious media using publicly available tools, without requiring access to original files or embedded provenance signals. The methodology is deliberately accessible: no machine learning or proprietary detection software is needed. It is within reach of journalists, fact-checkers, and security analysts in any organization.
Reverse image search traces suspicious media to its earliest known appearance online, revealing whether content predates the claimed event or has been repurposed from a different context.
Geolocation analysis compares claimed locations against visual landmarks, architectural details, and shadow directions to confirm or contradict origin claims. Shadow and reflection consistency checks expose composited scenes where light sources and physics do not align.
The Reuters Institute's April 2024 analysis of publicly accessible deepfake detection tools found that current AI detectors are easily fooled by simple techniques, such as lowering image resolution, adding blur, or building compression into the generation prompt was sufficient to bypass them.
The researchers conclude that AI detection tools can provide a signal at best, and that traditional verification and OSINT skills remain the most reliable long-term foundation for distinguishing real from manipulated content, with no single detector or signal sufficient on its own.
Detection tools flag anomalies. The employee who verifies before acting stops the cyberattack. That verification reflex does not emerge from technology alone. It is built through repeated exposure to realistic cyber threats in a controlled environment, the form of cybersecurity awareness training that transforms forensic awareness into an organizational instinct.
How Humans Can Manually Spot Deepfakes
Manually spotting a deepfake requires systematically checking visual and audio indicators that generation algorithms cannot yet reproduce consistently. Starting with the face, skin texture, blinking, and lip-sync, then expanding to lighting physics, hair boundaries, and hand rendering, and listening for vocal artifacts that reveal synthetic audio, gives observers a structured framework.
Even trained observers miss high-quality deepfakes far more often than they catch them. A 2025 iProov study of 2,000 participants across the U.S. and UK found that only 0.1% could correctly distinguish all real from deepfake stimuli across images and video, and participants were 36% less likely to identify a synthetic video than a synthetic image.
Treat these manual checks as a rapid triage layer. They complement automated detection tools and do not replace them.
1. Check Skin Texture and Facial Uniformity
AI-generated faces often lack the natural imperfections of real human skin. Patches that appear overly smooth, waxy, or plastic-like, as though an airbrush has been applied uniformly across the entire face, are a telling sign. Real skin contains pores, fine lines, freckles, and subtle asymmetries that deepfake algorithms tend to homogenize into a complexion that looks rendered rather than photographed.
Pay particular attention to the forehead, cheeks, and the area around the nose, where texture variation is most pronounced in authentic video. A face that looks like it belongs in a video game cutscene rather than a conference call is a significant red flag.
2. Count Blinking Cadence
Blinking is a physiological rhythm that deepfake models frequently mishandle. Watching the subject for 10 seconds and counting blinks provides a useful signal: a normal human blinks roughly 15 to 20 times per minute, meaning 2 to 3 blinks should appear in that window.
Early deepfake models produced videos with no blinking at all because cybersecurity training datasets contained far more images of eyes open than closed. Modern generators have improved, but they still produce blinking that is either absent or mechanically regular. Real human blinking is irregular and context-driven; a metronome-like pattern is a warning sign.
3. Watch Lip-Sync Alignment
Mouth movements that do not match spoken audio are the most reliable manual indicator of a deepfake. Focusing on the lips and jaw during speech and checking whether they form the correct shapes for the sounds being produced reveals manipulation.
A 2024 study published in Nature Communications (Groh et al.) found that human discernment of deepfakes relies more heavily on audio-visual cues than on the content of speech itself, participants were significantly more accurate when they could hear and see the video than when reviewing text transcripts alone.
Research in deepfake detection engineering separately documents that synthesis failures concentrate at phonemes requiring precise articulatory positioning, particularly labials (/p/, /b/, /m/), labiodentals (/f/, /v/), and alveolars (/t/, /s/), where lip and teeth geometry must match the audio with high precision.
A slight lag, a mouth shape that does not close fully on an "m" sound, or jaw movement that continues after speech stops are all evidence of manipulation.
4. Analyze Shadow and Lighting Physics
Light sources in a real environment obey consistent physics. In a deepfake, shadows often tell a different story than the rest of the scene. Checking whether shadows under the nose, chin, and brow cast in the same direction as shadows in the background reveals compositing.
A face illuminated from the left while the wall behind shows light from above signals a composite. Specular highlights on the eyes also provide signal: real eyes reflect a single coherent light source, while deepfake eyes often show two different catchlights or none at all, because the compositing process fails to reconcile the lighting environment.
5. Inspect Hair and Facial Boundaries
The transition zone where the face meets the background is a consistent failure point for deepfake generation. Blurring, flickering, or a subtle halo artifact along the hairline and jawline are reliable indicators. Individual strands of hair may warp, disappear, or merge into a solid block during head movement.
Ears are another tell. Deepfake models frequently distort ear shape, merge the earlobe into the jaw, or fail to render the complex folds of the pinna correctly. If the edges of the face appear to shimmer or shift independently from the background, the video has likely been manipulated.
6. Study Hand and Finger Rendering
AI image and video generators remain notoriously unreliable at anatomically correct hands. Counting the fingers on each hand, checking for extras that are fused or missing, and watching for fingers curling into impossible positions or joints bending at unnatural angles are all practical checks.
Even with rapid model improvements, hands remain a weak point for generative models. If a subject is gesturing and the hands look structurally wrong, that is strong evidence of a synthetic video.
7. Listen for Audio Red Flags
Audio deepfakes, particularly those generated by text-to-speech engines, often carry detectable artifacts. A metallic or buzzy quality that real voices do not produce is one marker; flat intonation is another, as synthetic voices frequently lack the natural pitch variation, emotional emphasis, and micro-pauses that characterize human speech.
Unnatural pauses that occur mid-word rather than at clause boundaries are a strong indicator. Inconsistencies in background noise, a sudden drop into silence between words, or room tone that changes character from sentence to sentence also signal synthetic generation.
These manual techniques are a practical first line of defense. Deepfake generation quality improves every quarter, and as models close the gap on blinking, skin texture, and lip-sync, even trained humans will increasingly struggle to spot high-quality fakes by eye alone.
Manual detection is a skill worth building, and it is most effective when paired with simulated deepfake exposure through deepfake phishing simulations that build recognition under realistic conditions before a live cyberattack lands.
Why Deepfake Detection Tools Fail in Real-World Deployments
How deepfake detection tools work in real-world deployments tells a starkly different story than controlled benchmark results.
State-of-the-art automated deepfake detection systems experience 45-50% accuracy drops when confronted with real-world deepfakes compared to laboratory conditions, according to research cited by the World Economic Forum's July 2025 analysis of AI detection challenges, with the underlying data drawn from Washington Post testing of detection tools during the 2024 election cycle.

The Lab-to-Field Accuracy Gap
Most detection models train on curated datasets like FaceForensics++ or Celeb-DF, collections built with specific generators, consistent resolutions, and controlled lighting. In-the-wild content arrives through unknown generators, compressed at variable bitrates, captured under unpredictable illumination, and viewed from non-frontal angles.
When a model trained exclusively on high-resolution frontal-face laboratory footage encounters a compressed smartphone video shot in a dim room, its learned forensic patterns dissolve into noise.
The architecture that performed brilliantly on the benchmark fails under operational conditions because the statistical distribution of real-world media shares almost nothing with the cybersecurity awareness training data.
Video Compression: The Silent Killer of Detection
Lossy video codecs, H.264 and H.265, the standards underpinning Zoom, YouTube, and virtually every video platform, systematically destroy the artifacts that detectors depend on.
Detection models learn to identify subtle high-frequency pixel patterns: unnatural blinking cadences, inconsistent skin texture micro-details, and boundary artifacts around face-swapped regions. Compression algorithms are designed to discard precisely these high-frequency signals to reduce file size.
By the time a deepfake passes through a messaging app or conferencing tool, the compression pipeline has stripped away the forensic evidence. A detector that correctly flagged the original file misses the compressed version entirely, and nearly every video an organization encounters has been compressed at least once.
Demographic Bias and Its Legal Consequences
Detection tools consistently produce higher false positive rates on darker skin tones, older faces, and non-Western facial features, a direct consequence of training datasets that skew white, young, and male.
University at Buffalo researchers documented that leading algorithms misclassified real faces of Black men as fake 39.1% of the time, compared to just 15.6% for white women. "A detection algorithm's accuracy should be statistically independent from factors like race, but obviously many existing algorithms, including our own, inherit a bias," said Siwei Lyu, PhD, co-director of the UB Center for Information Integrity.
The study, presented at WACV 2024 and supported by DARPA, uncovered error rate disparities across racial groups reaching 10.7%. These biases create tangible legal exposure: platforms that automatically flag content as synthetic risk wrongly suppressing authentic speech from marginalized communities, and in journalism, legal proceedings, and content moderation, a false positive is a credibility-destroying event with potential defamation and discrimination liability.
The Adversarial Arms Race
Detection models face direct adversarial cyberattacks, imperceptible perturbations injected into media that cause misclassification while remaining invisible to human viewers. Cyberattackers can add crafted noise patterns to deepfake outputs that deliberately blind detectors. More fundamentally, generative models evolve faster than detection models can retrain.
Each new technique, diffusion-based synthesis, neural radiance fields, real-time face reenactment, exploits vulnerabilities existing detectors were never designed to catch.
NIST's Adversarial Machine Learning taxonomy (AI 100-2, updated 2025) documents evasion attacks as a core attack category. In this class, adversaries craft inputs specifically designed to bypass ML detection systems, creating a dynamic where cyberattackers probe and adapt to detection algorithms while defenders must update their models reactively.
False Negatives vs. False Positives: Two Different Disasters
In security contexts, false negatives, missed deepfakes, represent the most dangerous failure mode.
False positives carry their own destructive weight: when authentic content is flagged as synthetic, the damage extends into reputational harm, wrongful accusation, and erosion of trust in legitimate media.
For newsrooms verifying user-submitted footage or courts evaluating digital evidence, a false positive can destroy credibility or undermine proceedings.
This dual failure spectrum means no detection-only strategy succeeds. Organizations must pair tools with out-of-band verification protocols that function independently of algorithmic judgment. Realistic multi-channel deepfake phishing simulations that train employees to verify identity through secondary channels create resilience that no detection algorithm can match.
The Deepfake Detection Tools and Market Landscape
Understanding how deepfake detection tools work has attracted significant commercial investment in the tools and platforms designed to bridge the lab-to-field gap.
A March 2026 market analysis commissioned by the UK Department for Science, Innovation and Technology and conducted by digital advisory firm PUBLIC Group International mapped 59 deepfake detection providers globally as of 2025. The analysis found 23 US-headquartered firms and 7 from the UK leading the field, with rapid market growth documented since 2017. Most providers remain in early-stage funding, and the market itself is described as nascent.
Commercial detection platforms prioritize production-ready accuracy and real-time throughput, while open-source models offer transparency and customizability at a meaningful accuracy cost.
Intel's FakeCatcher uses photoplethysmography to analyze subtle blood flow signals in video pixels, detecting the color changes caused by heartbeats that deepfake generation pipelines cannot replicate.
BBC testing in July 2023 found the system performed well on deepfake identification but generated false positives on genuine videos, particularly when pixelated, and does not analyze audio, limitations Intel acknowledges as areas for future development.
Open-source models built on benchmarks like FaceForensics++ deliver 61 to 69% accuracy using freely available architectures such as CNN-LSTM hybrids, trailing commercial claims by 20 to 30 percentage points but costing nothing to deploy and allowing full inspection of detection logic.
The practical gap between commercial and open-source performance shifts depending on deployment conditions, and neither category performs well on compressed, low-resolution, or adversarially altered media.

Commercial Detection Tools: Performance and Market Position
These accuracy figures carry an important caveat highlighted by the UK Government's DSIT research. Vendor-published benchmarks consistently overstate operational reliability, because they rely on controlled datasets rather than the compressed, demographically diverse, adversarially varied media that enterprise environments actually produce.
Accuracy rates typically drop by 10 to 20% when tools are redeployed in real-world conditions with representative datasets compared to controlled lab environments. Of the 59 providers mapped globally, 83% are micro or small enterprises, and 23 are US-headquartered.
The market remains dominated by pre-seed and seed-stage providers, with very few dedicated deepfake detection providers having reached significant venture funding milestones, reflecting the market's early-stage maturity despite rapid growth.
Open-Source Detection Models: Transparency at a Cost
The FaceForensics++ dataset, a widely used benchmark for deepfake detection research, evaluates CNN-LSTM architectures across four manipulation types: Deepfakes, Face2Face, FaceSwap, and Neural Textures.
A 2026 benchmark study published in Discover Applied Sciences (Jugade et al., Symbiosis Institute of Technology, Pune) compared four CNN-LSTM hybrid architectures — ResNeXt50, XceptionNet, MobileNet, and VGG16, on the FaceForensics++ dataset under controlled conditions.
VGG16-LSTM achieved the highest validation accuracy and sensitivity among the four tested architectures, with XceptionNet-LSTM and MobileNet-LSTM performing comparably. Results reflect controlled benchmark conditions on a GAN-era dataset and should not be generalized as real-world deployment accuracy.
The trade-off is significant. Open-source models allow security teams to inspect detection logic, audit training data provenance, and customize models for their specific cyber threat profiles. Commercial black-box APIs typically restrict these capabilities. For organizations with in-house machine learning expertise and GPU infrastructure, these tools provide a cost-effective starting point, though they require continuous retraining as generative AI techniques evolve.
Computational Resource Requirements
Running deepfake detection at enterprise scale demands significant computational investment. Real-time video detection requires NVIDIA A100 or H100-class GPUs, each H100 costing approximately $30,000, to maintain sub-second inference latency on streaming video.
Organizations analyzing video conference feeds in real time need at least one dedicated GPU per concurrent stream. For batch processing of archived media, storage becomes the primary constraint: a single hour of 1080p video at 30 frames per second generates roughly 108,000 frames for analysis, and enterprise video archives routinely exceed terabytes.
The UK Government's market analysis identifies these high technical costs and resource constraints as a primary barrier to adoption, particularly for smaller organizations evaluating detection tools for the first time.
What Testing Protocols Should Organizations Use Before Deploying Detection Tools?
Testing a deepfake detection tool against the wrong dataset produces misleading confidence. Organizations must use representative datasets that match their actual cyber threat profile, not just academic benchmarks like FaceForensics++ or Celeb-DF.
If an organization faces video conference impersonation cyber threats, testing with synthetic video conference footage is essential. If audio deepfakes from cloned executive voices are the primary concern, testing with voice samples that approximate leadership speech patterns is the correct approach.
Measuring both false positive and false negative rates is equally critical: a hypothetical tool that flags a high proportion of deepfakes but mislabels a significant percentage of authentic media as fake will generate operational chaos in any production environment.
Testing performance on compressed and low-resolution media, which represents the majority of real-world deepfake content distributed through messaging apps and social platforms, and running adversarial robustness tests using gradient-based cyberattacks and common evasion techniques, will reveal how easily a tool can be bypassed by a moderately sophisticated adversary.
What Questions Should Buyers Ask Before Purchasing a Detection Tool?
Five questions separate informed procurement from vendor marketing.
First: what cybersecurity training data was used, and does it include deepfakes generated by the latest diffusion-based and GAN architectures the organization is most likely to encounter? A model trained exclusively on 2019-era FaceForensics++ data will fail against current-generation AI-generated media.
Second: what are the false positive rates across demographic groups, with specific disaggregated data rather than aggregate averages?
Third: how often are models updated, given that monthly retraining cycles are now a baseline expectation given the velocity of generative AI advancement?
Fourth: can the tool explain its decisions? A confidence score without interpretability leaves security analysts unable to investigate borderline cases or defend findings during incident response. Tools that provide activation maps, artifact localization, or other explainability features address this gap.
Fifth: does the tool support the organization's languages and communication channels? Audio detection models trained on English speech patterns often degrade significantly on accented or non-English audio, and video detection tools calibrated for high-quality studio lighting can fail on the compressed, variable-lit video that dominates corporate conferencing platforms.
Market Barriers Slowing Deepfake Detection Adoption
The deepfake detection market faces five structural barriers that slow enterprise adoption despite escalating cyber threats. Regulatory uncertainty tops the list: the evolving international online safety regulatory landscape creates ambiguity for both suppliers and customers, with platforms taking a reactive approach to deepfake governance.
High upfront costs compound this problem. Organizations that have not experienced a deepfake incident often perceive low ROI, making budget justification difficult. Deloitte's Center for Financial Services projects generative AI could drive U.S. fraud losses to as much as $40 billion by 2027 under its high-end scenario, up from $12.3 billion in 2023.
Limited cybersecurity training data for niche use cases creates a self-reinforcing problem. Models trained predominantly on celebrity and public-figure deepfakes underperform on the corporate executive impersonation scenarios that enterprises actually face.
Inconsistent accuracy benchmarks across the industry prevent meaningful vendor comparison, as providers test against different datasets using different metrics and report only favorable results.
Until these barriers resolve, organizations are best served by combining detection tools with deepfake-aware security awareness training that prepares employees to recognize synthetic media even when automated detection misses it.
Real-World Deepfake Harms, Sector Applications, and the Regulatory Landscape
Deepfake-enabled fraud escalated into a multibillion-dollar cyber threat in under two years. The damage now spans far beyond isolated scams, touching financial markets, democratic institutions, biometric security infrastructure, and personal privacy at scale.
Financial Fraud and Business Email Compromise
The engineering and design firm Arup lost $25 million in early 2024 when a finance worker in its Hong Kong office joined a multi-person video conference where every attendee, including the company's CFO, was a deepfake.
The employee transferred the funds following instructions from people who never existed. This cyberattack class, known as business email compromise (BEC) supercharged by cloned executive voices and faces, is no longer theoretical.
The FBI IC3 Annual Report for 2025 documented over $3 billion in BEC losses that year alone. AI-generated voice and video impersonation has removed the final friction points that once made these scams detectable.
Cyberattackers now combine spoofed emails with vishing calls that sound exactly like the CFO, collapsing verification instincts built over decades of cybersecurity awareness training.
Identity Theft and KYC Bypass
Biometric verification was supposed to solve identity fraud. Deepfakes have inverted that equation. Criminals now feed synthetic video through KYC liveness checks that were originally designed to stop static photo spoofing, and even trained compliance staff are outmatched by the quality of current generation tools.
Disinformation and Political Interference
The 2024 global election cycle stress-tested democratic institutions against AI-generated disinformation. Deepfake audio of political candidates, fabricated video of election officials, and synthetic news segments flooded social platforms during critical voting windows.
The damage compounds even when deepfakes are debunked: the mere existence of convincing fakes erodes public trust in authentic media, creating what researchers call the "liar's dividend," where real evidence is dismissed as fabricated.
The UK Department for Science, Innovation and Technology's 2026 Deepfake Detection Technology report identifies misinformation and disinformation detection, including political deception and narrative manipulation, as one of seven primary use cases driving public-sector deepfake detection investment, alongside fraud prevention, identity verification, and national security applications.
Corporate Impersonation and Synthetic Employees
A disturbing new cyberattack vector has emerged: deepfake employees infiltrating remote hiring pipelines. In 2024 and 2025, multiple technology companies discovered they had hired individuals who used real-time face-swapping software during video interviews, creating synthetic candidates that passed live screening.
Once inside, these impostors gained access to internal systems and customer data. The same technology enables cyberattackers to impersonate IT support staff on video calls, tricking employees into credential resets or MFA bypass. Corporate security teams now face a cyber threat surface where neither a face on a screen nor a voice on a phone call can be trusted at face value.
Security teams are closing this gap by running deepfake phishing simulations that incorporate video and voice cloning scenarios, giving employees structured exposure to synthetic impersonation before they encounter it in the wild.
Non-Consensual Synthetic Media
The scale of non-consensual deepfake creation dwarfs all other categories. As early as 2019, Deeptrace's The State of Deepfakes report found that 96% of online deepfake videos were pornographic and that all of that pornographic content featured women, virtually all without consent.
That figure has since risen: a 2023 report by Security Heroes found 98% of deepfake videos were pornographic and 99% of victims were women, as the total volume has exploded.
The harm extends from individual psychological trauma to systemic gender-based violence. Regulators in the UK, EU, and multiple US states have made non-consensual synthetic intimate imagery a specific criminal offense.
The UK's Online Safety Act, EU AI Act, and the US TAKE IT DOWN Act each create platform obligations and criminal liability frameworks addressing this category directly.
Seven Sector Use Cases for Deepfake Detection
The UK Government's 2026 Deepfake Detection Technology report mapped seven primary use cases across public and private sectors, each with distinct technical requirements:
- Law enforcement forensics demands forensic-grade detection admissible in court, where chain-of-custody and explainability are non-negotiable;
- Border control and identity verification requires real-time liveness detection capable of processing millions of border crossings without adding friction;
- Platform content moderation needs scalable, automated classification that can handle billions of uploads daily across major social platforms;
- Journalism and media verification requires tools that produce fast, explainable authenticity scores before publication deadlines;
- Enterprise security operations needs detection integrated into existing communication channels: email, video conferencing, and messaging;
- Financial services fraud prevention demands sub-second verdicts during live transactions without false positives that block legitimate customers;
- National security and intelligence requires the highest accuracy threshold, where a single missed detection could enable catastrophic intelligence deception.
The Regulatory Landscape Driving Detection Adoption
Regulation has shifted from voluntary guidance to mandatory obligation across three major jurisdictions in under two years. The EU AI Act, which entered into force in August 2024, imposes Article 50 transparency requirements mandating that AI-generated content be labeled, with deepfake-specific provisions that take full effect in August 2026.
The UK's Online Safety Act already requires platforms to address illegal harms regardless of whether content is real or AI-generated, with Ofcom actively considering AI-specific guidance.
In the US, California enacted landmark deepfake legislation in 2024 targeting election interference and non-consensual imagery, Texas criminalized political deepfakes within 30 days of an election, and New York updated its General Business Law to require disclosure of AI-generated content.
Regulatory requirements are now a primary market driver alongside GenAI advancement and national security cyber threats, pushing organizations from voluntary detection toward compliance-mandated deployment.
How Security Awareness Training Strengthens Deepfake Defense
Detection tools identify synthetic media after it reaches an organization. Employees encounter deepfakes in real time: answering a vishing call from a cloned executive voice or joining a video conference where every participant is AI-generated.
How deepfake detection tools work reveals their core limitation: they operate on media that has already been captured and submitted for analysis, not on live interactions where employees make trust decisions in seconds. Security awareness training closes this gap by teaching employees to recognize behavioral red flags that no detection algorithm can flag.

Why Do Detection Tools Alone Fall Short Against Live Deepfake Attacks?
Deepfake detection tools scan for visual artifacts, inconsistent lighting, and audio-frequency anomalies using machine learning classifiers trained on known synthetic content. A live video call, a real-time phone conversation, or an AI-generated message arriving through a sanctioned communication channel never passes through that screening layer before an employee acts on it. The cyberattack surface is the human decision point.
This is a structural mismatch between how detection tools operate and how deepfake-powered social engineering actually unfolds. As a 2026 arXiv analysis of synthetic trust attacks frames it, the critical failure point is not whether a deepfake is technically detectable, it is whether the victim's decision architecture holds under manufactured authority, contextual plausibility, and compressed verification time. Even technically sophisticated targets fail when the social engineering context is sufficiently constructed.
When a CFO's cloned voice instructs a finance team member to wire funds before the quarter closes, no detection software intercepts that call. Whether that employee has been trained through security awareness training to recognize the cyberattack determines the outcome.
What Behavioral Red Flags Does Deepfake-Aware Training Teach Employees to Spot?
Deepfake-aware security awareness training shifts employee focus from content authentication to context evaluation. Detection tools handle the former; only a human can perform the latter. The most reliable indicators of a deepfake-driven cyberattack are behavioral: a request arriving through an unexpected channel, pressure to bypass standard approval workflows, or a communication that pairs synthetic media with manufactured urgency to short-circuit rational review.
The Ferrari incident from July 2024 demonstrates why behavioral verification works where artifact detection cannot. When cyberattackers cloned CEO Benedetto Vigna's voice to push a fraudulent transaction, the targeted executive detected the deception by asking an unscripted personal question the cyberattacker could not answer.
The executive asked for the title of a book Vigna had recommended days earlier. The scammer hung up. MIT Sloan Management Review documented how that single verification reflex prevented what could have been a major financial loss.
Security awareness training that rehearses these verification protocols builds a human defense layer that operates independently of whether the synthetic media itself is detectable. Pre-agreed code words and out-of-band confirmation for any financial request become instinctive checks rather than afterthoughts.
How Does Multi-Channel Phishing Simulation Build the Decision-Making Reflex?
Reading about deepfake cyberattacks does not prepare employees to resist one under pressure. Multi-channel phishing simulation builds the muscle memory that matches real cyberattack conditions.
Each phishing simulation cycle, whether a controlled deepfake vishing call, a smishing message, or a video impersonation scenario, strengthens the cognitive pathway between suspicion and verification. The default trust response that deepfake cyberattackers exploit gets replaced by an automatic verification instinct.
Organizations that layer detection tools with deepfake-aware security awareness training create a defense-in-depth human risk posture. Tools catch known synthetic patterns; trained employees catch what the tools miss.
The metric that proves cybersecurity awareness training effectiveness is behavioral change measured through reduced susceptibility across phishing simulation cycles. Detection accuracy percentages describe tool performance, but organizational readiness is measured by how employees respond when a deepfake cyberattack reaches the decision point.
Phishing simulations that span email, voice, and video give security leaders the data to answer the question that matters most: do employees make safer decisions when confronted with a deepfake cyberattack?
Best Practices for a Multi-Layered Deepfake Defense Strategy
How deepfake detection tools work is only one component of what makes defense resilient: the full combination includes proactive verification technology, rigorously rehearsed process, and human judgment trained specifically for AI-generated deception.
1. Detection and Verification: Combining Technology with Human Judgment
Every deepfake defense strategy needs two complementary layers working in tandem. Automated detection tools analyze media after the fact, flagging artifacts, inconsistencies in lighting and facial movement, and audio-visual synchronization errors that human observers miss.
Organizations handling high-risk communications should implement incoming content provenance verification using the C2PA standard, which cryptographically binds metadata to media at the point of creation so recipients can validate authenticity before trusting what they see.
For outbound executive content, watermarking creates a verifiable chain that makes impersonation harder. The second layer is mandatory human verification: establishing out-of-band confirmation channels for any voice or video communication requesting fund transfers or sensitive data, using a separate messaging app, a pre-agreed code phrase, or a callback to a known number.
The Ferrari deepfake cyberattack attempt in 2024 mimicked the CEO's southern Italian accent perfectly but collapsed when the recipient asked a personal question only the real executive could answer. That challenge-response instinct, formalized as policy, stops the cyberattack.
When it comes to protecting our money, we ought to expect and appreciate a little friction," said Michael S. Barr, Vice Chair for Supervision of the Federal Reserve, in his April 2025 speech "Deepfakes and the AI Arms Race in Bank Cybersecurity", delivered at the Federal Reserve Bank of New York.
2. Cybersecurity Awareness Training and Phishing Simulation: Building Deepfake-Ready Employees
Annual compliance cybersecurity awareness training does not prepare anyone to resist a synthetic video of a CFO demanding an urgent wire transfer. Organizations need quarterly or continuous microlearning that includes deepfake vishing and video phishing simulation. Employees must encounter a cloned executive voice or face in a controlled environment before facing one in the wild.
Realistic phishing simulations that span email, voice, SMS, and video close that gap. Before purchasing any detection tool, testing it against media that matches the organization's actual communications environment is essential: the resolutions, compression artifacts, languages, and demographics teams encounter daily.
Vendor-provided benchmarks trained on clean, high-resolution datasets reveal nothing about tool performance on the compressed Zoom recordings and mobile phone footage that define real-world deepfake cyber threats. The gap between lab performance and production accuracy is often wide enough to render a tool operationally useless.
3. Policy and Incident Response Playbooks
A deepfake incident confirmed at 2 p.m. should not trigger ad hoc decision-making. Defining escalation paths, forensic evidence preservation procedures, and pre-written communication templates before a cyberattack occurs ensures a coordinated response.
The playbook must specify who declares an incident, how affected accounts are isolated, what evidence the security team preserves for law enforcement, and how internal and external stakeholders are notified. Rehearsing it at least twice annually keeps the response muscle memory current.
Aligning defense investment with actual risk concentration is equally important. Deepfake cyberattackers target executives, finance teams, and HR because those roles authorize payments and hold sensitive data.
Using OSINT exposure monitoring to understand what cyberattackers can discover about these individuals reveals the true attack surface: conference talk recordings, social media videos, and podcast appearances all become source material for voice and face cloning.
A CEO with 40 hours of clean, close-up video available online presents a substantially larger attack surface for voice and face cloning than one with five minutes of compressed, low-resolution footage. Reducing that exposure surface is one of the highest-ROI investments available.
4. Monitoring Emerging Techniques
Liveness detection, which verifies real-time presence rather than analyzing recorded media, is moving from research to deployment. These systems look for involuntary micro-movements, pulse-driven skin color changes, and interactive responses that pre-recorded deepfakes cannot replicate.
Challenge-response protocols add a behavioral layer by requiring a video call participant to perform a specific action on demand, such as turning their head to a specified angle or reading a dynamically generated phrase.
Blockchain-based media provenance registries are emerging as a third path. Unlike C2PA, which binds credentials to individual files, these systems create immutable public ledgers of authenticated media that any party can verify.
None of these techniques is mature enough to deploy alone. Tracking each one and layering the best-fit approaches into an existing defense stack keeps an organization ahead of cyberattackers who are already automating their own toolchains.
Key Takeaways: How Deepfake Detection Tools Work
- How deepfake detection tools work depends on architecture: CNNs catch frame-level artifacts, LSTMs flag temporal inconsistencies, and Vision Transformers generalize better across unseen manipulation types;
- How deepfake detection tools work in production routinely falls short of lab benchmarks, with real-world accuracy collapsing far below controlled test conditions due to video compression, adversarial evasion, and distribution mismatch;
- Multimodal detection systems fuse visual, audio, and metadata signals to close the gaps that any single modality leaves open;
- Demographic bias in detection models creates higher false positive rates for underrepresented groups, generating both legal exposure and operational unreliability;
- Proactive watermarking standards such as C2PA and SynthID complement reactive detection by embedding verifiable provenance at the point of media creation;
- Security awareness training builds the behavioral verification reflex that no deepfake detection algorithm can replicate, particularly against live cyberattacks on video calls and phone lines;
- A layered defense combines deepfake detection tools with out-of-band verification protocols, deepfake phishing simulations, and incident response playbooks rehearsed before a cyberattack occurs.
How Adaptive Security Closes the Gaps That Deepfake Detection Tools Cannot
Deepfake detection tools address what can be analyzed after capture. The more consequential gap is the live decision-making moment: a finance team member receiving a vishing call from a cloned executive voice, a hiring manager on a video interview with a synthetic candidate, or a security analyst facing a real-time impersonation cyberattack through a sanctioned channel. Adaptive Security's multi-channel security awareness training is built specifically for this gap.
Through realistic deepfake phishing simulations spanning voice, video, SMS, and email, employees develop the instinctive verification reflexes that no algorithm can supply. Each phishing simulation cycle reinforces behavioral change, turning the verification reflex from a policy reminder into an automatic response that functions even under pressure and time constraints.
Explore how Adaptive Security's deepfake phishing simulations and cybersecurity awareness training build the human defense layer that keeps organizations resilient as synthetic media cyber threats continue to evolve.
Request a personalized demonstration to see how deepfake-specific security awareness training works for organizations across all scales and risk profiles.
How Deepfake Detection Tools Work FAQs
Can Deepfake Detection Tools Detect All Deepfakes?
Even the most advanced commercial tools miss a significant percentage of deepfakes in real-world conditions. Independent testing consistently reveals that tools achieving high accuracy in controlled lab settings deliver 50–65% accuracy in the wild, a collapse documented across multiple analyses, driven by compression artifacts, novel generation techniques, and adversarial adaptation.
Detection gaps stem from video compression stripping away the high-frequency artifacts detectors rely on, novel generation techniques the cybersecurity training data never captured, and adversarial manipulation designed to evade classifiers.
No single tool catches every deepfake, and false negatives remain the most dangerous failure mode in security contexts. Detection tools must be layered with human verification protocols and security awareness training to close the gaps that automated systems alone cannot cover.
How Many Deepfake Detection Providers Exist Globally?
As of 2026, the UK Government has identified 59 deepfake detection providers operating globally, with 23 headquartered in the United States.
The UK Department for Science, Innovation and Technology market report covers solutions spanning video, audio, and image-based detection. These providers range from large technology firms offering integrated platforms to specialized startups focused exclusively on deepfake detection.
The landscape includes both commercial API-based services and open-source tools maintained by academic institutions. The market remains fragmented, with inconsistent benchmarking standards across vendors and no universally accepted certification framework for evaluating detection accuracy across different deepfake types, compression levels, and demographic groups.
How Much Does Deepfake Detection Software Cost?
Deepfake detection software pricing varies substantially by deployment model, scale, and vendor. Most commercial providers do not publish standard pricing.
Enterprise deployments typically operate on annual licensing or per-API-call models, with costs scaling alongside analysis volume. On-premises installations carry additional infrastructure expenses: real-time video detection at scale frequently requires NVIDIA A100 or H100-class GPU clusters.
Open-source alternatives such as models built on FaceForensics++ benchmarks are free to use but deliver meaningfully lower accuracy, typically 61–69% compared to commercial tools, and require in-house machine learning expertise to deploy and maintain.
Organizations evaluating tools should budget for both software licensing and the computational infrastructure needed to run detection at production throughput, particularly for video analysis workloads where processing demands are highest.
What Is the Difference Between Deepfake Detection and Deepfake Prevention?
Deepfake detection identifies synthetic media after it has been created and distributed. It is a reactive approach that analyzes existing images, videos, and audio for generation artifacts and inconsistencies. Deepfake prevention aims to stop synthetic media from being credibly attributed to a real person in the first place.
Prevention techniques include proactive watermarking at content creation, such as Google SynthID and the C2PA provenance standard, which embed verifiable signals into genuine media so that alterations become detectable downstream.
Prevention also encompasses limiting the publicly available video and audio footage cyberattackers scrape to train voice clones and face-swap models. The two approaches are complementary: detection catches what slips through, and prevention reduces the volume of credible deepfakes that need to be caught.
Are Deepfake Detection Tools Required by Law or Regulation?
The European Union's AI Act, which entered into force on August 1, 2024 and applies progressively through 2027, requires providers of AI systems generating synthetic audio, image, video, or text to mark outputs as AI-generated in machine-readable format, a transparency labeling obligation that creates downstream demand for detection and verification capabilities.
In the United States, states including California, Texas, and New York have enacted deepfake-specific laws focused on election integrity and non-consensual intimate imagery. California's AI Transparency Act requires covered providers to offer free detection tools.
The UK's Online Safety Act imposes platform obligations that indirectly compel content verification. No jurisdiction yet mandates that private organizations deploy deepfake detection tools, but the regulatory trajectory points toward mandatory detection for high-risk sectors such as financial services and identity verification, where synthetic media directly threatens KYC and anti-fraud compliance.
Even the strongest regulatory mandates cannot substitute for employees who are trained through security awareness training to recognize and question suspicious AI-generated communications before they trigger a compliance failure.

As experts in cybersecurity insights and AI threat analysis, the Adaptive Security Team is sharing its expertise with organizations.
Contents